设计模式的学习笔记
一. 设计模式相关内容介绍
1 设计模式概述
1.1 软件设计模式的产生背景
设计模式最初并不是出现在软件设计中,而是被用于建筑领域的设计中。
1977 年美国著名建筑大师、加利福尼亚大学伯克利分校环境结构中心主任 Christopher Alexander 在他的著作《建筑模式语言:城镇、建筑、构造》中描述了一些常见的建筑设计问题,并提出了 253 种关于对城镇、邻里、住宅、花园和房间等进行设计的基本模式。
1990 年软件工程界开始研讨设计模式的话题,后来召开了多次关于设计模式的研讨会。直到 1995 年,ErichGamma、Richard Helm、Ralph Johnson、John Vlissides 等 4 位作者合作出版了《设计模式:可复用面向对象软件的基础》一书,在此书中收录了 23 个设计模式,这是设计模式领域里程碑的事件,导致了软件设计模式的突破,这 4 位作者在软件开发领域里也以他们的 Gang of Four,GoF 著称
1.2 软件设计模式的概念
软件设计模式(Software Design Pattern),又称设计模式,是一套被反复使用、多数人知晓的、经过分类编目的、代码设计经验的总结。它描述了在软件设计过程中的一些不断重复发生的问题,以及该问题的解决方案。也就是说,它是解决特定问题的一系列套路,是前辈们的代码设计经验的总结,具有一定的普遍性,可以反复使用。
1.3 学习设计模式的必要性
设计模式的本质是面向对象设计原则的实际运用,是对类的封装性、继承性和包装性以及类的关联关系和组合关系的充分理解。
正确使用设计模式具有以下优点:
- 可以提高程序员的思维能力、编程能力和设计能力。
- 使程序设计更加标准化、代码编制更加工程化,使软件开发效率大大提高,从而缩短软件的开发周期。
- 使设计的代码可重用性高、可读性强、可靠性高、灵活性好、可维护性强。
1.4 设计模式分类
- 创建型模式:用于描述“怎样创建对象”,它的主要特点是“将对象的创建与使用分离”。GoF 书中提供了单例、原型、工厂方法、抽象工程、建造者等 5 种创建型模式。
- 结构型模式:用于描述如何将类或对象按某种布局组成更大的结构,GoF 书中提供了代理、适配器、桥接、装饰、外观、享元、组合等 7 种结构型模式。
- 行为型模式:用于描述类或对象之间怎样相互协作完成单个对象无法单独完成的任务,以及怎样分配职责。GoF 书中提供了模板方法、策略、命令、职责链、状态、观察者、中介者、迭代器、访问者、备忘录、解释器等 11 种行为型模式。
2. UML图
统一建模语言(Unified Modeling Language, UML) 是用来设计软件的可视化建模语言。它的特点是简单、统一、图形化、能表达软件设计中的动态与静态信息。
UML 从目标系统的不同角度出发,定义了用例图、类图、对象图、状态图、活动图、时序图、协作图、构件图、部署图等 9 种图。
2.1 类图
类图(Class Diagram)是显示了模型的静态结构,特别是模型中存在的类、类的内部结构以及它们与其他类的关系等。类图不显示暂时性的信息。类图是面向对象建模的主要组成部分。
类图的作用:
- 在软件工程中,类图是一种静态的结构图,描述了系统的类的集合,类的属性和类之间的关系,可以简化人们对系统的理解。
- 类图是系统分析和设计阶段的重要产物,是系统编码和测试的重要模型。
2.2 类图表示法
2.2.1 类的表示方式
在 UML 图中,类使用包含类名、属性(field)和方法(method)且带有分割线的矩形来表示,比如下图表示一个 Employee 类,它包含 name、age 和 address 这 3 个属性,以及 work() 方法。
属性或方法名称前加的加号和减号表示了这个属性或方法的可见性,UML类图中表示可见性的符号有三种:
- +: 表示 public
- -: 表示 private
- #: 表示 protected
属性的完整表达方式是: 可见性 名称:类型 [= 缺省值]
方法的完整表达方式是: 可见性 名称(参数列表):类型 [: 返回类型]
2.2.2 类与类之间关系的表示方式
2.2.2.1 关联关系
关联关系是对象之间的一种引用关系,用于表示一类对象与另一类对象之间的联系,如老师和学生、师傅和徒弟、丈夫和妻子等。关联关系是类与类之间最常用的一种关系,分为一般关联关系、聚合关系和组合关系。我们先来介绍一般关联。
关联又可以分为单向关联、双向关联、自关联。
1, 单向关联: 在 UML 类图中单向关联用一个带箭头的实现表示。下图表示每个顾客都有一个地址,这通过让 Customer 类持有一个类型为 Address 的成员变量类实现。
2, 双向关联: 在 UML 类图中,双向关联用一个不带箭头的直线表示。下图中在 Customer 类中维护一个 List<Product> ,表示一个顾客可以购买多个商品;在 Product 类中维护一个 Customer 类型的成员变量表示这个产品被哪个顾客所购买。
3, 自关联: 在 UML 类图中用一个带有箭头且指向自身的线表示。下图的意思就是 Node 类包含类型为 Node 的成员变量,也就是“自己包含自己”。
2.2.2.2 聚合关系
聚合关系是关联关系的一种,是强关联关系,是整体和局部之间的关系。
聚合关系也是通过成员对象来实现的,其中成员对象是整体对象的一部分,但是成员对象可以脱离整体对象而独立存在。例如,学校与老师的关系,学校包含老师,但如果学校停办了,老师依然存在。
在 UML 图中,聚合关系可以用带空心菱形的实线来表示,菱形指向整体。下图所示是大学和教师的关系图:
2.2.2.3 组合关系
组合表示类之间的整体与部分的关系,但它是一种更强烈的聚合关系。
在组合关系中,整体对象可以控制部分对象的生命周期,一旦整体对象不存在,部分对象也将不存在,部分对象不能脱离整体对象而存在。例如,头和脑的关系,没有了头,嘴也就不存在了。
在 UML 图中,组合关系用带实心菱形的实线来表示,菱形指向整体。下图所示是头和嘴的关系图:
2.2.2.4 依赖关系
依赖关系是一种使用关系,它是对象之间耦合度最弱的一种关联方式,是临时性的关联。在代码中,某个类的方法通过局部变量、方法的参数或者对静态方法的调用来访问另一个类(被依赖类)中的某些方法来完成一些职责。
在 UML 类图中,依赖关系使用带箭头的虚线来表示,箭头从使用类指向被依赖的类。下图所示是司机和汽车的关系图,司机驾驶骑车:
2.2.2.5 继承关系
继承关系是对象之间耦合度最大的一种关系,表示一般与特殊的关系,是父类与子类之间的关系,是一种继承关系。
在 UML 类图中,泛化关系用带空心三角箭头的实线来表示,箭头从子类指向父类。在代码实现时,使用面向对象的继承机制来实现泛化关系。例如,Student 类和 Teacher 类都是 Person 类的子类。其类图如下图所示:
2.2.2.6 实现关系
实现关系是接口与实现类之间的关系。在这种关系中,类实现了接口,类中的操作实现了接口中所声明的所有的抽象操作。
在 UML 类图中,实现关系使用带空心三角形箭头的虚线来表示,箭头从实现类指向接口。例如,汽车和船实现了交通工具,其类图如下图所示。
3. 软件设计原则
在软件开发中,为了提高软件系统的可维护性和可复用性,增加软件的可扩展性和灵活性,程序员要尽量根据 6 条原则来开发程序,从而提高软件开发效率、节约软件开发成本和维护成本。
3.1 开闭原则
对扩展开放,对修改关闭。
在程序需要进行拓展的时候,不能去修改原有的代码,实现一个热插拔的效果。简言之,是为了使程序的扩展性好,易于维护和升级。
想要达到这样的效果,我们需要使用接口和抽象类。
因为抽象灵活性好,适应性广,只要抽象的合理,可以基本保持软件架构的稳定。而软件中易变的细节可以从抽象派生来的实现类来进行扩展,当软件需求发生变化时,只要根据需求重新派生一个实现类来扩展就可以了。
开闭原则的应用:
3.2 里氏代换原则
里氏代换原则是面向对象设计的基本原则之一。
里氏代换原则:任何基类可以出现的地方,子类一定可以出现。通俗理解:子类可以扩展父类的功能,但不能改变父类原有的功能。换句话说,子类继承父类时,除添加新的方法完成新增功能外,尽量不要重写父类的方法。
如果通过重写父类的方法来完成新的功能,这样写起来虽然简单,但是整个继承体系的可复用性会比较差,特别是运用多态比较频繁时,程序运行出错的概率会非常大。
里氏代换原则应用:正方形不是长方形
3.3 依赖倒转原则
高层模块不应该依赖底层模块,两者都应该依赖其抽象;抽象不应该依赖细节,细节应该依赖抽象。简单的说就是要求对抽象进行编程,不要对实现进行编程,这样就降低了客户与实现模块间的耦合。
依赖倒转原则应用:
3.4 接口隔离原则
客户端不应该被迫依赖于它不使用的方法:一个类对另一个类的依赖应该建立在最小的接口上。
接口隔离原则的应用:
3.5 迪米特法则
迪米特法则又叫最少知识原则。
只和你的直接朋友交谈,不跟 “陌生人” 说话 (Talk only to your immediate friends and not to strangers)。
其含义是:如果两个软件实体无须直接通信,那么就不应当发生直接的相互调用,可以通过第三方转发该调用。其目的是降低类之间的耦合度,提高模块的相对独立性。
迪米特法则中的 “朋友” 是指:当前对象本身、当前对象的成员对象、当前对象所创建的对象、当前对象的方法参数等;这些对象同当前对象存在关联、聚合或组合关系,可以直接访问这些对象的方法。
3.6 合成复用原则
合成复用原则是指:尽量先使用组合或者聚合等关联关系来实现,其次才考虑使用继承关系来实现。
通常类的复用分为继承复用和合成复用两种。
继承复用虽然有简单和易实现的优点,但它也存在以下缺点:
- 继承复用破坏了类的封装性。因为继承会将父类的实现细节暴露给子类,父类对子类是透明的,所以这种复用又称为 “白箱” 复用。
- 子类与父类的耦合度高,父类的实现的任何改变都会导致子类的实现发生变化,这不利于类的扩展与维护。
- 它限制了复用的灵活性。从父类继承而来的实现是静态的,在编译时已经定义,所以在运行时不可能发生改变。
采用组合或聚合复用时,可以将已有对象纳入新对象中,使之成为新对象的一部分,新对象可以调用已有对象的功能,它有以下优点:
- 它维持了类的封装性。因为成分对象的内部细节是新对象看不见的,所以这种复用又称为 “黑箱” 复用。
- 对象间的耦合度低。可以在类的成员位置声明抽象。
- 复用的灵活性高。这种复用可以在运行时动态进行,新对象可以动态地引用与成分对象类型相同的对象。
合成复用原则应用:
继承复用:
组合或聚合复用示例:
二. 创建者模式(5种)
创建模式的主要关注点是 “怎样创建对象?”,它的主要特点是 “将对象的创建与使用分离”。
这样可以降低系统的耦合度,使用者不需要关注对象的创建细节。
创建模式分为:
- 单例模式
- 工厂方法模式
- 抽线工程模式
- 原型模式
- 建造者模式
4.1 单例设计模式
单例模式 (Singleton Pattern) 是 Java 中最简单的设计模式之一。这种类型的设计模式属于创建型设计模式,它提供了一种创建对象的最佳方式。
这种模式涉及到一个单一的类,该类负责创建自己的对象,同时确保只有单个对象被创建。这个类提供了一种访问其唯一的对象的方式,可以直接访问,不需要实例化该类的对象。
4.1.1 单例模式的结构
单例模式主要有以下角色:
- 单例类。只能创建一个实例的类
- 访问类。使用单例类
4.1.2 单例模式的实现
单例设计模式分类两种:
- 饿汉式: 类加载就会导致该单实例对象被创建。
- 懒汉式: 类加载不会导致该单实例对象被创建,而是首次使用该对象时才会创建。
饿汉式实现的实例:
/**
* @Description 单例模式:饿汉式 静态成员变量
* @Author 高建伟-joe
* @Date 2023-12-27
*/
public class Singleton {
// 1.私有构造方法
private Singleton(){}
// 2.在本类中创建本类对象
private static Singleton instance = new Singleton();
// 3.提供一个公共的访问方法,让外界获取该对象
public static Singleton getInstance(){
return instance;
}
}
/**
* @Description 单例模式:饿汉式 静态代码块
* @Author 高建伟-joe
* @Date 2023-12-27
*/
public class Singleton {
// 1.私有构造方法
private Singleton(){}
// 2.声明Singleton类型的变量
private static Singleton instance;
// 3.在静态代码块中赋值
static {
instance = new Singleton();
}
// 4.对外提供获取该类对象的方法
public static Singleton getInstance(){
return instance;
}
}
提示: \color{red}{提示:} 提示: instance 对象是随着类的加载而创建的。如果该对象足够大的话,而一直没有使用就会造成内存的浪费。
懒汉式实现实例:
/**
* @Description 懒汉式 线程不安全
* @Author 高建伟-joe
* @Date 2023-12-27
*/
public class Singleton {
// 1.私有构造方法
private Singleton(){}
// 2.声明Singleton类型的变量
private static Singleton instance;
// 3.对外提供访问方式
public static Singleton getInstance(){
if (instance == null){
// 线程1等待,线程2获取到cpu的执行权,也会进入到该判断里面
instance = new Singleton();
}
return instance;
}
}
提示: \color{red}{提示:} 提示: 线程不安全
/**
* @Description 懒汉式 线程安全
* @Author 高建伟-joe
