1.过拟合欠拟合:
- 欠拟合:模型容量过低,导致模型无法被很好的训练。
- 过拟合:模型过于关注细节导致随着模型容量增加误差增加。
2.权重衰退解决过拟合问题:
- 硬性限制:规定权重的平方和≤固定值θ

- 柔性限制:λ控制了权重的平方和的重要程度
- 增加λ以增加权重的重要程度,降低模型复杂度。

- 增加λ以增加权重的重要程度,降低模型复杂度。
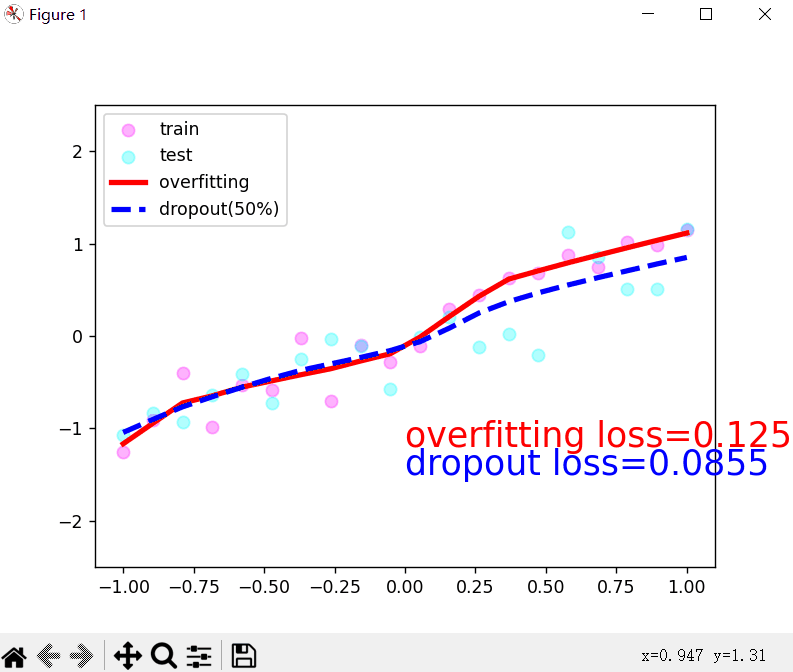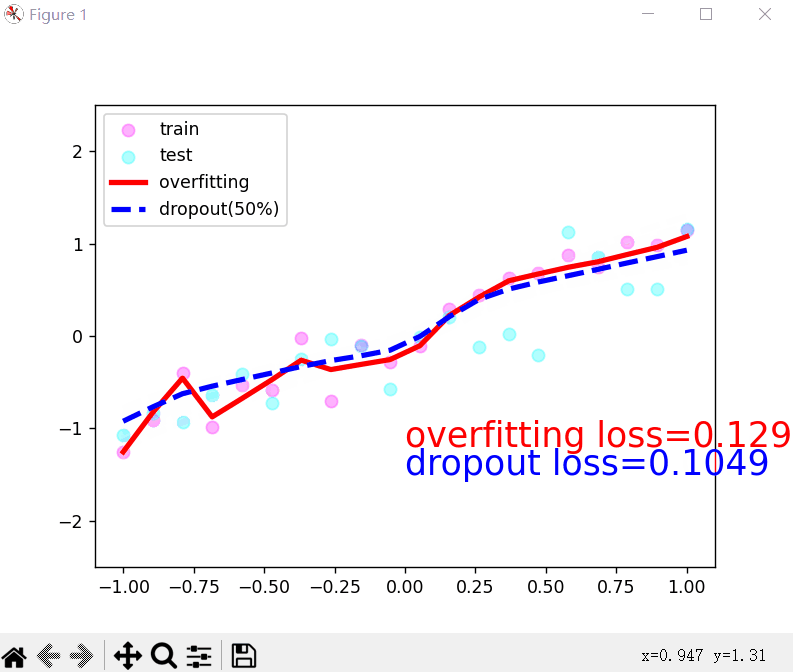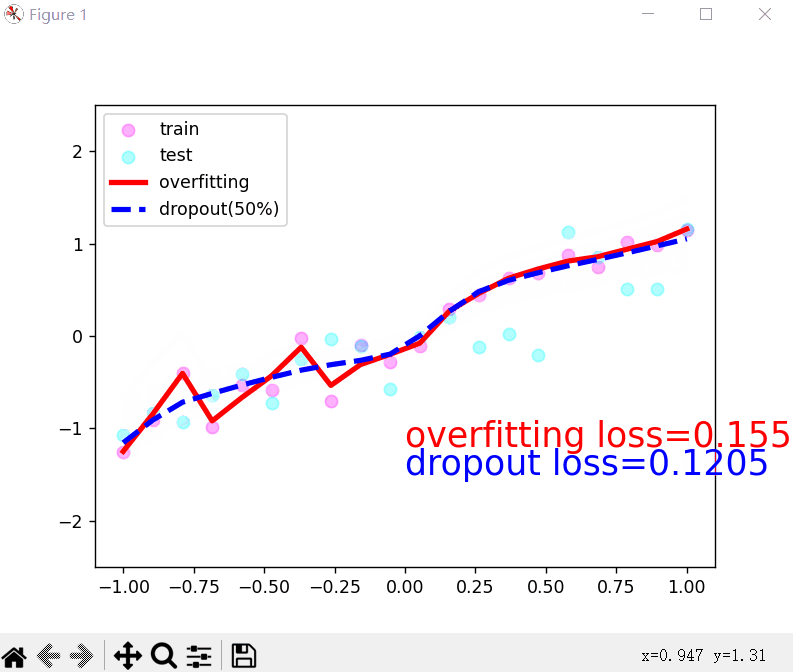