LLMs:Chinese-LLaMA-Alpaca的简介(扩充中文词表+增量预训练+指令精调)、安装、案例实战应用之详细攻略
导读:2023年4月17日,哈工大讯飞联合实验室,本项目开源了中文LLaMA模型和指令精调的Alpaca大模型,以进一步促进大模型在中文NLP社区的开放研究。Chinese-LLaMA在原版LLaMA的基础上进行了三步走=扩充中文词表+增量预训练+指令精调:扩充中文词表并使用了大规模中文语料数据进行增量预训练(因为采用了LoRA技巧,其本质还是高效参数微调),更好地理解新的语义和语境,进一步提升了中文基础语义理解能力。然后,Chinese-Alpaca模型进一步使用了中文指令数据进行指令精调(依旧采用了LoRA技巧),显著提升了模型对指令的理解和执行能力。
>>LoRA权重无法单独使用:理解为原LLaMA模型上的一个补丁,即需要合并原版LLaMA模型才能使用;
>>针对原版LLaMA模型扩充了中文词表,提升了中文编解码效率;
>>开源了使用中文文本数据预训练的Chinese-LLaMA以及经过指令精调的Chinese-Alpaca;
>>开源了预训练脚本、指令精调脚本,用户可根据需要进一步训练模型;
>>快速使用笔记本电脑(个人PC)的CPU/GPU本地量化和部署体验大模型;排疑:可以不进行增量预训练而直接采用指令微调吗?
如果没有进行增量预训练,模型可能无法充分利用新的中文词表,并可能在生成和理解中遇到困难。不进行增量预训练而直接使用指令微调,可能会限制模型在新的中文词表上的性能和适应性。因此,建议在进行指令微调之前,先进行适当的增量预训练,以提高模型的性能和适应性。
目录
相关文章
论文相关
LLMs:《Efficient and Effective Text Encoding for Chinese LLaMA and Alpaca-4月17日版》翻译与解读
LLMs:《Efficient And Effective Text Encoding For Chinese Llama And Alpaca—6月15日版本》翻译与解读
LLMs之LLaMA2:LLaMA2的简介(技术细节)、安装、使用方法(开源-免费用于研究和商业用途)之详细攻略
实战应用相关
LLMs:Chinese-LLaMA-Alpaca的简介(扩充中文词表+增量预训练+指令精调)、安装、案例实战应用之详细攻略
LLMs之Chinese-LLaMA-Alpaca:LLaMA汉化版项目详细源码解读多个py文件-基于Ng单机单卡实现定义数据集(生成指令数据)→数据预处理(token分词/合并权重)→增量预训练(本质是高效参数微调,LoRA的参数/LLaMA的参数)→指令微调LoRA权重(继续训练/全新训练)→模型推理(CLI、GUI【webui/LLaMACha/LangChain】)
LLMs:在单机CPU+Windows系统上实现中文LLaMA算法(基于Chinese-LLaMA-Alpaca)进行模型部署(llama.cpp)且实现模型推理全流程步骤的图文教程(非常详细)
LLMs之LLaMA-7B-QLoRA:基于Alpaca-Lora代码在CentOS和多卡(A800+并行技术)实现全流程完整复现LLaMA-7B—安装依赖、转换为HF模型文件、模型微调(QLoRA+单卡/多卡)、模型推理(对比终端命令/llama.cpp/Docker封装)图文教程之详细攻略
LLMs:Chinese-LLaMA-Alpaca-2(基于deepspeed框架)的简介、安装、案例实战应用之详细攻略
LLMs之Chinese-LLaMA-Alpaca-2:源码解读(run_clm_pt_with_peft.py文件)—模型训练前置工作(参数解析+配置日志)→模型初始化(检测是否存在训练过的checkpoint+加载预训练模型和tokenizer)→数据预处理(处理【标记化+分块】+切分txt数据集)→优化模型配置(量化模块+匹配模型vocabulary大小与tokenizer+初始化PEFT模型【LoRA】+梯度累积checkpointing等)→模型训练(继续训练+评估指标+自动保存中间训练结果)/模型评估(+PPL指标)