* @Date 2023-12-27
*/
public class Singleton {
// 1.私有构造方法
private Singleton(){}
// 2.声明Singleton类型的变量
private static Singleton instance;
// 3.对外提供访问方式
public static synchronized Singleton getInstance(){
if (instance == null){
// 线程1等待,线程2获取到cpu的执行权,会等待线程1执行完
instance = new Singleton();
}
return instance;
}
}
提示: \color{red}{提示:} 提示: 线程安全,性能不高
/**
* @Description 懒汉式 双重检查锁
* @Author 高建伟-joe
* @Date 2023-12-27
*/
public class Singleton {
// 1.私有构造方法
private Singleton(){}
// 2.声明Singleton类型的变量
private static Singleton instance;
// 3.对外提供访问方式
public static Singleton getInstance(){
// 第一次判断,如果 instance 的值不为 null, 不需要抢占锁,直接返回对象
if (instance == null){
synchronized (Singleton.class){
if (instance == null){
instance = new Singleton();
}
}
}
return instance;
}
}
提示: \color{red}{提示:} 提示: 线程安全、性能不错,但是在多线程情况下,会出现空指针问题,原因是 JVM 在实例化对象的时候会进行优化和指令重排序操作。
/**
* @Description 懒汉式 双重检查锁
* @Author 高建伟-joe
* @Date 2023-12-27
*/
public class Singleton {
// 1.私有构造方法
private Singleton(){}
// 2.声明Singleton类型的变量
private static volatile Singleton instance;
// 3.对外提供访问方式
public static Singleton getInstance(){
// 第一次判断,如果 instance 的值不为 null, 不需要抢占锁,直接返回对象
if (instance == null){
synchronized (Singleton.class){
if (instance == null){
instance = new Singleton();
}
}
}
return instance;
}
}
提示: \color{red}{提示:} 提示: 添加 volatile 关键字之后的双重检查锁模式是一种比较好的单例实现模式,能够保证在多线程的情况下线程安全也不会有性能问题。
/**
* @Description 懒汉式 静态内部类的方式
* 静态内部类单例模式中实例由内部类创建,
* 由于 JVM 在加载外部类的过程中,是不会加载静态内部类的,只有内部类的属性/方法被调用时才会被加载,并初始化其静态属性。
* 静态属性由于被 static 修饰,保证只被实例化一次,并且严格保证实例化顺序。
* @Author 高建伟-joe
* @Date 2023-12-27
*/
public class Singleton {
// 1. 私有构造方法
private Singleton(){}
//2. 静态内部类中创建对象
private static class SingletonHolder{
private static final Singleton INSTANCE = new Singleton();
}
// 3. 对外提供静态方法获取该对象
public static Singleton getInstance(){
return SingletonHolder.INSTANCE;
}
}
提示: \color{red}{提示:} 提示: 第一次加载 Singleton 类时不会去初始化 INSTANCE,只有第一次调用 getInstance,虚拟机加载 SingletonHolder 并初始化 INSTANCE,这样不仅能保证线程安全,也能保证 Singleton 类的唯一性。
小结: 静态内部类单例模式是一种优秀的单例模式,是开源项目中比较常用的一种单例模式。在没有加任何锁的情况下,保证了多线程下的安全,并且没有任何性能影响和空间浪费。
/**
* @Description 饿汉式 枚举方式
* @Author 高建伟-joe
* @Date 2023-12-27
*/
public enum Singleton {
INSTANCE;
}
枚举方式:枚举类实现单例模式是极力推荐的单例实现模式,因为枚举类型是线程安全的,并且只会装载一次,设计者充分的利用了枚举的这个特性来实现单例模式,枚举的写法非常简单,而且枚举类型是所用单例实现中唯一一种不会被破坏的单例实现模式。
4.1.3 存在的问题
破坏单例模式: 使单例类可以创建多个对象,枚举方式除外。有两种方式,分别是序列化和反射。
4.1.3.1 问题
序列化反序列化:
/**
* @Description 懒汉式 静态内部类
* @Author 高建伟-joe
* @Date 2023-12-28
*/
public class Singleton implements Serializable {
private Singleton(){}
private static class SingletonHolder{
private static final Singleton INSTANCE = new Singleton();
}
public static Singleton getInstance(){
return SingletonHolder.INSTANCE;
}
}
/**
* @Description 序列化和反序列化 破坏单例类 测试类
* @Author 高建伟-joe
* @Date 2023-12-28
*/
public class Client {
public static void main(String[] args) throws Exception {
// writeObj2File();
readObjFromFile();
readObjFromFile();
}
// 向文件中写对象
public static void writeObj2File() throws Exception{
Singleton singleton = Singleton.getInstance();
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("./a.txt"));
oos.writeObject(singleton);
oos.close();
}
// 从文件中读对象
public static void readObjFromFile() throws Exception{
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("./a.txt"));
Singleton singleton = (Singleton) ois.readObject();
System.out.println(singleton);
ois.close();
}
}
反射:
/**
* @Description 懒汉式 静态内部类
* @Author 高建伟-joe
* @Date 2023-12-28
*/
public class Singleton {
private Singleton(){}
private static class SingletonHolder{
private static final Singleton INSTANCE = new Singleton();
}
public static Singleton getInstance(){
return SingletonHolder.INSTANCE;
}
}
/**
* @Description 反射 破坏单例模式 测试类
* @Author 高建伟-joe
* @Date 2023-12-28
*/
public class Client {
public static void main(String[] args) throws Exception {
// 1.获取Singleton 的字节码对象
Class<Singleton> clazz = Singleton.class;
// 2.获取无参构造方法
Constructor<Singleton> declaredConstructor = clazz.getDeclaredConstructor();
// 3.取消访问检查
declaredConstructor.setAccessible(true);
// 4.创建 Singleton 对象
Singleton singleton = declaredConstructor.newInstance();
Singleton singleton1 = declaredConstructor.newInstance();
System.out.println(singleton == singleton1);
}
}
4.1.3.2 解决
序列化和反序列化方式破坏单例模式的解决方法:在 Singleton 类中添加 readResolve() 方法,在反序列化时被反射调用,如果定义了这个方法,就返回这个方法的值,如果没有定义,则返回新 new 出来的对象。
/**
* @Description 懒汉式 静态内部类
* @Author 高建伟-joe
* @Date 2023-12-28
*/
public class Singleton implements Serializable {
private Singleton(){}
private static class SingletonHolder{
private static final Singleton INSTANCE = new Singleton();
}
public static Singleton getInstance(){
return SingletonHolder.INSTANCE;
}
// 当进行反序列化时,会自动调用该方法,将该方法的返回值直接返回。
public Object readResolve(){
return SingletonHolder.INSTANCE;
}
}
反射方式破解单例模式的解决方法:
/**
* @Description 懒汉式 静态内部类
* @Author 高建伟-joe
* @Date 2023-12-28
*/
public class Singleton {
private static boolean flag = false;
private Singleton(){
synchronized (Singleton.class){
// 判断 flag 的值是否为 true,如果是 true,说明非第一次访问,直接抛一个异常,如果是 false ,说明是第一次访问。
if (flag){
throw new RuntimeException("不能创建多个对象");
}
// 将 flag 的值设为 true
flag = true;
}
}
private static class SingletonHolder{
private static final Singleton INSTANCE = new Singleton();
}
public static Singleton getInstance(){
return SingletonHolder.INSTANCE;
}
}
4.1.4 JDK源码解析- Runtime 类
Runtime 类使用的设计模式是单例模式:饿汉式 静态成员
/**
* Every Java application has a single instance of class
* <code>Runtime</code> that allows the application to interface with
* the environment in which the application is running. The current
* runtime can be obtained from the <code>getRuntime</code> method.
* <p>
* An application cannot create its own instance of this class.
*
* @author unascribed
* @see java.lang.Runtime#getRuntime()
* @since JDK1.0
*/
public class Runtime {
private static Runtime currentRuntime = new Runtime();
/**
* Returns the runtime object associated with the current Java application.
* Most of the methods of class <code>Runtime</code> are instance
* methods and must be invoked with respect to the current runtime object.
*
* @return the <code>Runtime</code> object associated with the current
* Java application.
