随着云计算、大数据、AI的发展和普及,各行各业的业务场景日益复杂,数据呈现出大规模、多样性的特点,企业对数据仓库的需求也进一步拓展至对多元化数据实时处理的场景。
数据湖是多元数据存储与使用的便捷选择,而云原生具有数据资产统一、基础资源成本低、高性能计算体验升级等优势,是数据湖未来部署的重要形态。湖仓一体架构结合了数据仓库和数据湖的性能优势,在成本、灵活性、事务一致性、多元数据分析等方面具备显著的优势,可以为企业提供高效、兼容、低成本的数据存储和管理解决方案,帮助企业更好地实现数据驱动决策和业务创新。
在这次的直播中,我们介绍了HashData对湖仓一体方案的思考,并对Hive数据同步进行详细讲解和演示。以下内容根据直播文字整理。
方案概览
随着全行业数字化转型的推进,数据业务场景不断涌现,数据总量持续增长,云原生数据湖服务成为实现业务的技术支持。
在企业数字化建设过程中,由于采用技术路线不同、且形态各异,异构数据量逐渐增加,各项业务对数据的时效性要求也不一样,形成了混合数据生态。
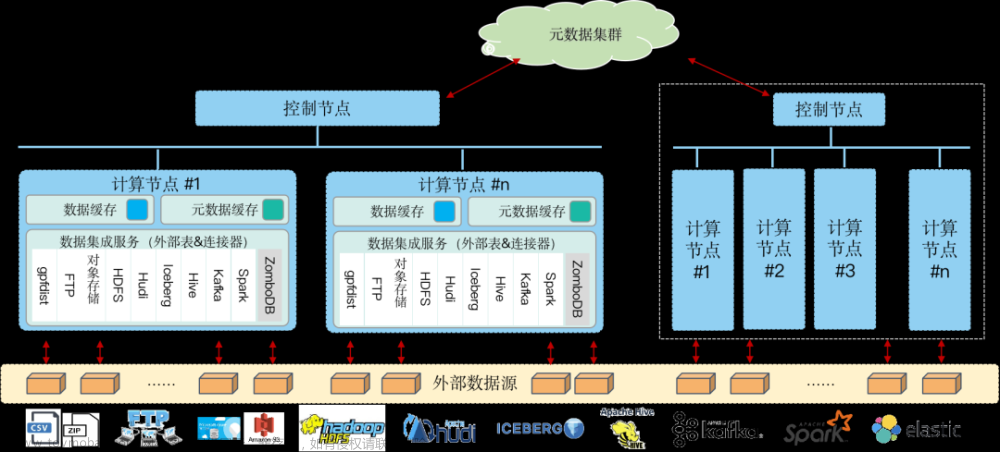
图1:HashData湖仓一体方案架构示意图
HashData作为一款满足数据湖场景的云原生数据仓库,提供了外部表和连接器两类组件,帮助企业实现Data Fabric架构,并基于EPP引擎进行并行、高速的数据访问,实现与企业混合数据生态的无缝集成,可以支撑以下典型应用场景:
- 构建数据联邦,无需搬迁数据,实现多数据源联邦查询;
- 连接各类数据源,完成数据采集(批量、实时);
- 与Hive、Hudi/Iceberg、Spark等集成,构建企业级的湖仓一体的数据平台。
元数据存储与同步
传统MPP架构的数据库,存储、计算紧耦合,数据存储在本地系统,存储能力的扩展通过增加集群节点实现,造成计算资源严重浪费;同时随着数据量的增长,每个集群的数据无法做到有效共享,导致“数据孤岛”现象。
HashData云数仓通过元数据、计算和存储三层解耦的架构设计,解决了传统MPP 数据库并发受限、扩缩容不灵活等难题。
HashData的元数据服务层管理各类元数据,面向所有计算集群,提供统一的元数据服务,保证多个计算集群面对统一的数据视图,进行一致性访问。
HashData的元数据服务分成三个层次:调度层、无状态服务层、元数据持久层。其中,元数据服务通过全球可访问的分布式系统提供,负责数据持久化的对象存储使用FoundationDB,中间的计算层则实现了完全无状态化。
为避免出现“数据孤岛”和冗余,HashData采用共享存储架构,任何一个计算集群都可以去访问同一份数据,所有集群共享同一份元数据,彻底消除“数据孤岛”和冗余,确保数据的实时性和一致性。
