Kafka在实际应用中,经常被用作高性能、可扩展的消息中间件。
Kafka自定义了一套网络协议,只要遵守这套协议的格式,就可以向Kafka发送消息,也可以从Kafka中拉取消息。
在实践生产过程中,一套API封装良好、灵活易用的客户端可以避免开发人员重复劳动,提高开发效率,也可以提高程序的健壮性和可靠性。
Kafka提供了Java版本的生产者的实现——KafkaProducer,使用KafkaProducer的API可以轻松实现同步/异步发送消息、批量发送、超时重发等复杂的功能,在业务模块向Kafka写入消息时,KafkaProducer就显得必不可少。
现在,Kafka的爱好者已经使用多种语言(诸如C++、Java、Python、Go等)实现了Kafka的客户端。
如果读者使用其他语言,可以到Kafka官方网站的wiki(https://cwiki.apache.org/confluence/display/KAFKA/Clients)查找相关资料。
在Kafka core模块的kafka.producer包中,新版本的生产者客户端实现KafkaProducer(Java实现)在Kafka clients模块的org.apache.kafka.clients.producer包中。
KafkaProducer分析
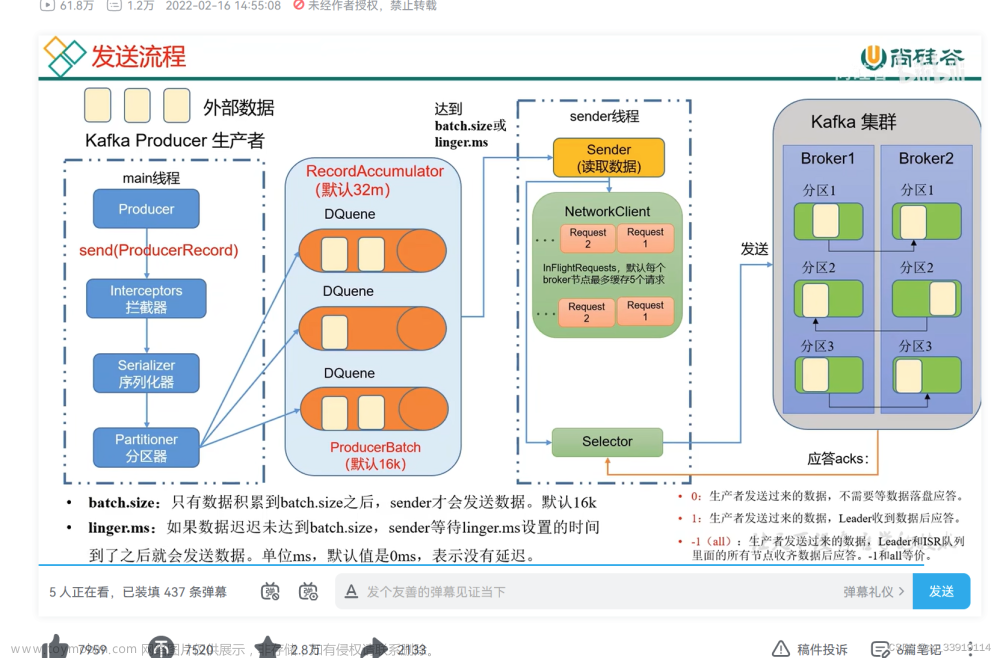
在图中简略描述了KafkaProducer发送消息的整个流程。