*/
public static Runtime getRuntime() {
return currentRuntime;
}
/** Don't let anyone else instantiate this class */
private Runtime() {}
}
Runtime 类的简单使用:
/**
* @Description Runtime 类的使用
* @Author 高建伟-joe
* @Date 2023-12-28
*/
public class RuntimeDemo {
public static void main(String[] args) throws Exception {
Runtime runtime = Runtime.getRuntime();
// 返回 java 虚拟机中的内存总量
System.out.println(runtime.totalMemory());
// 返回 java 虚拟机试图使用的最大内存量
System.out.println(runtime.maxMemory());
// 调用 runtime 的 exec 方法,参数是一个命令
Process ipconfig = runtime.exec("ipconfig");
// Process 对象的获取输入流的方法
InputStream inputStream = ipconfig.getInputStream();
byte[] arr = new byte[1024 * 1024 * 100];
// 读取数据
int len = inputStream.read(arr); // 返回读到的字节个数
// 将字节数组转化为字符串输出到控制台
System.out.println(new String(arr,0, len, "GBK"));
}
}
4.2 工厂模式
4.2.1 概述
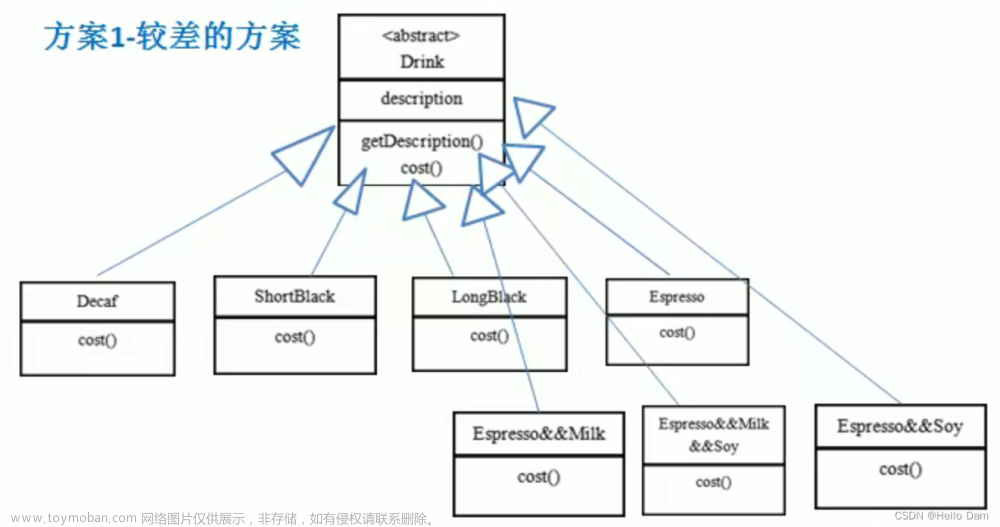
需求:设计一个咖啡店点餐系统。
在 Java 中,万物皆对象,这些对象都需要创建,如果创建的时候直接 new 该对象,就会对该对象耦合严重,假如我们要更换对象,所有 new 对象的地方都需要修改一遍,这显然违背了软件设计的开闭原则。如果我们使用工厂来生产对象,我们就只和工厂打交道就可以了,彻底和对象解耦,如果要更换对象,直接在工厂里更换该对象即可,达到了与对象解耦的目的;所以说,工厂模式最大的优点就是:解耦。
本文介绍 3 种工厂模式的使用:
- 简单工厂模式 (不属于 GOF 的 23 种经典设计模式)
- 工厂方法模式
- 抽象工厂模式
4.2.2 简单工厂模式
简单工厂不是一种设计模式,反而比较像是一种编程习惯。
4.2.2.1 结构
简单工厂包含以下角色:
- 抽象产品: 定义了产品的规范,描述了产品的主要特性和功能。
- 具体产品: 实现或继承抽象产品的子类
- 具体工厂: 提供创建产品的方法,调用者通过该方法来获取产品。
4.2.2.2 实现
使用简单工厂对上面示例进行该进,类图如下:
工厂 (factory) 处理创建对象的细节,一旦有了 SimpleCoffeFactory, CoffeeStore 类中的 orderCoffee() 就变成了此对象的客户,后期如果需要 Coffee 对象直接从工厂中获取即可。这样就解除了和 Coffee 实现类的耦合,同时又产生了新的耦合,CoffeeStore 对象和 SimpleCoffeeFactory 工厂对象的耦合,工厂对象和商品对象的耦合。
后期如果再加新品种的咖啡,我们势必要求修改 SimpleCoffeeFactory 的代码,违反了开闭原则。工厂类的客户端可能有很多,比如新建一个店等,这样只需要修改工厂类的代码,省去其他的修改操作。
4.2.2.3 扩展
静态工厂:在开发中也有一部分人将工厂类的创建对象的功能定义为静态的,这个就是静态工厂模式,它也不是 23 种设计模式中的。代码如下
/**
* @Description
* @Author 高建伟-joe
* @Date 2023-12-28
*/
public class SimpleCoffeeFactory {
public static Coffee createCoffee(String type){
Coffee coffee = null;
if ("American".equals(type)){
coffee = new AmericanCoffee();
} else if ("Latte".equals(type)){
coffee = new LatteCoffee();
} else {
throw new RuntimeException("您点的咖啡,没有了");
}
return coffee;
}
}
4.2.2.4 优点和缺点
优点: 封装了创建对象的过程,可以通过参数直接获取对象。把对象的创建和业务逻辑层分开,这样以后就避免了修改客户代码,如果要实现新产品直接修改工厂类,而不需要在原代码中修改,这样就降低了客户代码修改的可能性,更加容易扩展。
缺点: 增加新产品时还是需要修改工厂类的代码,违背了“开闭原则”。
4.2.3 工厂方法模式
针对上例中的缺点,使用工厂方法模式就可以完美解决,完全遵循开闭原则。
4.2.3.1 概念
定义一个用于创建对象的接口,让子类决定实例化哪个产品类对象。工厂方法使一个产品类的实例化延迟到其工厂的子类。
4.2.3.2 结构
工厂方法模式中的主要角色:
- 抽象工厂(Abstract Factory): 提供了创建产品的接口,调用者通过它访问具体工厂的工厂方法来创建产品。
- 具体工厂(Concrete Factory): 主要实现抽象工厂中的抽象方法,完成具体产品的创建。
- 抽象产品(Product): 定义了产品的规范,描述了产品的主要特性和功能。
- 具体产品(Concrete Product): 实现了抽象产品所定义的接口,由具体工厂来创建,它同具体工厂一一对应。
4.2.3.3 实现
使用工厂方法模式对上例进行改进,类图如下:
从以上的编写的代码可以看到,要增加产品类时也要相应地增加工厂类,不需要修改工厂类的代码了,这样就解决了简单工厂模式的缺点。
工厂方法模式是简单工厂模式的进一步抽象。由于使用了多态性,工厂方法模式保持了简单工厂模式的优点,而且克服了它的缺点。
4.2.3.4 优缺点
优点:
- 用户只需要知道具体工厂的名称就可得到所要的产品,无须知道产品的具体创建过程;
- 在系统增加新的产品时只需要添加具体产品类和对应的具体工厂类,无须对原工厂进行任何修改,满足开闭原则。
缺点:文章来源:https://www.toymoban.com/news/detail-806980.html
- 每增加一个产品就要增加一个具体产品类和一个对应的具体工厂类,这增加了系统的复杂度。
4.2.4 抽象工厂模式
前面介绍的工厂方法模式中考虑的是一类产品的生产,如畜牧场只养动物、电视机场只生产电视等。
这些工厂只生产同种类产品,同种类产品称为同等级产品,也就是说:工厂方法模式只考虑生产同等级产品,但是在现实生活中许多工厂是综合型的工厂,能生产多等级(种类)的产品,如电器厂既生产电视机又生产洗衣机或空调等。
本节要介绍的抽象工厂模式将考虑多等级产品的生产,将同一个具体工厂所生产的位于不同等级的一组产品称为一个产品族,下图所示横轴是产品等级,也就是同一类产品;纵轴是产品族,也就是同一品牌的产品,同一品牌的产品产自同一工厂。
4.2.4.1 概念
是一种为访问类提供一个创建一组相关或相互依赖对象的接口,且访问类无须指定所要产品的具体类就能得到同族的不同等级的产品的模式结构。
抽象工厂模式是工厂方法模式的升级版本,工厂方法模式只生产一个等级的产品,而抽象工厂模式可生产多个等级的产品。
4.2.4.2 结构
抽象工厂模式的主要角色如下:
- 抽象工厂(Abstract Factory): 提供了创建产品的接口,它包含多个创建产品的方法,可以创建多个不同等级的产品。
- 具体工厂(Concrete Factory): 主要是实现抽象工厂中的多个抽象方法,完成具体产品的创建。
- 抽象产品(Product): 定义了产品的规范,描述了产品的主要特性和功能,抽象工厂模式有多个抽象产品。
- 具体产品(Concrete Product): 实现了抽象产品角色所定义的接口,由具体工厂来创建,它同具体工厂之间是多对一的关系。
4.2.4.3 实现
使用抽象工厂模式实现,类图如下:
使用抽象工厂模式,如果要加同一个产品族的话,只需要再加一个对应的工厂类即可,不需要修改其他的类。
4.2.4.4 优缺点
优点: 当一个产品族中的多个对象被设计成一起工作时,它能保证客户端始终只使用同一个产品族中的对象。
缺点: 当产品族中需要添加一个新产品时,所有的工厂类都需要进行修改。
4.2.4.5 使用场景
当需要创建的对象是一系列相互关联或相互依赖的产品族时,如电器工厂中的电视机、洗衣机、空调等。
系统中有多个产品族,但每次只使用其中的某一族产品。如有人只喜欢穿某一个品牌的衣服和鞋。
系统中提供了产品的类库,且所有产品的接口相同,客户端不依赖产品实例的创建细节和内部结构。
如:输入法换皮肤,一整套一起换。生成不同操作系统的程序。
4.2.5 模式扩展
简单工厂 + 配置文件解除耦合
可以通过工厂模式 + 配置文件的方式解除工厂对象和产品对象的耦合。在工厂类中加载配置文件中的全类名,并创建对象进行存储,客户端如果需要对象,直接进行获取即可。
4.2.6 JDK 源码分析-Collection.iterator 方法
单列集合获取迭代器的方法就使用到了工厂方法模式。类图如下:
Collection 接口是抽象工厂类,ArrayList是具体的工厂类,Iterator 接口是抽象产品类,ArrayList类中的Iter内部类是具体的产品类。在具体的工厂类中 iterator() 方法创建具体的产品类的对象。
DateForamt 类中的 getInstance() 方法使用的是工厂模式。
Calendar 类中的 getInstance() 方法使用的是工厂模式。
4.3 原型模式
4.3.1 概述
用一个已经创建的实例作为原型,通过复制该原型对象来创建一个和原型对象相同的新对象。
4.3.2 结构
原型模式包含以下角色:
- 抽象原型类: 规定了具体原型对象必须实现的 clone() 方法。
- 具体原型类: 实现抽象原型类的 clone() 方法,它是可被复制的对象。
- 访问类: 使用具体原型类中的 clone() 方法来复制新的对象。
接口类图如下:
4.3.3 实现
原型模式的克隆分为浅克隆和深克隆。