LLMs之Chinese-LLaMA-Alpaca-2:源码解读(run_clm_sft_with_peft.py文件)—模型训练前置工作(参数解析+配置日志)→模型初始化(检测是否存在训练过的checkpoint+加载预训练模型和tokenizer)→数据预处理(监督式任务的数据收集器+指令数据集【json格式】)→优化模型配置(量化模块+匹配模型vocabulary大小与tokenizer+初始化PEFT模型【LoRA】+梯度累积checkpointing等)→模型训练(继续训练+评估指标+自动保存中间训练结果)/模型评估(+PPL指标)
LLMs之LLaMA2:基于LocalGPT利用LLaMA2模型实现本地化的知识库(Chroma)并与本地文档(基于langchain生成嵌入)进行对话问答图文教程+代码详解之详细攻略
LLMs之LLaMA2:基于云端进行一键部署对LLaMA2模型实现推理(基于text-generation-webui)执行对话聊天问答任务、同时微调LLaMA2模型(配置云端环境【A100】→下载数据集【datasets】→加载模型【transformers】→分词→模型训练【peft+SFTTrainer+wandb】→基于HuggingFace实现云端分享)之图文教程详细攻略
LLMs之LLaMA2:基于text-generation-webui工具来本地部署并对LLaMA2模型实现推理执行对话聊天问答任务(一键安装tg webui+手动下载模型+启动WebUI服务)、同时微调LLaMA2模型(采用Conda环境安装tg webui+PyTorch→CLI/GUI下载模型→启动WebUI服务→GUI式+LoRA微调→加载推理)之图文教程详细攻略
Chinese-LLaMA-Alpaca的简介
1、主要内容
2、版本更新内容公告
3、系统效果:介绍了部分场景和任务下的使用体验效果
生成效果评测
客观效果评测
4、下图展示了本项目以及二期项目推出的所有大模型之间的关系
5、下面是中文LLaMA和Alpaca模型的基本对比以及建议使用场景(包括但不限于),更多内容见训练细节。
Chinese-LLaMA-Alpaca的的安装
1、模型下载:中文LLaMA、Alpaca大模型下载地址:LoRA权重无法单独使用(理解为原LLaMA模型上的一个补丁)+需要合并原版LLaMA模型才能使用
T1、直接从网盘下载
推荐模型下载
其他模型下载
T2、在transformers平台下载,🤗transformers调用
2、合并模型(重要):LoRA权重模型,可以理解为原LLaMA模型上的一个“补丁”,两者合并即可获得完整版权重;中文LLaMA/Alpaca LoRA模型无法单独使用,需要搭配原版LLaMA模型
3、训练细节—介绍了中文LLaMA、Alpaca大模型的训练细节:词表扩充→预训练→指令精调
Chinese-LLaMA-Alpaca的的使用方法
1、本地推理与快速部署:介绍了如何对模型进行量化并使用个人电脑部署并体验大模型
相关文章
论文相关
LLMs:《Efficient and Effective Text Encoding for Chinese LLaMA and Alpaca-4月17日版》翻译与解读
LLMs:《Efficient and Effective Text Encoding for Chinese LLaMA and Alpaca-4月17日版》翻译与解读_一个处女座的程序猿的博客-CSDN博客
LLMs:《Efficient And Effective Text Encoding For Chinese Llama And Alpaca—6月15日版本》翻译与解读
https://yunyaniu.blog.csdn.net/article/details/131318974
LLMs之LLaMA2:LLaMA2的简介(技术细节)、安装、使用方法(开源-免费用于研究和商业用途)之详细攻略
LLMs之LLaMA2:LLaMA2的简介(技术细节)、安装、使用方法(开源-免费用于研究和商业用途)之详细攻略_一个处女座的程序猿的博客-CSDN博客