通过统一共享的元数据集群,HashData可以确保用户在管理数据资产的时候,元数据集群可以实现按需搭建、横向扩展,帮助用户安全、平滑实现应用在集群间的迁移,实现数据资产的统一。同时,HashData通过统一的共享存储,可以兼容更多类型的异构数据。
HMS服务与异构数据一站式查询方案
Hive作为一款基于Hadoop的数仓工具,凭借出色的大数据处理能力和稳定的性能,被许多大中型企业应用于海量低价值密度数据分析领域,但其在处理异构文件和时效性方面存在不足,在实现湖仓一体化时,数据迁移往往耗时漫长,无法满足当前企业对数据分析实时性的要求。
为了保证数仓能够实时、快速地访问、分析数据湖内的Hive数据,HashData研发了对HMS(Hive Metastore)异构数据的一站式查询方案,使用Kafka连接器作为中间件,打通数仓与数据湖,实现了对主动同步、被动同步、异步同步与按需同步的完全支持。

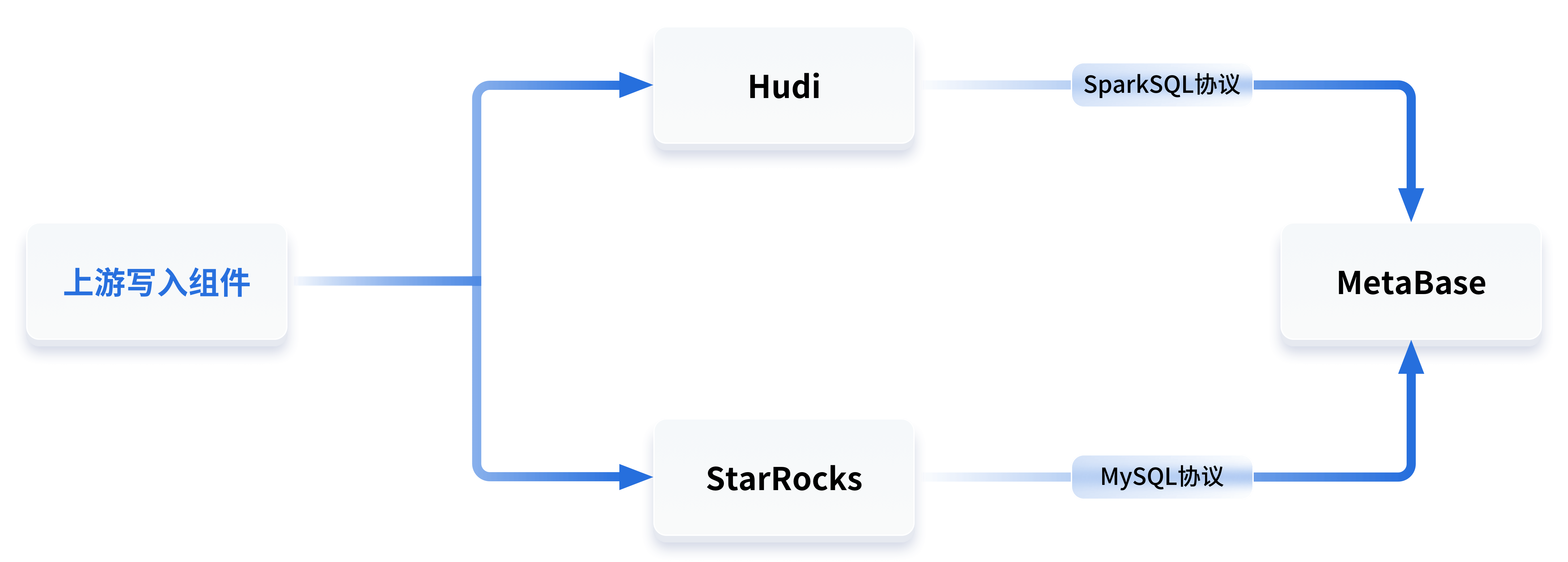
图2:HMS服务与异构数据一站式查询方案架构图
Kafka连接器作为开源、可靠、可扩展的流式传输数据的工具,可以基于数据量和数据时间去做同步,使得大量数据集合移入和移出变得简单,也解决了企业对兼容性的顾虑。此外,通过Kafka来实现数据同步,可以确保Hive集群保持无损状态。
在实际落地时,HashData数仓部署成功后,Kafka可以直接拉取需求服务。对于客户来说,免去了Hive表数据导出、传输等繁琐的流程,让用户专注于业务数据分析。此外,Kafka还具备过滤机制,可以对某些异常的操作和场景进行限制,用户可以有选择性地对数据进行同步。
HashData在实现Hive数据同步的时候,所有的标准都基于MetaStore数据服务的开源路线,进一步降低了客户产品兼容、适配的工作量。
同时,在建立HiveMetaStore的init()办法中,HashData创立了三种监听形式:MetaStorePreEventListener、MetaStoreEventListener和MetaStoreEndFunctionListener,通过监听数据变更通知,按需发送到Kafka,确保元数据能够同步变更,保障系统的稳定性。
结语文章来源:https://www.toymoban.com/news/detail-806332.html
HMS服务与异构数据一站式查询方案设计初衷,旨在通过轻量级、简单化的技术架构,降低企业湖仓建设过程中产品选型、数据管理的难度和成本,高效发挥湖仓一体低成本、高可用、易拓展的优势,帮助企业建立统一治理、湖仓一体的云原生数据分析平台。文章来源地址https://www.toymoban.com/news/detail-806332.html
到了这里,关于HashData湖仓一体方案:方案概览与Hive数据同步的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!