浅克隆: 创建一个新对象,新对象的属性和原来对象完全相同,对于非基本类型的属性,仍指向原有属性所指向的对象的内存地址。
深克隆: 创建一个新对象,属性中引用的其他对象也会被克隆,不会指向原有对象地址。
Java 中的 Object 类中提供了 clone() 方法来实现浅克隆。Cloneable 接口是上面的类图中的抽象原型类,而实现了 Cloneable 接口的子实现类就是具体的原型类。
4.3.5 使用场景
- 对象的创建非常复杂,可以使用原型模式快捷的创建对象。
- 性能和安全要求比较高。
4.3.6 扩展(深克隆)
进行深克隆需要使用对象流。
4.4 建造者模式
4.4.1 概述
将一个复杂对象的构建与表示分离,使得同样的构建过程可以创建不同的表示。
- 分离了部件的构造(由 Builder 来负责)和装配(由 Director 负责)。从而可以构造出复杂对象。这个模式适用于: 某个对象的构建过程复杂的情况。
- 由于实现了构建和装配的解耦。不同的构建器,相同的装配,也可以做出不同的对象;相同的构建器,不同的装配顺序也可以做出不同的对象。也就是实现了构建算法、装配算法的解耦,实现了更好的复用。
- 建造者模式可以将部件和其组装过程分开,一步一步创建一个复杂的对象。用户只需要指定复杂对象的类型就可以得到该对象,而无须知道内部的具体够着细节。
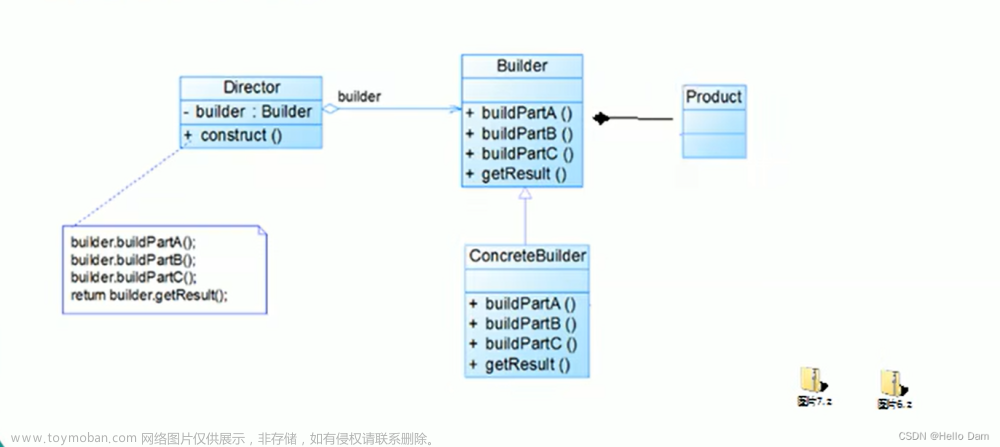
4.4.2 结构
建造者 (Builder) 模式包含如下角色:
- 抽象建造者类 (Builder): 这个接口规定要实现复杂对象的那些部分的创建,并不涉及具体的对象部件的创建。
- 具体建造者类 (Concrete Builder): 实现 Builder 接口,完成复杂产品的各个部件的具体创建方法。在构造过程完成后,提供产品的实例。
- 产品类 (Product): 要创建的复杂对象。
- 指挥者类 (Director): 调用具体建造者来创建复杂对象的各个部分,在指导者中不涉及具体产品的信息,只负责保证对象各个部分完整创建或按某种顺序创建。
类图如下:
4.4.3 实例
生产自行车。类图如下:
上面示例是 Builder 模式的常规用法,指挥者类 Director 在建造者模式中具有很重要的作用,它用于指导具体构建者如何构建产品,控制调用先后次序,并向调用者返回完整的产品类,但是有些情况下需要简化系统结构,可以把指挥者类和抽象建造者进行结合。
这样做确实简化了系统结构,但同时也加重了抽象建造者类的职责,也不是太符合单一职责原则,如果 construct() 过于复杂,建议还是封装到 Director 中。
/**
* @Description
* @Author 高建伟-joe
* @Date 2024-01-05
*/
public abstract class Builder {
protected Bike mbike = new Bike();
public abstract void buildFrame();
public abstract void buildSeat();
public abstract Bike createBike();
public Bike construct(){
this.buildSeat();
this.buildFrame();
return this.createBike();
}
}
4.4.4 优缺点
优点:
- 建造者模式的封装性很好。使用建造者模式可以有效的封装变化,在使用建造者模式的场景中,一般产品类和建造者类是比较稳定的,因此,将主要的业务逻辑封装在指挥者类中对整体而言可以取得比较好的稳定性。
- 在建造者模式中,客户端不必知道产品内部组成的细节,将产品本身与产品的创建过程解耦,使得相同的创建过程可以创建不同的产品对象。
- 可以更加精细地控制产品的创建过程。将复杂产品的创建步骤分解在不同的方法中,使得创建过程更加清晰,也更方便使用程序来控制创建过程。
- 建造者模式很容易进行扩展。如果有新的需求,通过实现一个新的建造者类就可以完成,基本上不用修改之前已经测试通过的代码,因此也就不会对原有功能引入风险。符合开闭原则。
缺点:
- 建造者模式所创建的产品一般具有较多的共同点,其组成部分相似,如果产品之间差异性很大,则不适合使用建造者模式,因此其使用范围受到一定的限制。
4.4.5 使用场景
建造者 (Builder) 模式创建的是复杂对象,其产品的各个部分经常面临着剧烈变化,但将它们组合在一起的算法缺相对稳定,所以它通常在以下场合使用:
- 创建对象较复杂,由多个部件构成,各部件面临着复杂的变化,但构件间的建造顺序是稳定的。
- 创建复杂对象的算法独立于该对象的组成部分以及它们的装配方式,即产品的构建过程和最终的表示是独立的。
4.4.6 模式扩展
建造者模式除了上面的用途外,在开发中还有一个常用的使用方式,就是当一个类构造器需要传入很多参数时,如果创建这个类的实例,代码可读性会非常差,而且很容易引入错误,此时就可以利用建造者模式进行重构。
/**
* @Description
* @Author 高建伟-joe
* @Date 2024-01-05
*/
public class Phone {
private String cpu;
private String screen;
private String memory;
private String mainboard;
@Override
public String toString() {
return "Phone{" +
"cpu='" + cpu + '\'' +
", screen='" + screen + '\'' +
", memory='" + memory + '\'' +
", mainboard='" + mainboard + '\'' +
'}';
}
private Phone(Builder builder){
this.cpu = builder.cpu;
this.screen = builder.screen;
this.memory = builder.memory;
this.mainboard = builder.mainboard;
}
public static final class Builder{
private String cpu;
private String screen;
private String memory;
private String mainboard;
public Builder cpu(String cpu){
this.cpu = cpu;
return this;
}
public Builder screen(String screen){
this.screen = screen;
return this;
}
public Builder memory(String memory){
this.memory = memory;
return this;
}
public Builder mainboard(String mainboard){
this.mainboard = mainboard;
return this;
}
public Phone build(){
return new Phone(this);
}
}
}
重构后的代码在使用起来更方便,某种程度上也可以提高开发效率。从软件设计上,对程序员的要求比较高。
4.5 创建者模式对比
4.5.1 工厂方法模式 vs 建造者模式
工厂方法模式注重的是整体对象的创建方式。
建造者模式注重的是部件构建的过程,意在通过一步一步地精确构造创建出一个复杂的对象。
4.5.2 抽象工厂模式 vs 建造者模式
抽象工厂模式实现对产品家族的创建,一个产品家族是这样的一系列产品,具有不同分类维度的产品组合,采用抽象工厂模式则是不需要关心构建过程,只关心什么产品由什么工厂生产即可。
建造者模式则是要求按照指定的蓝图建造产品,它的主要目的是通过组装零配件而产生一个新产品。
如果将抽象工厂模式看成汽车配件生产工厂,生产一个产品族的产品,那么建造者模式就是一个汽车组装厂,通过对部件的组装可以返回一辆完整的汽车。
三. 结构型模式(7种)
结构型模式描述如何将类或对象按某种布局组成更大的结构。它分为类结构型模式和对象结构型模式,前者采用继承机制来组织接口和类,后者采用组合或聚合来组合对象。
由于组合关系和聚合关系比继承关系耦合度低,满足"合成复用原则",所以对象结构型模式比类结构型模式具有更大的灵活性。
结构型模式分为以下 7 种:
- 代理模式
- 适配器模式
- 装饰者模式
- 桥接模式
- 外观模式
- 组合模式
- 享元模式
5.1 代理模式
5.1.1 概述
由于某些原因需要给对象提供一个代理以控制对该对象的访问。这时,访问对象不适合或者不能直接引用目标对象,代理对象作为访问对象和目标对象之间的中介。
Java 中的代理按照代理类的生成时机不同分为静态代理和动态代理。静态代理代理类在编译器就生成,而动态代理代理类则是在 Java 运行时动态生成。动态代理又有 JDK 代理和 CGLib 代理两种。
5.1.2 结构
代理(Proxy)模式分为三种角色:
- 抽象主题(Subject)类: 通过接口或抽象类声明真实主题和代理对象实现的业务方法。
- 真实主题(Real Subject)类: 实现了抽象主题中的具体业务,是代理对象所代表的真实对象,是最终要引用的对象。
- 代理(Proxy)类: 提供了与真实主题相同的接口,其内部含有对真实主题的引用,它可以访问、控制或扩展真实主题的功能。
5.1.3 静态代理
通过火车站卖票案例,来学习静态代理。
火车站是目标对象,代售点是代理对象。
5.1.4 JDK动态代理
JDK提供的动态代理:Java 中提供了一个动态代理类 Proxy,Proxy 并不是我们所说的代理对象的类,而是提供了一个创建代理对象的静态方法(newProxyInstance方法)来获取代理对象。
执行流程:
- 在测试类中通过代理对象调用 sell() 方法。
- 根据多态的特性,执行的是代理类中的 sell() 方法。
- 代理类中的 sell() 方法中又调用了 InvocationHandler 接口的子实现类对象的 invoke 方法。
- invoke 方法通过反射执行了真实对象所属类 (TrainStation) 中的 sell() 方法。
5.1.5 CGLib动态代理
如果没有定义 SellTickets 接口,只定义了 TrainStation。很显然 JDK 代理是无法使用了,因为 JDK 动态代理要求必须定义接口,对接口进行代理。
CGLib 是一个功能强大,高性能的代码生成包。它为没有实现接口的类提供代理,为 JDK 的动态代理提供了很好的补充。