实战应用相关
LLMs:Chinese-LLaMA-Alpaca的简介(扩充中文词表+增量预训练+指令精调)、安装、案例实战应用之详细攻略
https://yunyaniu.blog.csdn.net/article/details/130397623
LLMs之Chinese-LLaMA-Alpaca:LLaMA汉化版项目详细源码解读多个py文件-基于Ng单机单卡实现定义数据集(生成指令数据)→数据预处理(token分词/合并权重)→增量预训练(本质是高效参数微调,LoRA的参数/LLaMA的参数)→指令微调LoRA权重(继续训练/全新训练)→模型推理(CLI、GUI【webui/LLaMACha/LangChain】)
https://yunyaniu.blog.csdn.net/article/details/131319010
LLMs:在单机CPU+Windows系统上实现中文LLaMA算法(基于Chinese-LLaMA-Alpaca)进行模型部署(llama.cpp)且实现模型推理全流程步骤的图文教程(非常详细)
LLMs之Chinese-LLaMA-Alpaca:基于单机CPU+Windows系统实现中文LLaMA算法进行模型部署(llama.cpp)+模型推理全流程步骤【安装环境+创建环境并安装依赖+原版L_一个处女座的程序猿的博客-CSDN博客
LLMs之LLaMA-7B-QLoRA:基于Alpaca-Lora代码在CentOS和多卡(A800+并行技术)实现全流程完整复现LLaMA-7B—安装依赖、转换为HF模型文件、模型微调(QLoRA+单卡/多卡)、模型推理(对比终端命令/llama.cpp/Docker封装)图文教程之详细攻略
LLMs之LLaMA-7B-QLoRA:基于Alpaca-Lora代码在CentOS和多卡(A800+并行技术)实现全流程完整复现LLaMA-7B—安装依赖、转换为HF模型文件、模型微调(QLoRA+_一个处女座的程序猿的博客-CSDN博客
LLMs:Chinese-LLaMA-Alpaca-2(基于deepspeed框架)的简介、安装、案例实战应用之详细攻略
LLMs:Chinese-LLaMA-Alpaca-2(基于deepspeed框架)的简介、安装、案例实战应用之详细攻略_一个处女座的程序猿的博客-CSDN博客
LLMs之Chinese-LLaMA-Alpaca-2:源码解读(run_clm_pt_with_peft.py文件)—模型训练前置工作(参数解析+配置日志)→模型初始化(检测是否存在训练过的checkpoint+加载预训练模型和tokenizer)→数据预处理(处理【标记化+分块】+切分txt数据集)→优化模型配置(量化模块+匹配模型vocabulary大小与tokenizer+初始化PEFT模型【LoRA】+梯度累积checkpointing等)→模型训练(继续训练+评估指标+自动保存中间训练结果)/模型评估(+PPL指标)
LLMs之Chinese-LLaMA-Alpaca-2:源码解读(run_clm_pt_with_peft.py文件)—模型训练前置工作(参数解析+配置日志)→模型初始化(检测是否存在训练过的chec-CSDN博客
LLMs之Chinese-LLaMA-Alpaca-2:源码解读(run_clm_sft_with_peft.py文件)—模型训练前置工作(参数解析+配置日志)→模型初始化(检测是否存在训练过的checkpoint+加载预训练模型和tokenizer)→数据预处理(监督式任务的数据收集器+指令数据集【json格式】)→优化模型配置(量化模块+匹配模型vocabulary大小与tokenizer+初始化PEFT模型【LoRA】+梯度累积checkpointing等)→模型训练(继续训练+评估指标+自动保存中间训练结果)/模型评估(+PPL指标)
LLMs之Chinese-LLaMA-Alpaca-2:源码解读(run_clm_sft_with_peft.py文件)—模型训练前置工作(参数解析+配置日志)→模型初始化(检测是否存在训练过的che_一个处女座的程序猿的博客-CSDN博客