下面简述图中每个步骤的操作:
- Producerlnterceptors对消息进行拦截。
- Serializer对消息的key和value进行序列化。
- Partitioner为消息选择合适的Partition。
- RecordAccumulator收集消息,实现批量发送。
- Sender从RecordAccumulator获取消息。
- 构造ClientRequest。
- 将ClientRequest交给NetworkClient,准备发送。
- NetworkClient将请求放入KafkaChannel的缓存。
- 执行网络I/O,发送请求。
- 收到响应,调用ClientRequest的回调函数。
- 调用RecordBatch的回调函数,最终调用每个消息上注册的回调函数。
消息发送的过程中,涉及两个线程协同工作。主线程首先将业务数据封装成ProducerRecord对象,之后调用send方法将消息放入RecordAccumulator(消息收集器,也可以理解为主线程与Sender线程之间的缓冲区)中暂存。
Sender线程负责将消息信息构成请求,并最终执行网络IVO的线程,它从RecordAccumulator中取出消息并批量发送出去。
需要注意的是,KafkaProducer是线程安全的,多个线程间可以共享使用同一个KafkaProducer对象。
KafkaProducer实现了Producer接口,在Producer接口中定义KafkaProducer对外提供的API,分为四类方法。
- send方法:发送消息,实际是将消息放入RecordAccumulator暂存,等待发送。
- flush方法:刷新操作,等待RecordAccumulator中所有消息发送完成,在刷新完成之前会阻塞调用的线程。
- partitionsFor方法:在KafkaProducer中维护了一个Metadata对象用于存储Kafka集群的元数据,Metadata中的元数据会定期更新。partitionsFor方法负责从Metadata中获取指定Topic中的分区信息。
- close方法:关闭此Producer对象,主要操作是设置close标志,等待RecordAccumulator中的消息清空,关闭Sender线程。
还有一个metrics方法,用于记录统计信息,与消息发送的流程无关,我们不做详细分析。
了解了Producer接口的功能之后,我们下面就来分析KafkaProducer的具体实现。
首先,介绍KafkaProducer中比较重要的字段,在后面分析过程中,会逐个进行分析,如图所示。

- PRODUCER_CLIENT_ID_SEQUENCE:clientld的生成器,如果没有明确指定client的Id,则使用字段生成一个ID。
- clientld:此生产者的唯一标识。
- partitioner:分区选择器,根据一定的策略,将消息路由到合适的分区。
- maxRequestSize:消息的最大长度,这个长度包含了消息头、序列化后的key和序列化后的value的长度。
- totalMemorySize:发送单个消息的缓冲区大小。
- accumulator:RecordAccumulator,用于收集并缓存消息,等待Sender线程发送。
- sender:发送消息的Sender任务,实现了Runnable接口,在ioThread线程中执行。
- ioThread:执行Sender任务发送消息的线程,称为“Sender线程”。
- compressionType:压缩算法,可选项有none、gzip、snappy、lz4。这是针对RecordAccumulator中多条消息进行的压缩,所以消息越多,压缩效果越好。
- keySerializer:key的序列化器。
- valueSerializer:value的序列化器。
- Metadata metadata:整个Kafka集群的元数据。
- maxBlockTimeMs:等待更新Kafka集群元数据的最大时长。
- requestTimeoutMs:消息的超时时间,也就是从消息发送到收到ACK响应的最长时长。
- interceptors:Producerlnterceptor集合,Producerlnterceptor可以在消息发送之前对其进行拦截或修改;也可以先于用户的Callback,对ACK响应进行预处理。
- producerConfig:配置对象,使用反射初始化KafkaProducer配置的相对对象。
KafkaProducer构造完成之后,我们来关注KafkaProducer的send方法。图展示了整个send方法的调用流程。

Producerlnterceptors&Producerlnterceptor
Producerlnterceptors是一个Producerlnterceptor集合,其onSend方法、onAcknowledgement方法、onSendEror方法,实际上是循环调用其封装的Producerlnterceptor集合的对应方法。
Producerlnterceptor对象可以在消息发送之前对其进行拦截或修改,也可以先于用户的Callback,对ACK响应进行预处理。
如果熟悉Java Web开发,可以将其与Filter的功能做类比。
如果要使用自定义Producerlnterceptor类,只要实现Producerlnterceptor接口,创建其对象并添加到Producerlnterceptors中即可。
Producerlnterceptors与ProducerInterceptor之间的关系如图所示。