CGLib 是第三方提供的包,所以需要引入 Jar 包
<dependency>
<groupId>cglib</groupId>
<artifactId>cglib</artifactId>
<version>2.2.2</version>
</dependency>
5.1.6 三种代理的对比
JDK代理和CFLib代理:
使用 CGLib 实现动态代理,CGLib 底层采用 ASM 字节码生成框架,使用字节码技术生成代理类,在 JDK1.6 之前比使用 Java 反射效率要高,唯一需要注意的是,CGLib 不能对声明为 final 的类或者方法进行处理,因为 CGLib 原理是动态生成被代理类的子类。
在 JDK1.6、JDK1.7、JDK1.8逐步对JDK动态代理优化之后,在调用次数较少的情况下,JDK代理效率高于 CGLib 代理效率,只有当进行大量调用的时候,JDK1.6和JDK1.7比CGLib代理效率低一点,但是到JDK1.8的时候,JDK代理效率高于CGLib代理,所以如果有接口使用JDK动态代理,如果没有接口使用CGLib代理。
动态代理和静态代理:
动态代理和静态代理相比较,最大的好处是接口中声明的所有方法都被转移到调用处理器一个集中的方法中处理(InvocationHandler.invoke)。这样,在接口方法数量比较多的时候,我们可以进行灵活处理,而不需要像静态代理那样每一个方法进行中转。
如果接口每增加一个方法,静态代理模式除了所有实现类需要实现这个方法外,所有代理类也需要实现此方法。增加了代码维护的复杂度。而动态代理不会出现该问题。
5.1.7 优缺点
优点:
- 代理模式在客户端与目标对象之间起到一个中介作用和保护目标对象的作用。
- 代理对象可以扩展目标对象的功能。
- 代理模式能将客户端与目标对象分离,在一定程度上降低了系统的耦合度。
缺点:
- 增加了系统的复杂度。
5.1.8 使用场景
- 远程(Remote)代理: 本地服务通过网络请求远程服务。为了实现本地到远程的通信,我们需要实现网络通信,处理其中可能的异常。为良好的代码设计和可维护性,我们将网络通信部分隐藏起来,只暴露给本地服务一个接口,通过该接口即可访问远程服务提供的功能,而不必过多关心通信部分的细节。
- 防火墙(Firewall)代理: 当你将浏览器配置成使用代理功能时,防火墙能将你的浏览器的请求转给互联网,当互联网返回响应时,代理服务器再把它转给你的浏览器。
- 保护(Protect of Access)代理: 控制对一个对象的访问,如果需要,可以给不同的用户提供不同级别的使用权限。
5.2 适配器模式
5.2.1 概述
适配器模式: 将一个类的接口转换成客户希望的另一个接口,使原本由于接口不兼容而不能一起工作的那些类能一起工作。
适配器模式分为类适配器模式和对象适配器模式,前者类之间的耦合度比后者高,且要求程序员了解现有组件库中的相关组件的内部结构,所以应用相对较少些。
5.2.2 结构
适配器模式(Adapter)包含以下主要角色:
- 目标(Target)接口: 当前系统业务所期待的接口,它可以是抽象类或接口。
- 适配者(Adaptee)类: 它是被访问和适配的现存组件库中的组件接口。
- 适配器(Adapter)类: 它是一个转换器,通过继承或引用适配者的对象,把适配者接口转换为目标接口,让客户按目标接口的格式访问适配者。
5.2.3 类适配器模式
实现方式: 定义一个适配器类来实现当前系统的业务接口,同时继承现有组件库中已经存在的组件。
类适配器模式违背了合成复用原则。类适配器是客户类有一个接口规范的情况下可用,反之不可用。
5.2.4 对象适配器模式
实现方式: 对象适配器模式可采用将现有组件库中已经实现的组件引入适配器类中,该类同时实现当前系统的业务接口。
注意: 还有一个适配器模式是接口适配器模式。当不希望实现接口中所有的方法时,可以创建一个抽象类 Adapter,实现所有方法。而此时我们只需要继承该抽象类即可。
5.2.5 应用场景
- 以前开发的系统存在满足新系统功能需求的类,但其接口同新系统的接口不一致。
- 使用第三方提供的组件,但组件接口定义和自己要求的接口定义不同。
5.2.6 JDK 源码解析
Reader(字符流)、InputStream(字节流) 的适配使用的是 InputStreamReader。
InputStreamReader 继承自 java.io 包中的 Reader,对其中抽象的未实现的方法给出实现。
从上图可以看出:
- InputStreamReader 是对同样实现了 Reader 的 StreamDecoder 的封装。
- StreamDecoder 不是 Java SE API 中的内容,是 SUN JDK 给出的自身实现。但我们知道他们对构造方法中的字节流类 InputStream 进行封装,并通过该类进行了字节流和字符流之间的解码转换。
结论:从表层来看,InputStreamReader 做了 InputStream 字节流类到 Reader 字符流之间的转换。而从如上 Sun JDK 中的实现类关系结构中可以看出,是 StreamDecoder 的设计实现在实际上采用了适配器模式。
5.3 装饰者模式
5.3.1 概述
装饰者模式:是指在不改变现有对象结构的情况下,动态地给对象增加一些职责(即增加额外功能)的模式。
5.3.2 结构
装饰(Decorator)模式中的角色:
- 抽象构件(Component)角色: 定义一个抽象接口以规范准备接收附加责任的对象。
- 具体构件(Concrete Component)角色: 实现抽象构建,通过装饰角色为其添加一些职责。
- 抽象装饰(Decorator)角色: 继承或实现抽象构件,并包含具体构件的实例,可以通过其子类扩展具体构件的功能。
- 具体装饰(Concrete Decorator)角色: 实现抽象装饰的相关方法,并给具体构件对象添加附加的责任。
5.3.3 案例
案例:快餐店
好处:
- 装饰者模式可以带来比继承更灵活性的扩展功能,使用更加方便,可以通过组合不同的装饰者对象来获取具有不同行为状态的多样化的结果。装饰者模式比继承更具良好的扩展性,完美的遵循开闭原则,继承是静态的附加责任,装饰者是动态的附加责任。
- 装饰类和被装饰类可以独立发展,不会相互耦合,装饰模式是继承的一个替代模式,装饰模式可以动态扩展一个实现类的功能。
5.3.4 使用场景
- 当不能采用继承的方式对系统进行扩充或者采用继承不利于系统扩展和维护时。
- 在不影响其他对象的情况下,以动态、透明的方式给单个对象添加职责。
- 当对象的功能要求可以动态地添加,也可以再动态地撤销时。
不采用继承的情况主要有两类:
- 第一类是系统中存在大量独立的扩展,为支持每一种组合将产生大量的子类,使得子类数目呈爆炸性增长。
- 第二类是因为类定义不能继承(如 final 类)
5.3.5 JDK源码解析
IO 流中的包装类使用到了装饰者模式。BufferedInputStream,BufferedOutputStream,BufferedReader,BufferedWriter
BufferedWriter 类图
BufferedWriter 使用装饰者模式对 Writer 子实现类进行了增强,增加了缓冲区,提高了写数据的效率。
5.3.6 代理和装饰者的区别
静态代理和装饰者模式的区别:
相同点:
- 都要实现与目标类相同的业务接口。
- 在两个类中都要声明目标对象。
- 都可以在不修改目标类的前提下增强目标方法。
不同点:
- 目的不同:装饰者是为了增强目标对象。静态代理是为了保护和隐藏目标对象。
- 获取目标对象构建的地方不同:装饰者是由外界传递进来,可以通过构造方法来传递。静态代理是在代理类内部创建,以此来隐藏目标对象。
5.4 桥接模式
5.4.1 概述
桥接模式:将抽象与实现分离,使它们可以独立变化。它使用组合关系代替继承关系来实现,从而降低了抽象和实现这两个可变维度的耦合度。
5.4.2 结构
桥接(Bridge)模式包含以下主要角色:
- 抽象化(Abstraction)角色: 定义抽象类,并包含对实现化对象的引用。
- 扩展抽象化(Refined Abstraction)角色: 是抽象化角色的子类,实现父类中的业务方法,并通过组合关系调用实现化角色中的业务员方法。
- 实现化(Implementor)角色: 定义实现化角色的接口,供扩展抽象化角色调用。
- 具体实现化(Concrete Implementor)角色: 给出实现化接口的具体实现。
5.4.3 案例
视频播放器 实例
桥接模式的好处:
- 桥接模式提高了系统的可扩充性,在两个变化维度中任意扩展一个维度,都不需要修改原有系统。如:如果现在还有一种视频文件类型 wmv, 我们只需要再定义一个类实现 VideoFile 接口即可,其他类不需要发生变化。
- 实现细节对客户透明。
5.4.4 使用场景
- 当一个类存在两个独立变化的维度,且这两个维度都需要进行扩展时。
- 当一个系统不希望使用继承或因为多层次继承导致系统类的个数急剧增加时。
- 当一个系统需要在构件的抽象化角色和具体化角色之间增加更多灵活性时。避免在两个层之间建立静态的继承联系,通过桥接模式可以使它们在抽象层建立一个关联关系。
5.5 外观模式
5.5.1 概述
外观模式,又名门面模式,是一种通过多个复杂的子系统提供一个一致的接口,而使这些子系统更加容易被访问的模式。
该模式对外有一个统一的接口,外部应用程序不用关心内部子系统的具体的细节,这样会大大降低应用程序的复杂度,提高了程序的可维护性。
外观(Facade)模式是 “迪米特法则” 的典型应用。
5.5.2 结构
外观(Facade)模式主要包含以下角色:
- 外观(Facade)角色: 为多个子系统对外提供一个共同的接口。
- 子系统(Sub System)角色: 实现系统的部分功能,客户可以通过外观角色访问它。
5.5.3 案例
实例:智能家电控制
优点:
- 降低了子系统和客户端之间的耦合度,使得子系统的变化不会影响调用它的客户类。
- 对客户屏蔽了子系统组件,减少了客户处理的对象数目,并使得子系统使用起来更加容易。
缺点: 不符合开闭原则,修改很麻烦。
5.5.4 使用场景
- 对分层结构系统构建时,使用外观模式定义子系统中每层的入口点可以简化子系统之间的依赖关系。
- 当一个复杂系统的子系统很多时,外观模式可以为系统设计一个简单的接口供外界访问。
- 当客户端与多个子系统之间存在很大的联系时,引入外观模式可将它们分离,从而提高子系统的独立性和可移植性。
5.5.5 源码解析
RequestFacade 类使用了外观模式。
为什么在此处使用外观模式?