LLMs之LLaMA2:基于LocalGPT利用LLaMA2模型实现本地化的知识库(Chroma)并与本地文档(基于langchain生成嵌入)进行对话问答图文教程+代码详解之详细攻略
LLMs之LLaMA2:基于LocalGPT利用LLaMA2模型实现本地化的知识库(Chroma)并与本地文档(基于langchain生成嵌入)进行对话问答图文教程+代码详解之详细攻略_一个处女座的程序猿的博客-CSDN博客
LLMs之LLaMA2:基于云端进行一键部署对LLaMA2模型实现推理(基于text-generation-webui)执行对话聊天问答任务、同时微调LLaMA2模型(配置云端环境【A100】→下载数据集【datasets】→加载模型【transformers】→分词→模型训练【peft+SFTTrainer+wandb】→基于HuggingFace实现云端分享)之图文教程详细攻略
LLMs之LLaMA2:基于云端进行一键部署对LLaMA2模型实现推理(基于text-generation-webui)执行对话聊天问答任务、同时微调LLaMA2模型(配置云端环境【A100】→下载数_一个处女座的程序猿的博客-CSDN博客
LLMs之LLaMA2:基于text-generation-webui工具来本地部署并对LLaMA2模型实现推理执行对话聊天问答任务(一键安装tg webui+手动下载模型+启动WebUI服务)、同时微调LLaMA2模型(采用Conda环境安装tg webui+PyTorch→CLI/GUI下载模型→启动WebUI服务→GUI式+LoRA微调→加载推理)之图文教程详细攻略
LLMs之LLaMA2:基于text-generation-webui工具来本地部署并对LLaMA2模型实现推理执行对话聊天问答任务(一键安装tg webui+手动下载模型+启动WebUI服务)、同时_一个处女座的程序猿的博客-CSDN博客
Chinese-LLaMA-Alpaca的简介

本项目开源了中文LLaMA模型和指令精调的Alpaca大模型,以进一步促进大模型在中文NLP社区的开放研究。这些模型在原版LLaMA的基础上扩充了中文词表并使用了中文数据进行二次预训练,进一步提升了中文基础语义理解能力。同时,中文Alpaca模型进一步使用了中文指令数据进行精调,显著提升了模型对指令的理解和执行能力。 上图是中文Alpaca-Plus-7B模型在本地CPU量化部署后的实际体验速度和效果。
| 地址 |
GitHub:https://github.com/ymcui/Chinese-LLaMA-Alpaca 论文:https://arxiv.org/abs/2304.08177 |
| 时间 |
[v1] 2023年4月17日 [v2] 2023年6月15日 |
| 作者 |
1、主要内容
- 🚀 针对原版LLaMA模型扩充了中文词表,提升了中文编解码效率
- 🚀 开源了使用中文文本数据预训练的中文LLaMA以及经过指令精调的中文Alpaca
- 🚀 开源了预训练脚本、指令精调脚本,用户可根据需要进一步训练模型
- 🚀 快速使用笔记本电脑(个人PC)的CPU/GPU本地量化和部署体验大模型
- 🚀 支持🤗transformers, llama.cpp, text-generation-webui, LlamaChat, LangChain, privateGPT等生态
- 目前已开源的模型版本:7B(基础版、Plus版、Pro版)、13B(基础版、Plus版、Pro版)、33B(基础版、Plus版、Pro版)
2、版本更新内容公告

3、系统效果:介绍了部分场景和任务下的使用体验效果
生成效果评测
为了快速评测相关模型的实际文本生成表现,本项目在给定相同的prompt的情况下,在一些常见任务上对比测试了本项目的中文Alpaca-7B、中文Alpaca-13B、中文Alpaca-33B、中文Alpaca-Plus-7B、中文Alpaca-Plus-13B的效果。生成回复具有随机性,受解码超参、随机种子等因素影响。以下相关评测并非绝对严谨,测试结果仅供晾晒参考,欢迎自行体验。