Kafka集群元数据
每个Topic中有多个分区,这些分区的Leader副本可以分配在集群中不同的Broker上。
我们站在生产者的角度来看,分区的数量以及Leader副本的分布是动态变化的。
通过简单的示例说明这种动态变化:在运行过程中,Leader副本随时都有可能出现故障进而导致Leader副本的重新选举,新的Leader副本会在其他Broker上继续对外提供服务。
当需要提高某Topic的并行处理消息的能力时,我们可以通过增加其分区的数量来实现。
当然,还有别的方式导致这种动态变化,例如,手动触发“优先副本”选举等。
我们创建的ProducerRecord中只指定了Topic的名称,并未明确指定分区编号。
KafkaProducer要将此消息追加到指定Topic的某个分区的Leader副本中,首先需要知道Topic的分区数量,经过路由后确定目标分区,之后KafkaProducer需要知道目标分区的Leader副本所在服务器的地址、端口等信息,才能建立连接,将消息发送到Kafka中。
因此,在KafkaProducer中维护了Kafka集群的元数据,这些元数据记录了:某个Topic中有哪几个分区,每个分区的Leader副本分配哪个节点上,Follower副本分配哪些节点上,哪些副本在ISR集合中以及这些节点的网络地址、端口。
在KafkaProducer中,使用Node、TopicPartition、PartitionInfo这三个类封装了Kafka集群的相关元数据,其主要字段如图所示。

- Node表示集群中的一个节点,Node记录这个节点的host、ip、port等信息。
- TopicPartition表示某Topic的一个分区,其中的topic字段是Topic的名称,partition字段则此分区在Topic中的分区编号(ID)。
- PartitionInfo表示一个分区的详细信息。其中topic字段和partition字段的含义与TopicPartition中的相同,除此之外,leader字段记录了Leader副本所在节点的id,replica字段记录了全部副本所在的节点信息,inSyncReplicas字段记录了ISR集合中所有副本所在的节点信息。
通过这三个类的组合,我们可以完整表示出KafkaProducer需要的集群元数据。
这些元数据保存在了Cluster这个类中,并按照不同的映射方式进行存放,方便查询。Cluster类的核心字段如图所示。

- nodes:Kafka集群中节点信息列表。
- nodesById:Brokerld与Node节点之间对应关系,方便按照Brokerld进行索引。
- partitionsBy TopicPartition:记录了TopicPartition与PartitionInfo的映射关系。
- partitionsByTopic:记录了Topic名称和Partitionlnfo的映射关系,可以按照Topic名称查询其中全部分区的详细信息。
- availablePartitionsByTopic:Topic与Partitionlnfo的映射关系,这里的List中存放的分区必须是有Leader副本的Partition,而partitionsByTopic中记录的分区则不一定有Leader副本,因为某些中间状态,例如Leader副本宕机而触发的选举过程中,分区不一定有Leader副本。
- partitionsByNode:记录了Node与PartitionInfo的映射关系,可以按照节点Id查询其上分布的全部分区的详细信息。
Metadata中封装了Cluster对象,并保存Cluster数据的最后更新时间、版本号(version)、是否需要更新等待信息,如图所示。

- topics:记录了当前已知的所有topic,在cluster字段中记录了Topic最新的元数据。
- version:表示Kafka集群元数据的版本号。Kafka集群元数据每更新成功一次,version字段的值增1。通过新旧版本号的比较,判断集群元数据是否更新完成。
- metadataExpireMs:每隔多久,更新一次。默认是300×1000,也就是5分种。
- refreshBackoffMs:两次发出更新Cluster保存的元数据信息的最小时间差,默认为100ms。这是为了防止更新操作过于频繁而造成网络阻塞和增加服务端压力。在Kafka中与重试操作有关的操作中,都有这种“退避(backoff)时间”设计的身影。
- lastRefreshMs:记录上一次更新元数据的时间戳(也包含更新失败的情况)。
- lastSuccessfulRefreshMs:上一次成功更新的时间戳。如果每次都成功,则lastSuccessfulRefreshMs、lastRefreshMs相等。 否则,lastRefreshMs>lastSuccessulRefreshMs。
- cluster:记录Kafka集群的元数据。
- needUpdate:标识是否强制更新Cluster,这是触发Sender线程更新集群元数据的条件之一。
- listeners:监听Metadata更新的监听器集合。自定义Metadata监听实现Metadata.Listener.onMetadataUpdate方法即可,在更新Metadata中的cluster字段之前,会通知listener集合中全部Listener对象。
- needMetadataForAllTopics:是否需要更新全部Topic的元数据,一般情况下,KafkaProducer只维护它用到的Topic的元数据,是集群中全部Topic的子集。
Metadata的方法比较简单,主要是操纵上面的几个字段,这里着重介绍主线程用到的requestUpdate方法和awaitUpdate方法。
requestUpdate()方法将needUpdate字段修改为true,这样当Sender线程运行时会更新Metadata记录的集群元数据,然后返回version字段的值。
awaitUpdate方法主要是通过version版本号来判断元数据是否更新完成,更新未完成则阻塞等待。

