在上一篇文章中,首次出现了学习率这个词,在这篇文章中我会详细介绍一下它是什么,到底对机器学习的训练有着怎样的影响。
一、学习率是什么?
先来复习一下梯度下降算法,在每次迭代过程中,算法计算目标函数关于当前参数值的梯度(即函数在该点的斜率或方向导数向量),然后沿着梯度的反方向移动一定的步长。更新规则可以表示为:
其中:
- θ 表示模型参数。
- η是学习率,决定了每一步沿梯度方向调整参数的幅度。
- ∇f(θ) 是目标函数 f 关于参数 θ 的梯度。
学习率就是这里所说的步长,它是一个超参数,用于控制我们在梯度下降过程中每步的跳跃大小。也就是在每次梯度下降更新参数(如线性回归的权重和偏置)的时候,学习率决定了我们沿着负梯度方向走的步长。直观理解,就像你在山上往下走,而你的目标是走到山谷(函数最小值),每一步你到底能走多远,就是由学习率决定的。

超参数是指区别于机器学习最终要学到的模型参数而言的另一种参数。学习率这样的种超参数是由人工来设定的,那么就存在到底要设置多少合适的问题。
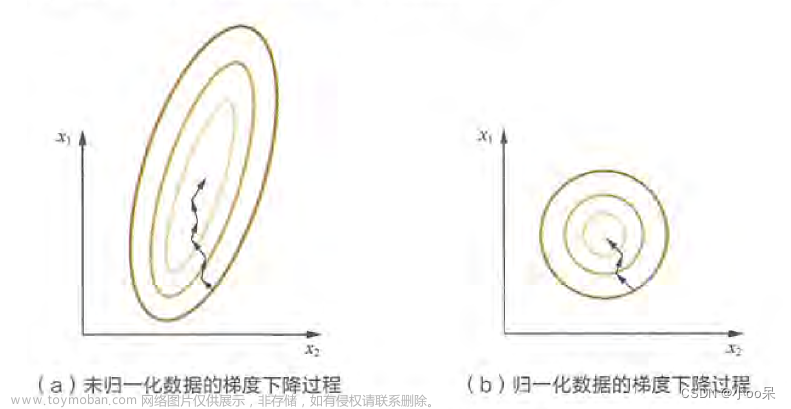
二、学习率设置过大或过小会对训练产生怎样的影响
(1)学习率设置过小
如果学习率太低,那么可能它需要非常多的迭代才能找到最低点。而且如果在遇到了下面这种情况,他还会陷入局部最小值而无法找到全局的最低点。


文章来源:https://www.toymoban.com/news/detail-807722.html
(2)学习率设置过大
如果学习率设置得过大,那么在更新权重和偏置时,每一步可能会“跳过”最优解,也就是说,每一步修改的幅度过大,可能会错过最小的损失值。在图像中,表现为来回震荡并且可能导致发散,模型无法收敛,即使能收敛也需要非常多的时间。文章来源地址https://www.toymoban.com/news/detail-807722.html

到了这里,关于【机器学习300问】10、学习率设置过大或过小对训练有何影响?的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!