- 详细评测结果及生成样例请查看examples目录
- 📊 Alpaca模型在线对战:http://chinese-alpaca-arena.ymcui.com
客观效果评测
本项目还在“NLU”类客观评测集合上对相关模型进行了测试。这类评测的结果不具有主观性,只需要输出给定标签(需要设计标签mapping策略),因此可以从另外一个侧面了解大模型的能力。本项目在近期推出的C-Eval评测数据集上测试了相关模型效果,其中测试集包含12.3K个选择题,涵盖52个学科。以下是部分模型的valid和test集评测结果(Average),完整结果请参考技术报告。
| 模型 | Valid (zero-shot) | Valid (5-shot) | Test (zero-shot) | Test (5-shot) |
|---|---|---|---|---|
| Chinese-Alpaca-Plus-33B | 46.5 | 46.3 | 44.9 | 43.5 |
| Chinese-Alpaca-33B | 43.3 | 42.6 | 41.6 | 40.4 |
| Chinese-Alpaca-Plus-13B | 43.3 | 42.4 | 41.5 | 39.9 |
| Chinese-Alpaca-Plus-7B | 36.7 | 32.9 | 36.4 | 32.3 |
| Chinese-LLaMA-Plus-33B | 37.4 | 40.0 | 35.7 | 38.3 |
| Chinese-LLaMA-33B | 34.9 | 38.4 | 34.6 | 39.5 |
| Chinese-LLaMA-Plus-13B | 27.3 | 34.0 | 27.8 | 33.3 |
| Chinese-LLaMA-Plus-7B | 27.3 | 28.3 | 26.9 | 28.4 |
需要注意的是,综合评估大模型能力仍然是亟待解决的重要课题,合理辩证地看待大模型相关各种评测结果有助于大模型技术的良性发展。推荐用户在自己关注的任务上进行测试,选择适配相关任务的模型。
C-Eval推理代码请参考本项目 >>>
4、下图展示了本项目以及二期项目推出的所有大模型之间的关系

5、下面是中文LLaMA和Alpaca模型的基本对比以及建议使用场景(包括但不限于),更多内容见训练细节。
| 对比项 | 中文LLaMA | 中文Alpaca |
|---|---|---|
| 训练方式 | 传统CLM | 指令精调 |
| 模型类型 | 基座模型 | 指令理解模型(类ChatGPT) |
| 训练语料 | 无标注通用语料 | 有标注指令数据 |
| 词表大小[3] | 49953 | 49954=49953+1(pad token) |
| 输入模板 | 不需要 | 需要符合模板要求[1] |
| 适用场景 ✔️ | 文本续写:给定上文内容,让模型生成下文 | 指令理解(问答、写作、建议等);多轮上下文理解(聊天等) |
| 不适用场景 ❌ | 指令理解 、多轮聊天等 | 文本无限制自由生成 |
| llama.cpp | 使用-p参数指定上文 |
使用-ins参数启动指令理解+聊天模式 |
| text-generation-webui | 不适合chat模式 | 使用--cpu可在无显卡形式下运行 |
| LlamaChat | 加载模型时选择"LLaMA" | 加载模型时选择"Alpaca" |
| HF推理代码 | 无需添加额外启动参数 | 启动时添加参数 --with_prompt
|
| web-demo代码 | 不适用 | 直接提供Alpaca模型位置即可;支持多轮对话 |
| LangChain示例 / privateGPT | 不适用 | 直接提供Alpaca模型位置即可 |
| 已知问题 | 如果不控制终止,则会一直写下去,直到达到输出长度上限。[2] | 请使用Pro版,以避免Plus版回复过短的问题。 |