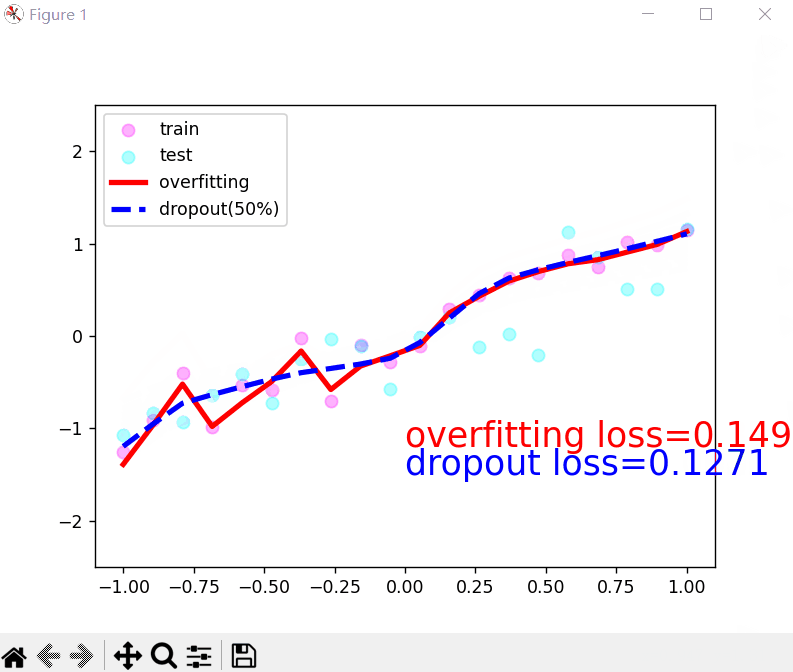
3.丢弃法解决过拟合问题:
- 丢弃法就是在层之间加入丢弃函数,在每层输出之前调用丢弃函数,值变为0的元素即被丢弃,变为非0的元素会变大。


文章来源地址https://www.toymoban.com/news/detail-806699.html
文章来源:https://www.toymoban.com/news/detail-806699.html
到了这里,关于过拟合和欠拟合的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!