下面回到KafkaProducer.waitOnMetadata方法的分析,它负责触发Kafka集群元数据的更新,并阻塞主线程等待更新完毕。它的主要步骤是:
- 检测Metadata中是否包含指定Topic的元数据,若不包含,则将Topic添加到topics集合中,下次更新时会从服务端获取指定Topic的元数据。
- 尝试获取Topic中分区的详细信息,失败后会调用requestUpdate)方法设置Metadata.needUpdate字段,并得到当前元数据版本号。
- 唤醒Sender线程,由Sender线程更新Metadata中保存的Kafka集群元数据。
- 主线程调用awaitUpdate()方法,等待Sender线程完成更新。
- 从Metadata中获取指定Topic分区的详细信息(即PartitionInfo集合)。若失败,则回到步骤2继续尝试,若等待时间超时,则抛出异常。
waitOnMetadata()方法的具体实现如下:

Serializer&Deserializer
客户端发送的消息的key和value都是byte数组,Serializer和Deserializer接口提供了将Java对象序列化(反序列化)为byte数组的功能。在KafkaProducer中,根据配置文件,使用合适的Serializer。
图展示了Serializer和Deserializer接口以及它们的实现类。

Kafka已经为我们提供了Java基本类型的Serializer实现和Deserializer实现,我们也可以对Java复杂类型的自定义Serializer和Deserializer实现,只要实现Serializer或Deserializer接口即可。
下面简单介绍Serializer,Deserializer是其逆操作。
在Serializer接口中,configure()方法是在执行序列化操作之前的配置,例如,在StringSerializer.configure()方法中会选择合适的编码类型(encoding),默认是UTF-8;IntegerSerializer.configure()方法则是空实现。
serializer方法是真正进行序列化的地方,将传入的Java对象序列化为byte[]。
close方法是在其后的关闭方法,多为空实现。
Partitioner
KafkaProducer.send()方法的下一步操作是选择消息的分区。
在有的应用场景中,由业务逻辑控制每个消息追加到合适的分区中,而有时候业务逻辑并不关心分区的选择。
在KafkaProducer.partition方法中,优先根据ProducerRecord中partition字段指定的序号选择分区,如果ProducerRecord.partition字段没有明确指定分区编号,则通过Partitioner.partition()方法选择Partition。

Kafka提供了Partitioner接口的一个默认实现——DefaultPartitioner,继承结构如图(左)所示,可以看到上面介绍的ProducerInterceptor接口也继承了Configurable接口。
在创建KafkaProducer时传人的key/value配置项会保存到AbstractConfig的originals字段中,如图(右)所示。AbstractConfig的核心方法是getConfiguredInstance方法,其主要功能是通过反射机制实例化originals字段中指定的类。在前面分析KafkaProducer的构造函数时,也看到过此方法的调用。文章来源:https://www.toymoban.com/news/detail-807113.html
DefaultPartitioner.partition方法负责在ProduceRecord中没有明确指定分区编号的时候,为其选择合适的分区:如果消息没有key,会根据counter与Partition个数取模来确定分区编号,count不断递增,确保消息不会都发到同一个Partition里;如果消息有key的话,则对key进行hash(使用的是murmur2这种高效率低碰撞的Hash算法),然后与分区数量取模,来确定key所在的分区达到负载均衡。文章来源地址https://www.toymoban.com/news/detail-807113.html
到了这里,关于Kafka-生产者的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!