[1] llama.cpp/LlamaChat/HF推理代码/web-demo代码/LangChain示例等已内嵌,无需手动添加模板。
[2] 如果出现模型回答质量特别低、胡言乱语、不理解问题等情况,请检查是否使用了正确的模型和启动参数。
[3] 经过指令精调的Alpaca会比LLaMA多一个pad token,因此请勿混用LLaMA/Alpaca词表。
Chinese-LLaMA-Alpaca的的安装
1、模型下载:中文LLaMA、Alpaca大模型下载地址:LoRA权重无法单独使用(理解为原LLaMA模型上的一个补丁)+需要合并原版LLaMA模型才能使用
Facebook官方发布的LLaMA模型禁止商用,并且官方没有正式开源模型权重(虽然网上已经有很多第三方的下载地址)。为了遵循相应的许可,这里发布的是LoRA权重,可以理解为原LLaMA模型上的一个“补丁”,两者合并即可获得完整版权重。以下中文LLaMA/Alpaca LoRA模型无法单独使用,需要搭配原版LLaMA模型。请参考本项目给出的合并模型步骤重构模型。
实际上,由于LLaMA许可限制无法提供原版模型,LoRA模型本身也不完整,所以必须与原版LLaMA模型合并后才能形成可用的完整中文大模型。这是遵循开源协议的一种妥协方案。
T1、直接从网盘下载
推荐模型下载
以下为本项目推荐使用的模型列表,通常使用了更多的训练数据和优化的模型训练方法和参数,请优先使用这些模型(其余模型请查看其他模型)。如希望体验类ChatGPT对话交互,请使用Alpaca模型,而不是LLaMA模型。 对于Alpaca模型,Pro版针对回复内容过短的问题进行改进,模型回复效果有明显提升;如果更偏好短回复,请选择Plus系列。
| 模型名称 | 类型 | 训练数据 | 重构模型[1] | 大小[2] | LoRA下载[3] |
|---|---|---|---|---|---|
| Chinese-LLaMA-Plus-7B | 基座模型 | 通用120G | 原版LLaMA-7B | 790M |
[百度网盘] [Google Drive] |
| Chinese-LLaMA-Plus-13B | 基座模型 | 通用120G | 原版LLaMA-13B | 1.0G |
[百度网盘] [Google Drive] |
| Chinese-LLaMA-Plus-33B 🆕 | 基座模型 | 通用120G | 原版LLaMA-33B | 1.3G[6] |
[百度网盘] [Google Drive] |
| Chinese-Alpaca-Pro-7B 🆕 | 指令模型 | 指令4.3M |
原版LLaMA-7B & LLaMA-Plus-7B[4] |
1.1G |
[百度网盘] [Google Drive] |
| Chinese-Alpaca-Pro-13B 🆕 | 指令模型 | 指令4.3M | 原版LLaMA-13B & LLaMA-Plus-13B[4] |
1.3G |
[百度网盘] [Google Drive] |
| Chinese-Alpaca-Pro-33B 🆕 | 指令模型 | 指令4.3M | 原版LLaMA-33B & LLaMA-Plus-33B[4] |
2.1G |
[百度网盘] [Google Drive] |
[1] 重构需要原版LLaMA模型,去LLaMA项目申请使用或参考这个PR。因版权问题本项目无法提供下载链接。
[2] 经过重构后的模型大小比同等量级的原版LLaMA大一些(主要因为扩充了词表)。
[3] 下载后务必检查压缩包中模型文件的SHA256是否一致,请查看SHA256.md。
[4] Alpaca-Plus模型需要同时下载对应的LLaMA-Plus模型,请参考合并教程。
[5] 有些地方称为30B,实际上是Facebook在发布模型时写错了,论文里仍然写的是33B。
[6] 采用FP16存储,故模型体积较小。
压缩包内文件目录如下(以Chinese-LLaMA-7B为例):
chinese_llama_lora_7b/
- adapter_config.json # LoRA权重配置文件
- adapter_model.bin # LoRA权重文件
