注意:在运行此代码之前,请确保已安装
requests和beautifulsoup4库文章来源地址https://www.toymoban.com/news/detail-806395.html
pip install requests beautifulsoup4代码如下
import requests
from bs4 import BeautifulSoup
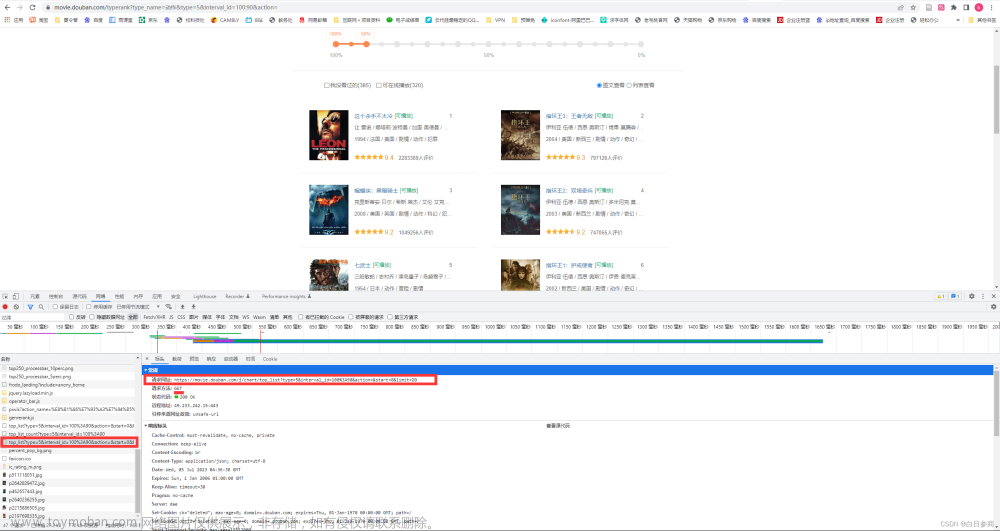
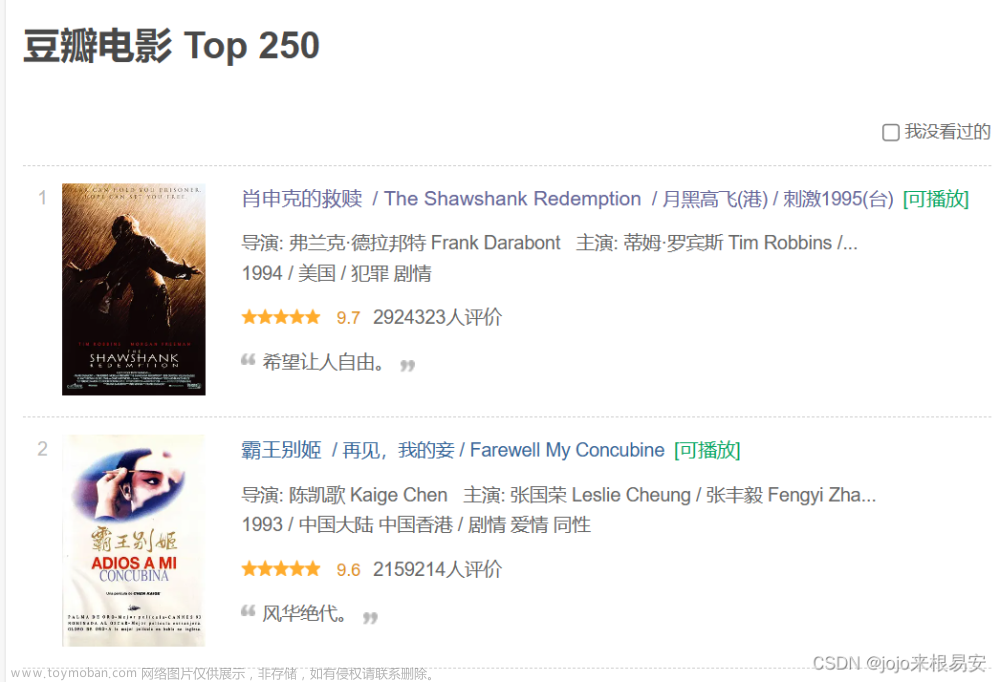
url = 'https://movie.douban.com/chart' # 豆瓣电影排行榜页面
# 发送GET请求获取页面内容
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
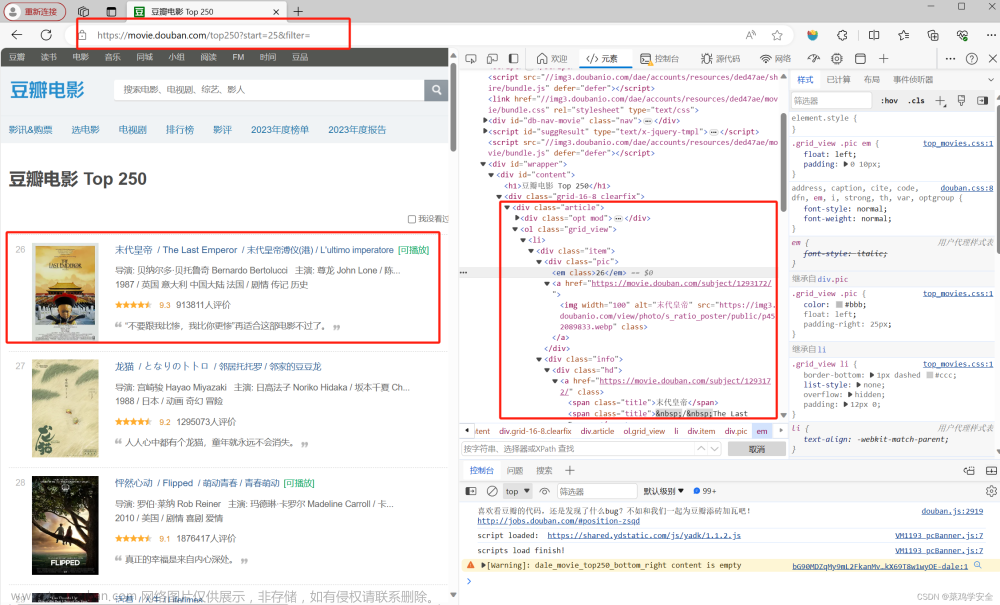
# 解析页面获取电影名称和评分
movies = soup.find_all('div', class_='pl2')
for movie in movies:
name = movie.find('a').text.strip()
rating = movie.find('span', class_='rating_nums').text.strip()
print('电影名称:', name, '评分:', rating)文章来源:https://www.toymoban.com/news/detail-806395.html
到了这里,关于Python爬虫案例分享【爬取豆瓣电影排行榜的电影名称和评分】的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!

![[Python练习]使用Python爬虫爬取豆瓣top250的电影的页面源码](https://imgs.yssmx.com/Uploads/2024/02/797225-1.png)