定义 RequestFacade 类,分别实现 ServletRequest 和 HttpServletRequest,同时 定义私有成员变量 Request,并且方法的实现调用 Request 的实现。然后将 RequestFacade 上转为 ServletRequest 传给 servlet 的 service 方法,这样即使在 servlet 中被下转为 RequestFacade,也不能访问私有成员变量对象中的方法。既用了 Request,又能防止其中方法被不合理的访问。
5.6 组合模式
5.6.1 概述
组合模式,又名部分整体模式,是用于把一组相似的对象当作一个单一的对象。组合模式依据树形结构来组合对象,用来表示部分以及整体层次。这种类型的设计模式属于结构型模式,它创建了对象组的树形结构。
5.6.2 结构
组合模式主要包含三种角色:
- 抽象根节点(Component): 定义系统各层次对象的共有方法和属性,可以预先定义一些默认行为和属性。
- 树枝节点(Composite): 定义树枝节点的行为,存储子节点,组合树枝节点和叶子节点形成一个树形结构。
- 叶子节点(Leaf): 叶子节点对象,其下再无分支,是系统层次遍历的最小单位。
5.6.3 案例实现
实例:软甲菜单
5.6.4 组合模式的分类和优点
在使用组合模式时,根据抽象构建类的定义形式,我们可将组合模式分为透明组合模式和安全组合模式两种形式。
1, 透明组合模式: 透明组合模式中,抽象根节点角色中声明了所有用于管理成员对象的方法,比如在示例中 MenuComponent 声明了 add、remove、getChild 方法,这样做的好处是确保所有的构件类都有相同的接口。透明组合模式也是组合模式的标准形式。
透明组合模式的缺点是不够安全,因为叶子对象和容器对象在本质上是有区别的,叶子对象是不可能有下一个层次的对象,既不可能包含成员对象,因此为其提供 add()、remove() 等方法是没有意义的,这在编译阶段不会出错,但在运行阶段调用这些方法可能会出错(如果没有提供相应的错误处理代码)。
2, 安全组合模式: 在安全组合模式中,在抽象构件角色中没有声明任何用于管理成员对象的方法,而是在树枝节点 Menu 类中声明并实现这些方法。安全组合模式的缺点是不够透明,因为叶子构件和容器构件具有不同的方法,且容器构件中那些用于管理成员对象的方法没有在抽象构件类中定义,因此客户端不能完全针对抽象编程,必须有区别地对待叶子构件和容器构件。
5.6.5 优点
- 组合模式可以清楚地定义分层次的复杂对象,表示对象的全部或部分层次,它让客户端忽略了层次的差异,方便对整个层次结构进行控制。
- 客户端可以一致地使用一个组合结构或其中单个对象,不必关心处理的是单个对象还是整个组合结构,简化了客户端代码。
- 在组合模式中增加新的树枝节点和叶子节点都很方便,无须对现有类库进行任何修改,符合 “开闭原则”。
- 组合模式为树形结构的面向对象实现提供了一种灵活的解决方案,通过叶子节点和树枝节点的递归组合,可以形成复杂的树形结构,但对树形结构的控制却非常简单。
5.6.6 使用场景
组合模式正是应树形结构而生,所以组合模式的使用场景就是出现树形结构的地方。比如文件目录的显示,多级目录的呈现等树形结构数据的操作。
5.7 享元模式
5.7.1 概述
享元模式,运用共享技术来有效地支持大量细粒度对象的复用。它通过共享已经存在的对象来大幅度减少需要创建对象的数量、避免大量相似对象的开销,从而提高系统资源的利用率。
5.7.2 结构
享元(Flyweight)模式中存在以下两种状态:
- 内部状态: 即不会随着环境的改变而改变的可共享部分。
- 外部状态: 指随环境改变而改变的不可以共享的部分。享元模式的实现要领就是区分应用中这两种状态,并将外部状态外部化。
享元模式的主要有以下角色:
- 抽象享元角色 (Flyweight): 通常是一个接口或抽象类,在抽象享元类中声明了具体享元类公共的方法,这些方法可以向外界提供享元对象的内部数据(内部状态),同时也可以通过这些方法来设置外部数据(外部状态)。
- 具体享元(Concrete Flyweight)角色: 它实现了抽象享元类,称为享元对象,在具体享元类中为内部状态提供了存储空间。通常我们可以结合单例模式来设计具体享元类,为每一个具体享元类提供唯一的享元对象。
- 非享元(Unsharable Flyweight)角色: 并不是所有的抽象享元类的子类都需要被共享,不能被共享的子类可设计为非共享具体享元类,当需要一个非共享具体享元类时可以直接通过实例化创建。
- 享元工厂(Flyweight Factory)角色: 复杂创建和管理享元角色。当客户对象请求一个享元对象时,享元工厂检查系统中是否存在符合要求的享元对象,如果存在则提供给客户,如果不存在的话,则创建一个新的享元对象。
5.7.3 案例实现
示例:俄罗斯方块
5.7.4 优缺点和使用场景
优点:
- 极大减少内存中相似或相同对象数量,节约系统资源,提供系统性能。
- 享元模式中的外部状态相对独立,且不影响内部状态。
缺点: 为了使对象可以共享,需要将享元对象的部分状态外部化,分离内部状态和外部状态,使程序逻辑复杂。
使用场景:
- 一个系统有大量相同或相似的对象,造成大量的内存耗费。
- 对象的大部分状态都可以外部化,可以将这些外部状态传入对象中。
- 在使用享元模式时需要维护一个存储享元对象的享元池,而这需要耗费一定的系统资源,因此,应当在需要多次使用享元对象时才值得使用享元模式。
5.7.5 JDK 源码解析
Integer 类使用了享元模式。
Integer 默认先创建并缓存 -128~127 之间的 Integer 对象,当调用 valueOf 时如果参数在 -128~127 之间则计算下标并从缓存中返回,否则创建一个新的 Integer 对象。
四. 行为型模式(11种)
行为型模式用于描述程序在运行时复杂的流程控制,即描述多个类或对象之间怎样相互协作共同完成单个对象都无法单独完成的任务,它涉及算法与对象间职责的分配。
行为型模式分为类行为模式和对象行为模式,前者采用继承机制来在类间分配行为,后者采用组合或聚合在对象间分配行为。由于组合关系或聚合关系比继承关系耦合度低,满足"合成复用原则",所以对象行为模式比类行为模式具有更大的灵活性。
行为型模式分为:
- 模板方法模式
- 策略模式
- 命令模式
- 职责链模式
- 状态模式
- 观察者模式
- 中介者模式
- 迭代器模式
- 访问者模式
- 备忘录模式
- 解释器模式
6.1 模板方法模式
6.1.1 概述
模板方法模式:定义一个操作中的算法骨架,而将算法的一些步骤延迟到子类中,使得子类可以不改变该算法结构的情况下重定义该算法的某些特定步骤。
6.1.2 结构
模板方法(Template Method)模式包含以下主要角色:
- 抽象类(Abstract Class): 负责给出一个算法的轮廓和骨架。它由一个模板方法和若干个基本方法构成。
- 模板方法: 定义了算法的骨架,按某种顺序调用其包含的基本方法。
- 基本方法: 是实现算法各个步骤的方法,是模板方法的组成部分。基本方法又可以分为三种:
- 抽象方法(Abstract Method): 一个抽象方法由抽象类声明、由其具体子类声明。
- 具体方法(Concrete Method): 一个具体方法由一个抽象类或具体类声明并实现,其子类可以进行覆盖也可以直接继承。
- 钩子方法(Hook Method): 在抽象类中已经实现,包括用于判断的逻辑方法和需要子类重写的空方法两种。
- 具体子类(Concrete Class): 实现抽象类中所定义的抽象方法和钩子方法,它们是一个顶级逻辑的组成步骤。
一般钩子方法是用于判断的逻辑方法,这类方法名一般为 isXxx, 返回值类型为 Boolean 类型。
6.1.3 案例实现
示例:炒菜
6.1.4 优缺点
优点:
- 提高代码的复用性: 将相同部分的代码放在抽象的父类中,而将不同的代码放入不同的子类中。
- 实现了反向控制: 通过一个父类调用其子类的操作,通过对子类的具体实现扩展不同的行为,实现了反向控制,并符合"开闭原则"。
缺点:
- 对每个不同的实现都需要定义一个子类,这会导致类的个数增加,系统更加庞大,涉及也更加抽象。
- 父类中的抽象方法由子类实现,子类执行的结果会影响父类的结果,这导致了一种反向的控制结构,它提高了代码阅读的难度。
6.1.5 适用场景
- 算法的整体步骤很固定,但其中个别部分易变时,这时候可以使用模板方法模式,将容易变的部分抽象出来,供子类实现。
- 需要通过子类来决定父类算法中某个步骤是否执行,实现子类对父类的反向控制。
6.1.6 JDK 源码解析
InputStream 类使用了模板方法模式。在 InputStream 类中定义了多个 read() 方法。
6.2 策略模式
6.2.1 概述
策略模式,该模式定义了一系列的算法,并将每个算法封装起来,使它们可以相互替换,且算法的变化不会影响使用算法的客户。
策略模式属于对象行为模式,它通过对算法进行封装,把使用算法的责任和算法的实现分割开来,并委派给不同的对象对这些算法进行管理。
6.2.2 结构
策略模式的主要角色如下:
- 抽象策略类(Strategy): 这是一个抽象角色,通常由一个抽象类或接口实现。此角色给出所有的具体策略类所需的接口。
- 具体策略类(Concrete Strategy): 实现了抽象策略定义的接口,提供具体的算法实现或行为。
- 环境类(Context): 持有一个策略类的引用,最终给客户端调用。
6.2.3 案例实现
示例:促销活动
6.2.4 优缺点
优点:
- 策略类之间可以自由切换: 由于策略类都实现同一个接口,所以使它们之间可以自由切换。
- 易于扩展: 增加一个新的策略只需要添加一个具体的策略类即可,基本不需要改变原有的代码,符合"开闭原则"。
- 避免使用多重条件选择语句(if else),充分体现面向对象设计的思想。
缺点:
- 客户端必须知道所有的策略类,并自行决定使用哪个策略类。
- 策略模式将造成产生很多策略类,可以通过享元模式在一定程度上减少对象的数量。
6.2.5 适用场景
- 一个系统需要动态地在几种算法中选择一种时,可以将每个算法封装到策略类中。
- 一个类定义了多种行为,并且这些行为在这个类的操作中以多个条件语句的形式出现,可将每个条件分支移入它们各自的策略类中以代替这些条件语句。
- 系统中各算法彼此完全独立,且要求对客户隐藏具体算法的实现细节时。
- 系统要求使用算法的客户不应该知道其操作的数据时,可使用策略模式来隐藏与算法相关的数据结构。
