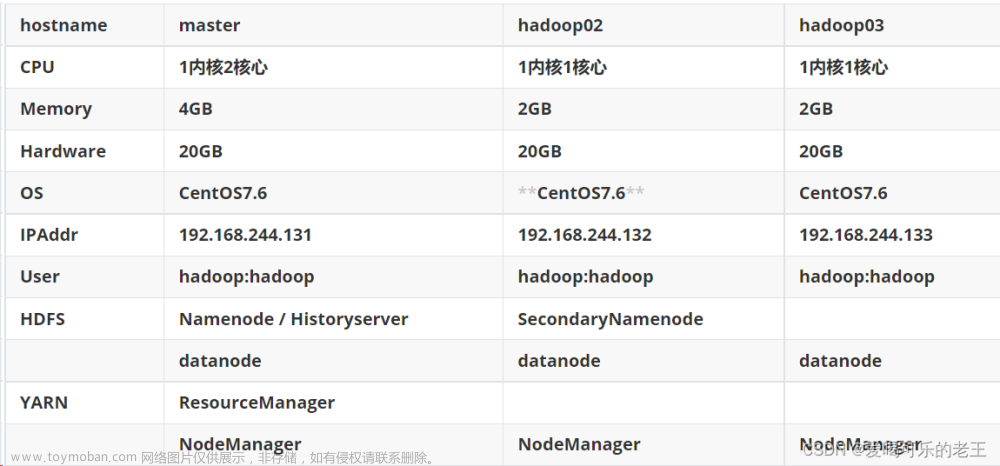
| 服务器 | 运行角色 |
| hadoop01 | namenode、datanode、resourcemanager、nodemanager |
| hadoop02 | secondarynamenode、datanode、nodemanager |
| hadoop03 |
datanode、nodemanager |
基础环境准备
安装包、源码包下载
https://archive.apache.org/dist/hadoop/common/hadoop-3.3.0/

准备三台主机

hosts映射
vi /etc/hosts
JDK1.8安装
JDK1.8
配置ssh免密登录
ssh免密登录
上传安装包、解压安装包
创建工作目录(三台)

上传、解压安装包(hadoop01)
上传到software目录下
#解压
tar zxvf hadoopXXX.tar.gz -C /export/server/配置hadoop系统环境变量
输入命令:
vi /etc/profile
#添加以下内容
export HADOOP_HOME=/usr/software/hadoop-3.3.0
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH保存退出,刷新环境变量
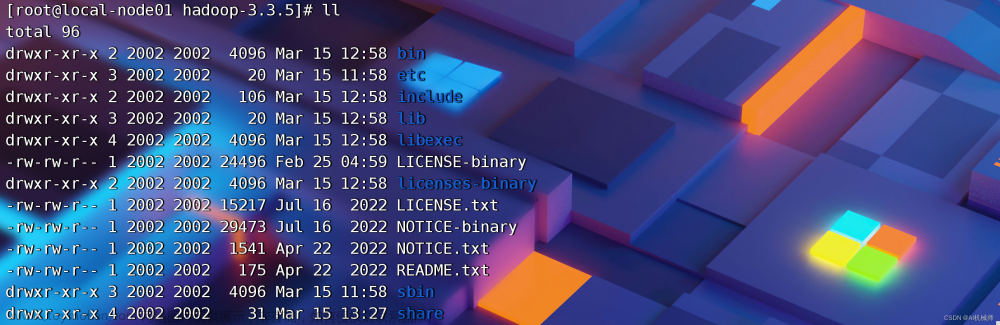
source /etc/profilehadoop安装包目录结构
| 目录 | 说明 |
| bin | Hadoop最基本的管理脚本和使用脚本的目录,这些脚本是sbin目录下管理脚本的基础实现,用户可以直接使用这些脚本管理和使用Hadoop。 |
| etc | Hadoop配置文件所在的目录 |
| include | 对外提供的编程库头文件(具体动态库和静态库在lib目录中),这些头文件均是用C++定义的,通常用于C++程序访问HDFS或者编写MapReduce程序。 |
| lib | 该目录包含了Hadoop对外提供的编程动态库和静态库,与include目录中的头文件结合使用。 |
| sbin | Hadoop各个模块编译后的jar包所在的目录。 |
| share | Hadoop各个模块编译后的jar包所在的目录。 |
配置hadoop集群主要的配置文件进行配置
| 配置文件 |
功能描述 |
| hadoop-env.sh | 配置Hadoop运行所需的环境变量 |
| yarn-env.sh | 配置Yarn运行所需的环境变量 |
| core-site.xml | Hadoop核心全局配置文件,可在其他配置文件中引用 |
| hdfs-site.xml | HDFS配置文件,继承core-site.xml配置文件 |
| mapred-site.xml | MapReduce配置文件,继承core-site.xml配置文件 |
| yarn-site.xml | Yarn配置文件,继承core-site.xml配置文件 |
编辑hadoop配置文件
hadoop-env.sh
cd /export/server/hadoop-3.3.0/etc/hadoop/
vi hadoop-env.sh添加以下内容
#配置JAVA_HOME
export JAVA_HOME=/usr/software/jdk1.8.0_241
#设置用户以执行对应角色shell命令
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export TARN_RESOURCEMANAGER_USER=root
export TARN_NODEMANAGER_USER=rootyarn-site.xml,添加以下内容
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01.itcast.cn</value>
</property>
<property>
<name>yarn,nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>4</value>
</property>core-site.xml,添加以下内容
<configuration>
#hdfs文件系统访问地址
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop01.itcast.cn:8020</value>
</property>
#hadoop本地数据存储目录 format是自动生成
<property>
<name>hadoop.tmp.dir</name>
<value>/export/data/hadoop</value>
</property>
#在Web UI访问HDFS使用的用户名
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
</configuration>
hdfs-site.xml,添加以下内容
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop02.itcast.cn:9868</value>
</property>
</configuration>
mapred-site.xml,添加以下内容
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
</configuration>vi workers,添加以下内容
hadoop01.itcast.cn
hadoop02.itcast.cn
hadoop03.itcast.cn
分发安装包scp同步到其他机器
cd /export/server/
scp -r hadoop-3.3.0 root@hadoop02:/export/server/
scp -r hadoop-3.3.0 root@hadoop03:/export/server/NameNode format 初始化操作
首次启动HDFS时,必须对其进行初始化操作
format本质上是对HDFS进行清理和准备工作
命令:hdfs namenode -format
hadoop启动和关闭
每次手动启动关闭一个进程
HDFS集群:
hdfs --daemon start namenode | datanode | secondarynamenode
hdfs --daemon stop namenode | datanode | secondarynamenode
YARN集群:
yarn --daemon start resourcemanager | nodemanager
yarn --daemon stop resourcemanager | nodemanager
start-all.sh



安装成功
或者看日志查看是否安装成功

在Windows中配置hosts
C:\Windows\System32\drivers\etc
 文章来源:https://www.toymoban.com/news/detail-806687.html
文章来源:https://www.toymoban.com/news/detail-806687.html
 文章来源地址https://www.toymoban.com/news/detail-806687.html
文章来源地址https://www.toymoban.com/news/detail-806687.html
到了这里,关于Hadoop3.X集群安装的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!