- special_tokens_map.json # special_tokens_map文件
- tokenizer_config.json # tokenizer配置文件
- tokenizer.model # tokenizer文件
其他模型下载
由于训练方式和训练数据等因素影响,以下模型已不再推荐使用(特定场景下可能仍然有用),请优先使用上一节中的推荐模型。
| 模型名称 | 类型 | 训练数据 | 重构模型 | 大小 | LoRA下载 |
|---|---|---|---|---|---|
| Chinese-LLaMA-7B | 基座模型 | 通用20G | 原版LLaMA-7B | 770M |
[百度网盘] [Google Drive] |
| Chinese-LLaMA-13B | 基座模型 | 通用20G | 原版LLaMA-13B | 1.0G |
[百度网盘] [Google Drive] |
| Chinese-LLaMA-33B | 基座模型 | 通用20G | 原版LLaMA-33B | 2.7G |
[百度网盘] [Google Drive] |
| Chinese-Alpaca-7B | 指令模型 | 指令2M | 原版LLaMA-7B | 790M |
[百度网盘] [Google Drive] |
| Chinese-Alpaca-13B | 指令模型 | 指令3M | 原版LLaMA-13B | 1.1G |
[百度网盘] [Google Drive] |
| Chinese-Alpaca-33B | 指令模型 | 指令4.3M | 原版LLaMA-33B | 2.8G |
[百度网盘] [Google Drive] |
| Chinese-Alpaca-Plus-7B | 指令模型 | 指令4M | 原版LLaMA-7B & LLaMA-Plus-7B |
1.1G |
[百度网盘] [Google Drive] |
| Chinese-Alpaca-Plus-13B | 指令模型 | 指令4.3M | 原版LLaMA-13B & LLaMA-Plus-13B |
1.3G |
[百度网盘] [Google Drive] |
| Chinese-Alpaca-Plus-33B | 指令模型 | 指令4.3M | 原版LLaMA-33B & LLaMA-Plus-33B |
2.1G |
[百度网盘] [Google Drive] |
T2、在transformers平台下载,🤗transformers调用
可以在🤗Model Hub下载以上所有模型,并且使用transformers和PEFT调用中文LLaMA或Alpaca LoRA模型。以下模型调用名称指的是使用.from_pretrained()中指定的模型名称。
-
Pro版命名(只有Alpaca):
ziqingyang/chinese-alpaca-pro-lora-${model_size} -
Plus版命名:
ziqingyang/chinese-${model_name}-plus-lora-${model_size} -
基础版命名:
ziqingyang/chinese-${model_name}-lora-${model_size} -
$model_name:llama或者alpaca;$model_size:7b,13b,33b -
举例:Chinese-LLaMA-Plus-33B模型对应的调用名称是
ziqingyang/chinese-llama-plus-lora-33b
详细清单与模型下载地址:https://huggingface.co/ziqingyang
2、合并模型(重要):LoRA权重模型,可以理解为原LLaMA模型上的一个“补丁”,两者合并即可获得完整版权重;中文LLaMA/Alpaca LoRA模型无法单独使用,需要搭配原版LLaMA模型
介绍如何将下载的LoRA模型与原版LLaMA合并
前面提到LoRA模型无法单独使用,必须与原版LLaMA进行合并才能转为完整模型,以便进行模型推理、量化或者进一步训练。请选择以下方法对模型进行转换合并。