- 多个类只区别在表现行为不同,可以使用策略模式,在运行时,动态选择具体要执行的行为。
6.2.6 JDK 源码解析
Comparator 中的策略模式。在 Arrays 类中有一个 sort() 方法。
Arrays 就是一个环境角色类,sort方法可以传一个新策略来排序。
6.3 命令模式
6.3.1 概述
命令模式,将一个请求封装为一个对象,使发出请求的责任和执行请求的责任分隔开。这样两者之间通过命令对象沟通,这样方便将命令对象进行存储、传递、调用、增加与管理。
6.3.2 结构
命令模式主要包含以下主要角色:
- 抽象命令类角色(Command): 定义命令的接口,声明执行的方法。
- 具体命令类角色(Concrete Command): 具体的命令,实现命令接口;通常会持有接收者,并调用接收者的功能来完成命令要执行的操作。
- 实现者/接收者角色(Receiver): 接收者,真正执行命令的对象。任何类都可能成为一个接收者,只要它能够实现命令要求实现的相应功能。
- 调用者/请求者角色(Invoker): 要求命令对象执行请求,通常会持有命令对象,可以持有很多的命令对象。这个是客户端真正触发命令并要求命令执行相应相应操作的地方,也就是相当于使用命令对象的入口。
6.3.3 案例实现
示例:点餐
6.3.4 优缺点
优点:
- 降低系统耦合度。命令模式能将调用操作的对象与实现该操作的对象解耦。
- 增加或删除命令非常方便。采用命令模式增加与删除命令不会影响其他类,它满足 “开闭原则”,对扩展比较灵活。
- 可以实现宏命令。命令模式可以与组合模式结合,将多个命令组合成一个命令,即宏命令。
- 方便实现 undo 和 redo 操作。命令模式可以与后面介绍的备忘录模式结合,实现命令的撤销和恢复。
缺点:
- 使用命令模式可能会导致某些系统有过多的具体命令类。
- 系统结构更加复杂。
6.3.5 适用场景
- 系统需要将请求调用者和请求接收者解耦,使得调用者和接收者不直接交互。
- 系统需要在不同的时间指定请求、将请求排队和执行请求。
- 系统需要支持命令的撤销(Undo)操作和恢复(Redo)操作。
6.3.6 JDK 源码解析
Runable 是一个典型的命令模式,Runable 担任命令的角色,Thread 充当的是调用者, Start 方法就是其执行方法。
6.4 责任链模式
6.4.1 概述
责任链模式,又名职责链模式,为了避免请求发送者与多个请求处理者耦合在一起,将所有请求的处理者通过前一对象记住下一个对象的引用而连成一条链;当有请求发生时,可将请求沿着这条链传递,直到有对象处理它为止。
6.4.2 结构
责任链主要包含以下角色:
- 抽象处理者(Handler)角色: 定义一个处理请求的接口,包含抽象处理方法和一个后继连接。
- 具体处理者(Concrete Handler)角色: 实现抽象处理者的处理方法,判断能否处理本次请求,如果可以处理请求则处理,否则将该请求转给它的后继者。
- 客户类(Client)角色: 创建处理链,并向链头的具体处理者对象提交请求,它不关心处理细节和请求的传递过程。
6.4.3 案例实现
示例:请假流程控制系统
6.4.4 优缺点
优点:
- 降低了对象之间的耦合度,该模式降低了请求发送者和接收者的耦合度。
- 增强了系统的可扩展性,可以根据需要增加新的请求处理类,满足开闭原则。
- 增强了给对象指派职责的灵活性,当工作流程发生变化,可以动态地改变链内的成员或者修改它们的次序,也可动态地新增或者删除责任。
- 责任链简化了对象之间的连接,一个对象只需保持一个指向其后继者的引用,不需保持其他所有处理者的引用,这避免了使用众多的 if 或者 if … else 语句。
- 责任分担,每个类只需要处理自己该处理的工作,不能处理的传递给下一个对象完成,明确各类的责任范围,符合类的单一职责原则。
缺点:
- 不能保证每个请求被处理。由于一个请求没有明确的接收者,所以不能保证它一定会被处理,该请求可能一直传到链的末端都得不到处理。
- 对比较长的职责链,请求的处理可能涉及多个处理对象,系统性能将受到一定影响。
- 职责链建立的合理性要靠客户端来保证,增加了客户端的复杂性,可能会由于职责链的错误设置而导致系统出错,如 可能会造成循环调用。
6.4.5 JDK 源码解析
在 JavaWeb 应用开发中,FilterChain 是职责链(过滤器)模式的典型应用,
6.5 状态模式
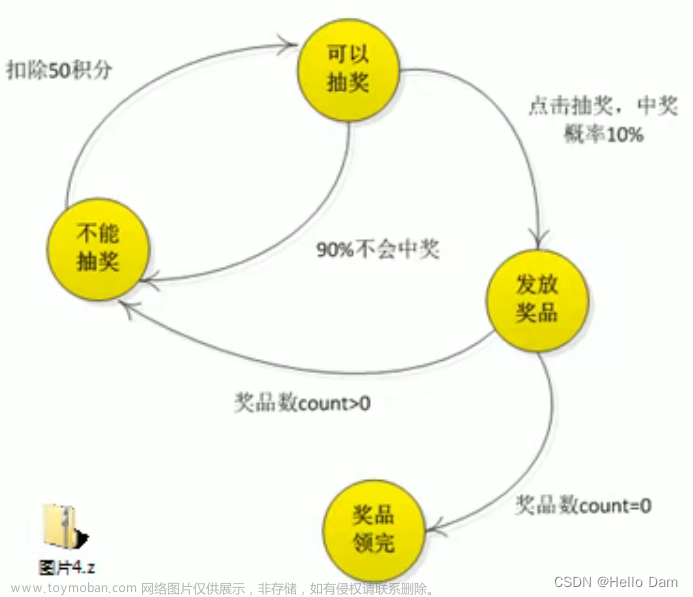
6.5.1 概述
示例:通过按钮控制电梯状态
问题分析:
- 使用了大量的 switch case 这样的判断 (if else 也是一样),使程序的可阅读性变差。
- 扩展性很差。如果新加了断电状态,需要修改上面状态判断。
状态模式,对有状态的对象,把复杂的"判断逻辑"提取到不同的状态对象中,允许状态对象在其内部状态发生改变时改变其行为。
6.5.2 结构
状态模式包含以下主要角色:
- 环境(Context)角色: 也称为上下文,它定义了客户程序需要的接口,维护一个当前状态,并将与状态相关的操作委托给当前状态对象来处理。
- 抽象状态(State)角色: 定义一个接口,用以封装环境对象中的特定状态所对应的行为。
- 具体状态(Concrete State)角色: 实现抽象状态所对应的行为。
6.5.3 案例实现
对上面示例进行改进,类图如下
6.5.4 优缺点
优点:
- 将所有与某个状态有关的行为放到一个类中,并且可以方便地增加新的状态,只需要改变对象状态即可改变对象的行为。
- 允许状态转换逻辑与状态对象合成一体,而不是某一个巨大的条件语句块。
缺点:
- 状态模式的使用必然会增加系统类和对象的个数。
- 状态模式的结构与实现都较为复杂,如果使用不当将导致程序结构和代码的混乱。
- 状态模式对“开闭原则”的支持并不太好。
6.5.5 适用场景
- 当一个对象的行为取决于它的状态,并且它必须在运行时根据状态改变它的行为时,就可以考虑使用状态模式。
- 一个操作中含有庞大的分支结构,并且这些分支决定于对象的状态时。
6.5.6 JDK 源码解析
6.6 观察者模式
6.6.1 概述
观察者模式,又被称为发布-订阅(Publish/Subscribe)模式,它定义了一种一对多的依赖关系,让多个观察者对象同时监听某一个主题对象。这个主题对象在状态变化时,会通知所有的观察者对象,使他们能够自动更新自己。
6.6.2 结构
在观察者模式中有如下角色:
- Subject: 抽象主题(抽象被观察者),抽象主题角色把所有观察者对象保存在一个集合里,每个主题都可以有任意数量的观察者,抽象主题提供一个接口,可以增加和删除观察者对象。
- ConcreteSubject: 具体主题(具体被观察者),该角色将有关状态存入具体观察者对象,在具体主题的内部状态发生改变时,给所有注册过的观察者发送通知。
- Observer: 抽象观察者,是观察者的抽象类,它定义了一个更新接口,使得在得到主题更改时更新自己。
- ConcreteObserver: 具体观察者,实现抽象观察者定义的更新接口,以便在得到主题更改通知时更新自身的状态。
6.6.3 案例实现
示例:微信公众号
6.6.4 优缺点
优点:
- 降低了目标与观察者之间的耦合关系,两者之间是抽象耦合关系。
- 被观察者发送通知,所有注册的观察者都会收到信息(可以实现广播机制)
缺点:
- 如果观察者非常多的话,那么所有的观察者收到被观察者发送的通知会耗时。
- 如果被观察者有循环依赖的话,那么被观察者发生通知会使观察者循环调用,会导致系统崩溃。
6.6.5 适用场景
- 对象间存在一对多关系,一个对象的状态发生改变会影响其他对象。
- 当一个抽象模型有两个方面,其中一个方面依赖于另一个方面时。
6.6.6 JDK 源码解析
在java中,通过 java.util.Observable 类和 java.util.Observer 接口定义了观察者模式,只要实现它们的子类就可以编写观察者模式实例。
6.7 中介者模式
6.7.1 概述
中介者模式,又叫调停模式,定义一个中介角色来封装一系列对象之间的交互,使得原有对象之间耦合松散,且可以独立地改变它们之间的交互。
6.7.2 结构
中介者模式包含以下主要角色:
- 抽象中介者(Mediator)角色: 它是中介者的接口,提供了同事对象注册与转发同事对象信息的抽象方法。
- 具体中介者(Concrete Mediator)角色: 实现中介者接口,定义一个 List 来管理同事对象,协调各个同事角色之间的交互关系,因此它依赖于同事角色。
- 抽象同事类(Colleague)角色: 定义同事类的接口,保存中介者对象,提供同事对象交互的抽象方法,实现所有相互影响的同事类的公共功能。
- 具体同事类(Concrete Colleague)角色: 是抽象同事类的实现者,当需要与其他同事对象交互时,由中介者对象负责后续的交互。
6.7.3 案例实现
示例:租房
6.7.4 优缺点
优点:
- 松散耦合: 中介者模式通过把多个同事对象之间的交互封装到中介者对象里面,从而使得同事对象之间松散耦合,基本上可以做到互补依赖,这样一来,同事对象就可以独立地变化和复用,而不再像以前那样"牵一处而动全身"了。
- 集中控制交互: 多个同事对象的交互,被封装在中介者对象里面集中管理,使得这些交互行为发生变化的时候,只需要修改中介者对象就可以了,当然如果是已经做好的系统,那么就扩展中介者对象,而各个同事类不需要修改。
- 一对多关联转变为一对一关联: 没有使用中介者模式的时候,同事对象之间的关系通常是一对多的,引入中介者对象以后,中介者对象和同事对象的关系通常变成双向的一对一,这会让对象的关系更容易理解。
缺点: 当同事类太多时,中介者的职责将很大,它会变得复杂而庞大,以至于系统难以维护。
6.7.5 适用场景
- 系统中对象之间存在复杂的引用关系,系统结构混乱且难以理解。
- 当想创建一个运行于多个类之间的对象,而又不想生成新的子类时。
6.8 迭代器模式
6.8.1 概述
迭代器模式,提供一个对象来顺序访问聚合对象中的一系列数据,而不是暴露聚合对象的内部表示。
6.8.2 结构
迭代器模式主要包含以下角色:
- 抽象聚合(Aggregate)角色: 定义存储、添加、删除聚合元素以及创建迭代器对象的接口。
- 具体聚合(Concrete Aggregate)角色: 实现抽象聚合类,返回一个具体迭代器的实例。
- 抽象迭代器(Iterator)角色: 定义访问和遍历聚合元素的接口,通常包含 hasNext()、next() 等方法。
- 具体迭代器(Concrete Iterator)角色: 实现抽象迭代器接口中所定义的方法,完成对聚合对象的遍历,记录遍历的当前位置。
