checkpoint 失败一般都和反压相结合。导致 checkpoint 失败的原因有两个:
1. 数据流动缓慢,checckpoint 执行时间过长。
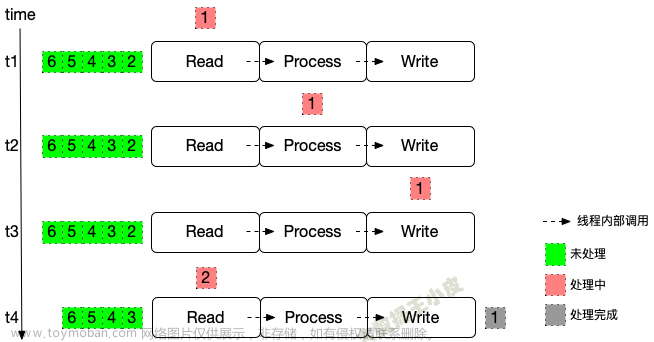
我们知道, Flink checkpoint 机制是基于 barrier 的, 在数据处理过程中, barrier 也需要像普通数据一样,在 buffer 中排队,等待被处理。当 buffer 较大或者数据处理较慢时,barrier 需要很久才能够到达算子,触发 checkpoint。尤其是当存在反压时,barrier 需要在 buffer 中流动数个小时,从而导致 checkpoint 执行时间过长,超过了 timeout 还没有完成,从而导致失败。
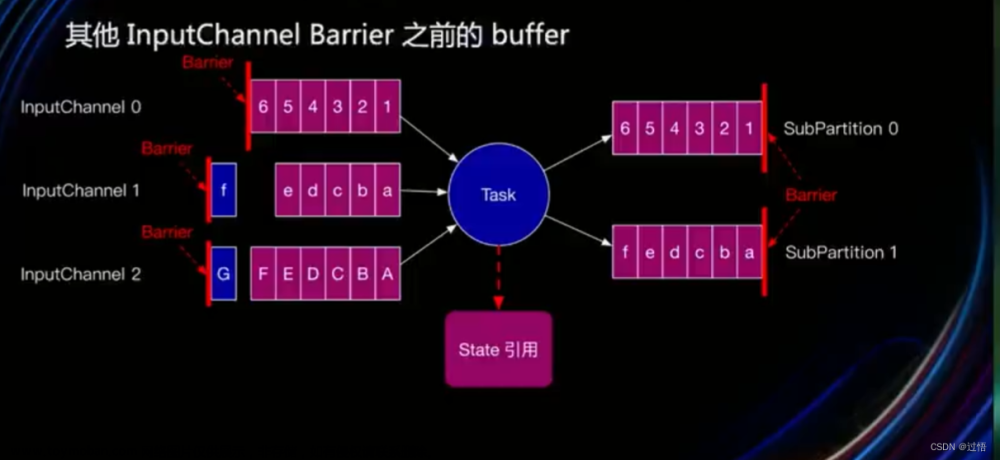
当算子需要 barrier 对齐时,如果一个输入的 barrier 已经到达,那么该输入的 barrier 后面的数据会被阻塞住,不能被处理,需要等到其他输入 barrier 到达之后,才能继续处理。在 barrier 对齐过程中,其他输入数据处理都要暂停,将严重导致应用实时性,从而让 checkpoint 执行时间过长,超过了 timeout 还没有完成, 导致执行失败。
2. 状态数据过大。
当状态数据过大,会影响每次 checkpoint 的时间,并且在 chackpoint 时 IO 压力也会很大,执行时间过长,导致超时还没有执行成功,从而导致执行失败。
3.解决思路如下
首先是对于数据流动缓慢 解决思路是:
-
让 buffer 中的数据变少
-
让 barrier 能跳过 buffer 中存储的数据。
这对应社区提出的 FLIP-183 Dynamic buffer size adjustment ,其解决思路是只缓存配置时间内可以处理的数据量,这可以很好的控制 checkpoint。
对于 barrier 对齐问题。社区提出 FLIP-76 Unaligned Checkpoint。其解决思路是 对于实时性要求很好,但数据重复性要求低的,可采用 barrier 不对齐模式,当还有其他流的 barrier 还没到达时,为了不影响性能,不用理会,直接处理 barrier 之后的数据。等到所有流的 barrier 的都到达后,就可以对该 Operator 做 CheckPoint 了。
对于 状态数据过大问题:
FLIP-158 提出通用的增量快照方案,其核心思想是基于 state changelog, changelog 能够细粒度地记录状态数据的变化。具体描述如下:
-
有状态算子除了将状态变化写入状态后端外,再写一份到预写日志中。
-
预写日志上传到持久化存储后,operator 确认 checkpoint 完成。
-
独立于 checkpoint 之外,state table 周期性上传,这些上传到持久存储中的数据被成为物化状态。文章来源:https://www.toymoban.com/news/detail-805883.html
-
state stable 上传后,之前部分预写日志就没用了,可以被裁剪。文章来源地址https://www.toymoban.com/news/detail-805883.html
到了这里,关于Flink的checkpoint遇到过什么问题,什么原因导致的的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!