| 方式 | 适用场景 | 教程 |
|---|---|---|
| 在线转换 | Colab用户可利用本项目提供的notebook进行在线转换并量化模型 | 链接 |
| 手动转换 | 离线方式转换,生成不同格式的模型,以便进行量化或进一步精调 | 链接 |
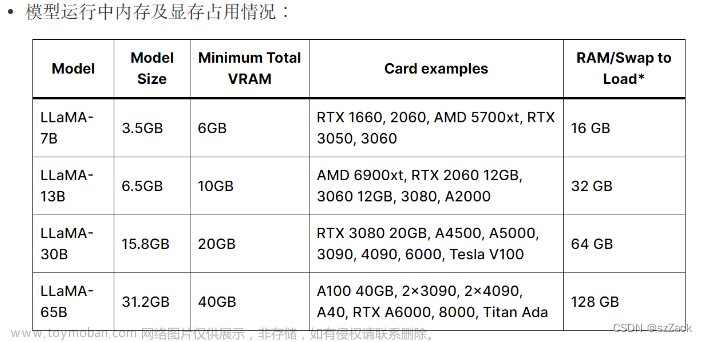
以下是合并模型后,FP16精度和4-bit量化后的大小,转换前确保本机有足够的内存和磁盘空间(最低要求):
| 模型版本 | 7B | 13B | 33B | 65B |
|---|---|---|---|---|
| 原模型大小(FP16) | 13 GB | 24 GB | 60 GB | 120 GB |
| 量化后大小(8-bit) | 7.8 GB | 14.9 GB | 32.4 GB | ~60 GB |
| 量化后大小(4-bit) | 3.9 GB | 7.8 GB | 17.2 GB | 38.5 GB |
具体内容请参考本项目 >>> 📚 GitHub Wiki文章来源地址https://www.toymoban.com/news/detail-806619.html
3、训练细节—介绍了中文LLaMA、Alpaca大模型的训练细节:词表扩充→预训练→指令精调
整个训练流程包括词表扩充、预训练和指令精调三部分。
- 本项目的模型均在原LLaMA词表的基础上扩充了中文单词,代码请参考merge_tokenizers.py
- 预训练和指令精调代码参考了🤗transformers中的run_clm.py和Stanford Alpaca项目中数据集处理的相关部分
- 已开源用于预训练和指令精调的训练脚本:预训练脚本Wiki、指令精调脚本Wiki
具体内容请参考本项目 >>> 📚 GitHub Wiki
Chinese-LLaMA-Alpaca的的使用方法
1、本地推理与快速部署:介绍了如何对模型进行量化并使用个人电脑部署并体验大模型
本项目中的模型主要支持以下量化、推理和部署方式。
| 推理和部署方式 | 特点 | 平台 | CPU | GPU | 量化加载 | 图形界面 | 教程 |
|---|---|---|---|---|---|---|---|
| llama.cpp | 丰富的量化选项和高效本地推理 | 通用 | ✅ | ✅ | ✅ | ❌ | link |
| 🤗Transformers | 原生transformers推理接口 | 通用 | ✅ | ✅ | ✅ | ✅ | link |
| text-generation-webui | 前端Web UI界面的部署方式 | 通用 | ✅ | ✅ | ✅ | ✅ | link |
| LlamaChat | macOS下的图形交互界面 | MacOS | ✅ | ❌ | ✅ | ✅ | link |
| LangChain | LLM应用开发框架,适用于进行二次开发 | 通用 | ✅† | ✅ | ✅† | ❌ | link |
| privateGPT | 基于LangChain的多文档本地问答框架 | 通用 | ✅ | ✅ | ✅ | ❌ | link |
| Colab Gradio Demo | Colab中启动基于Gradio的交互式Web服务 | 通用 | ✅ | ✅ | ✅ | ❌ | link |
| API调用 | 仿OpenAI API接口的服务器Demo | 通用 | ✅ | ✅ | ✅ | ❌ | link |
†: LangChain框架支持,但教程中未实现;详细说明请参考LangChain官方文档。文章来源:https://www.toymoban.com/news/detail-806619.html
具体内容请参考本项目 >>> 📚 GitHub Wiki
到了这里,关于LLMs:Chinese-LLaMA-Alpaca的简介(扩充中文词表+增量预训练+指令精调)、安装、案例实战应用之详细攻略的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!