6.8.3 案例实现
示例: 定义一个容器对象。使用迭代器来遍历。
6.8.4 优缺点
优点:
- 它支持以不同的方式遍历一个聚合对象,在同一个聚合对象上可以定义多种遍历方式。在迭代器模式中只需要用一个不同的迭代器来替换原有迭代器即可改变遍历算法,我们也可以自己定义迭代器的子类以支持新的遍历方式。
- 迭代器简化了聚合类。由于引入了迭代器,在原有的聚合对象中不需要再自行提供数据遍历等方法,这样可以简化聚合类的设计。
- 在迭代器模式中,由于引入了抽象层,增加新的聚合类和迭代器类都很方便,无须修改原有代码,满足"开闭原则"的要求。
缺点: 增加了类的个数,这在一定程度上增加了系统的复杂性。
6.8.5 适用场景
- 当需要为聚合对像提供多种遍历方式时。
- 当需要为遍历不同的聚合结构提供一个统一的接口时。
- 当访问一个聚合对象的内容而无需暴露其内部细节的表示时。
6.8.6 JDK 源码解析
迭代器在 Java 的很多集合类中被广泛应用。
注意:当我们在使用 Java 开发的时候,想使用迭代器模式的话,只要让我们自己定义的容器类实现 java.util.Iterable 并实现其中的 iterator() 方法使其返回一个 java.util.Iterator 的实现类就可以了。
6.9 访问者模式
6.9.1 概述
访问者模式,封装了一些作用于某种数据结构中的各元素的操作,它可以在不改变这个数据结构的前提下定义作用于这些元素的新的操作。
6.9.2 结构
访问者模式包含以下主要角色:
- 抽象访问者(Visitor)角色: 定义了对每一个元素(Element)访问的行为,它的参数就是可以访问的元素,它的方法个数理论上来讲与元素类个数(Element的实现类个数)是一样的,从这点不难看出,访问者模式要求元素类的个数不能改变。
- 具体访问者(Concrete Visitor)角色: 给出对每一个元素类访问时所产生的具体行为。
- 抽象元素(Element)角色: 定义了一个接受访问者的方法(accept),其意义是指,每一个元素都要可以被访问者访问。
- 具体元素(Concrete Element)角色: 提供接受访问方法的具体实现,而这个具体实现,通常情况下是使用访问者提供的访问改元素类的方法。
- 对象结构(Object Structure)角色: 定义当中所提到的对象结构,对象结构是一个抽象表述,具体点可以理解为一个具有容器性质或者复合对象特性的类,它会含有一组元素(Element),并且可以迭代这些元素,供访问者访问。
6.9.3 案例实现
示例:给宠物喂食
6.9.4 优缺点
优点:
- 扩展性好: 在不修改对象结构中的元素的情况下,为对象结构中的元素添加新的功能。
- 复用性好: 通过访问者来定义整个对象结构通用的功能,从而提高复用程度。
- 分离无关行为: 通过访问者来分离无关的行为,把相关的行为封装在一起,构成一个访问者,这样每一个访问者的功能都比较单一。
缺点:
- 对象结构变化很困难: 在访问者模式中,每增加一个新的元素类,都要在每一个具体访问者类中增加相应的具体操作,这违背了"开闭原则"。
- 违反了依赖倒置原则: 访问者模式依赖了具体类,而没有依赖抽象类。
6.9.5 适用场景
- 对象结构相对稳定,但其操作算法经常变化的程序。
- 对象结构中的对象需要提供多种不同且不相关的操作,而且要避免让这些操作的变化影响对象的结构。
6.9.6 扩展
访问者模式用到了一种双分派的技术。
分派: 变量被声明时的类型叫做变量的静态类型,有些人又把静态类型叫做明显类型;而变量所引用的对象的真实类型又叫做变量的实际类型。比如 Map map = new HashMap(), map 变量的静态类型是 Map ,实际类型是 HashMap。根据对象的类型而对方法进行的选择,就是分派(Dispatch), 分派(Dispatch)又分为两种,即静态分派和动态分派。
静态分派(Static Dispatch): 发生在编译时期,分派根据静态类型信息发生。静态分派对于我们来说并不陌生,方法重载就是静态分派。
动态分派(Dynamic Dispatch): 发生在运行时期,动态分派动态地置换掉某个方法。Java 通过方法的重写支持动态分派。
Java 编译器在编译时期并不总是知道哪些代码会被执行,因为编译器仅仅知道对象的静态类型,而不知道对象的真实类型,而方法的调用则是根据对象的真实类型,而不是静态类型。
重载方法的分派是根据静态类型进行的,这个分派过程在编译时期就完成了。
双分派: 所谓双分派技术就是在选择一个方法的时候,不仅仅要根据消息接收者(receiver)的运行时区别,还要根据参数的运行时区别。
双分派,实现动态绑定的本质,就是在重载方法委派的前面加上了继承体系中覆盖的环节,由于覆盖是动态的,所以重载就是动态的了。
6.10 备忘录模式
6.10.1 概述
备忘录模式,又叫快照模式,在不破坏封装性的前提下,捕获一个对象的内部状态,并在该对象之外保存这个状态,以便以后当需要时能将该对象恢复到原先保存的状态。
6.10.2 结构
备忘录模式的主要角色如下:
- 发起人(Originator)角色: 记录当前时刻的内部状态信息,提供创建备忘录和恢复备忘录数据的功能,实现其他业务功能,它可以访问备忘录里的所有信息。
- 备忘录(Memento)角色: 负责存储发起人的内部状态,在需要的时候提供这些内部状态给发起人。
- 管理者(Caretaker)角色: 对备忘录进行管理,提供保存和获取备忘录的功能,但其不能对备忘录的内容进行访问和修改。
备忘录有两个等效的接口:
- 窄接口: 管理者(Caretaker)对象(和其他发起人对象之外的任何对象)看到的是备忘录的窄接口(narror Interface), 这个窄接口只允许它把备忘录对象传给其他对象。
- 宽接口: 与管理者看到的窄接口相反,发起人对象可以看到一个宽接口(wide Interface),这个宽接口允许它读取所有的数据,以便根据这些数据恢复这个发起人对象的内部状态。
6.10.3 案例实现
示例: 游戏挑战 BOSS
游戏中的某个场景,一游戏角色有生命力、攻击力、防御力等数据,在打 BOSS 前和后一定会不一样的,我们允许玩家如果感觉与 Boss 决斗的效果不理想可以让游戏恢复到决斗之前的状态。
要实现上述示例,有两种方式:
- “白箱” 备忘录模式
- “黑箱” 备忘录模式
6.10.3.1 “白箱” 备忘录模式
备忘录角色对任何对象都提供一个接口,即宽接口,备忘录角色的内部所存储的状态就对所有对象公开。
6.10.3.2 “黑箱” 备忘录模式
备忘录角色对发起人对象提供一个宽接口,而为其他对象提供一个窄接口。在 Java 语言中,实现双重接口的办法就是将备忘录类设计成发起人的内部成员类。
6.10.4 优缺点
优点:
- 提供了一种可以恢复状态的机制。当用户需要时能够比较方便地将数据恢复到某个历史的状态。
- 实现了内部状态的封装。除了创建它的发起人之外,其他对象都不能够访问这些状态信息。
- 简化了发起人类。发起人不需要管理和保存其内部状态的各个备份,所有信息都保存在备忘录中,并由管理者进行管理,这符合单一职责原则。
缺点: 资源消耗大。如果要保存的内部状态信息过多或者特别频繁,将会占用比较大的内存资源。
6.10.5 适用场景
- 需要保存与恢复数据的场景,如玩游戏时的中间结果的存档功能。
- 需要提供一个可回滚的操作场景,如 word、记事本等软件在编辑时按 Ctrl + z 组合键,还有数据库中事务的操作。
6.11 解释器模式
6.11.1 概述
解释器模式,给定一个语言,定义它的文法表示,并定义一个解释器,这个解释器使用该标识来解释语言中的句子。
文法(语法)规则: 文法是用于描述的语法结构的形式规则。
抽象语法树: 在计算机科学中,抽象语法树(AbstractSyntaxTree, AST), 或简称语法树(Syntax tree),是源代码语法结构的一种抽象表示。它以树状的形式表现编程语言的语法结构,树上的每个节点都表示源代码中的一种结构。
6.11.2 结构
解释器模式包含以下主要角色:
- 抽象表达式(Abstract Expression)角色: 定义解释器的接口,约定解释器的解释操作,主要包含解释方法 interpret()。
- 终结符表达式(Terminal Expression)角色: 是抽象表达式的子类,用来实现文法中与终结符相关的操作,文法中的每一个终结符都有一个具体终结表达式与之相对应。
- 非终结符表达式(Nonterminal Expression)角色: 也是抽象表达式的子类,用来实现文法中与非终结符相关的操作,文法中的每条规则都对应于一个非终结符表达式。
- 环境(Context)角色: 通常包含各个解释器需要的数据或是公共的功能,一般用来传递被所有解释器共享的数据,后面的解释器可以从这里获取这些值。
- 客户端(Client): 主要任务是将需要分析的句子或表达式转换成使用解释器对象描述的抽象语法树,然后调用解释器的解释方法,当然也可以通过环境角色间接访问解释器的解释方法。
6.11.3 案例实现
示例:设计实现加减法的软件。
6.11.4 优缺点
优点:
- 易于改变和扩展文法。由于在解释器模式中使用类来表示语言的文法规则,因此可以通过继承等机制来改变或扩展文法。每一条文法规则都可以表示为一个类,因此可以方便地实现一个简单的语言。
- 实现文法较为容易。在抽象语法树中每一个表达式节点类的实现方式都是相似的,这些类的代码编写都不会特别复杂。
- 增加新的解释表达式较为方便。如果用户需要增加新的解释表达式只需要对应增加一个新的终结符表达式或非终结符表达式类,原有表达式类无需修改,符合"开闭原则"。
缺点:
- 对于复杂文法难以维护。在解释器模式中,每一条规则至少需要定义一个类,因此如果一个语言包含太多文法规则,类的个数将会急剧增加,导致系统难以管理和维护。
- 执行效率低。由于在解释器模式中使用了大量的循环和递归调用,因此在解释较为复杂的句子时其速度很慢,而且代码的调试过程也比较麻烦。
6.11.5 适用场景
- 当语言的文法较为简单,且执行效率不是关键问题时。
- 当问题重复出现,且可以用一种简单的语言来进行表达时。
- 当一个语言需要解释执行时,并且语言中的句子可以表示为一个抽象语法树的时候。
参考文献
黑马程序员文章来源地址https://www.toymoban.com/news/detail-806980.html
到了这里,关于设计模式的学习笔记的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!