https://spark.apache.org/docs/2.4.0/sql-distributed-sql-engine.html#running-the-thrift-jdbcodbc-server
Spark SQL可以作为一个分布式查询引擎,通过其JDBC/ODBC或命令行接口进行操作。通过JDBC/ODBC接口,用户可以使用常见的数据库工具或BI工具来连接和查询Spark SQL,这使得Spark SQL可以与现有的数据分析工具和报表工具集成,为用户提供了更加灵活和便捷的数据分析和查询方式。
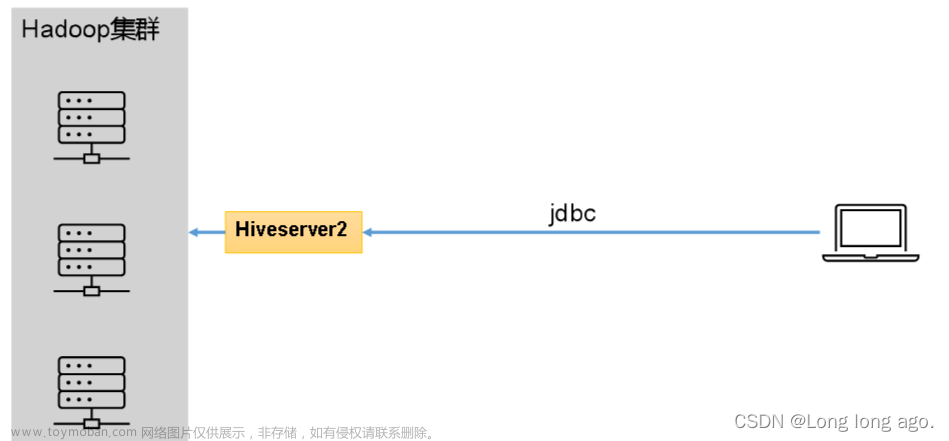
这里实现的Thrift JDBC/ODBC服务器对应于Hive 1.2.1中的HiveServer2。您可以使用Spark或Hive 1.2.1附带的beeline脚本测试JDBC服务器。
这个脚本接受所有bin/spark-submit命令行选项,还可以使用–hiveconf选项来指定Hive属性。您可以运行./sbin/start-thriftserver.sh --help来获取所有可用选项的完整列表。默认情况下,服务器监听localhost:10000。您可以通过环境变量来覆盖这种行为,例如:文章来源:https://www.toymoban.com/news/detail-807174.html
Thrift 接口的缺点
https://baijiahao.baidu.com/s?id=1695268888248206405&wfr=spider&for=pc文章来源地址https://www.toymoban.com/news/detail-807174.html
到了这里,关于spark的jdbc接口,类似于hiveserver2的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!


![【Hadoop】-Hive客户端:HiveServer2 & Beeline 与DataGrip & DBeaver[14]](https://imgs.yssmx.com/Uploads/2024/04/860527-1.png)



