一、大模型的发展
大模型与通用人工智能(AGI),大模型通常被视为发展通用人工智能的重要途径。AI研究从专用模型向通用模型转变,在过去的一二十年中,研究重点在于针对特定任务的专用模型。
专用模型的已经再多个领域取得显著成就,包裹大规模语音识别、图像识别、人脸识别、AIphago
下围棋、德扑游戏以及AIFold在蛋白质结构预测方面的应用。
尽管专用模型在特定任务表现出色,但应用范围有限,无法处理超过其训练范围的问题。因此随着深度学习理论的突破和技术进步,通用模型成为了AI研究的新焦点,目的就是为了创建能够解决多种问题的灵活、适应性强的模型

上海人工智能实验室专注于大型语言模型的研发,开发三款级别的大模型;且对社区和商业的贡献:B和20B模型目前已开源并可免费商用,为开发者社区和企业提供了高质量的模型资源。

中量性能大模型比较:

二、从模型到应用
模型选择:
- 从开源社区的众多模型中选择合适的模型
- 侧重评估模型在特定应用场景的相关能力
- 这一步的本质是模型测评的过程
评估业务场景复杂度:
- 对于简单业务场景,可以直接应用开源模型并通过prompt工程技术进行集成
- 对于复杂业务场景,通常需要对模型进行微调
模型微调:
- 需要考虑算力资源是否足够
- 足够算例时候可以进行全参数微调
- 算例有限是,可能只能进行部分参数的微调,例如使用 Lora算法
模型与环境的交互:
- 有些业务场景需要模型与外部API或数据库交互
- 这种情况,需要构建大模型的智能体以更好地适应业务场景
模型应用与测评:
- 无论是否需要构建智能体,模型都需要在业务场景中进行测试和评估
- 如果评测通过,模型可以考虑上线;如果通过,需要进一步迭代和微调。
模型部署:
- 面临如何以更少资源部署模型的问题
- 需要考虑如何提高应用吞吐量

三、开源开访体系
体系图解

数据部分
-
书生万卷(多模态语料库):
- 开源时间:首次开源于8月。
- 内容多样性:包含文本、图像文本、视频数据,总体积超过2TB。
- 领域涵盖:涉及科技、文学、媒体、教育、法律等多个领域。
- 对模型的贡献:这样的数据集对模型的知识、逻辑、推理能力有显著的提升效果。
- 数据处理:经过精细化处理,使用了书生葡语大模型研发过程中积累的数据预处理和数据清洗技术。
- 价值观对齐:在构建过程中,注重与中国主流价值观的对齐,以确保语料库的合法合规性和纯净度。
-
Open Data Lab(开放数据平台):
- 数据丰富性:提供超过5,400个数据集,涵盖30多种模态,总体积约80TB。
- 数据类型:包括图像、视频、文本语料、3D模型、音频等多种数据类型。
- 可用性:这些数据集在Open Data Lab平台上可供浏览和下载。
- 附加工具:提供智能标注等辅助工具。

预训练部分
-
高可扩展性:
- 支持从8卡到铅卡的训练。
- 铅卡的加速效率高达92%,这在性能上领先于其他一些社区开源框架。
-
极致的性能优化:
- 采用Hybrid Zero等独特技术,以及其他优化手段。
- 能够将整体模型训练的速度提高50%。
-
兼容主流技术生态:
- 兼容包括Hugging Face等主流技术生态。
- 支持各类轻量化技术,实现与in time train的无缝接入和兼容。
-
开箱即用:
- 支持多种规格的语言模型。
- 用户只需修改配置即可进行训练,使得工具使用方便且灵活。

微调
-
微调策略:
- 增量续训:用于让模型学习新的知识,如特定垂直领域的知识。使用的数据可能包括特定领域的文章、书籍或代码。
- 有监督微调:旨在让模型学会理解和遵循指令或注入少量领域知识。使用的数据主要是高质量的对话和问答数据。
-
微调方法:
- 全量参数微调:调整所有模型参数。
- 部分参数微调:例如使用Lora方法,仅调整模型的一小部分参数,以减少训练代价。
-
高效微调框架 X2:
- 兼容多种生态和微调算法,包括Hugging Face和Model Scope。
- 支持自动化优化加速,减少开发者在显存优化和计算加速等复杂问题上的负担。
- 适配多种硬件,覆盖Nvidia 20系列以上的所有显卡。
- 实现在8GB显存上微调7B模型的能力。
-
硬件适配:
- 支持不同类型的Nvidia显卡,包括消费级和数据中心级。
- 适应不同任务和数据格式,内置支持多种主流数据集。
- 兼容多种训练引擎和优化算法。



评测

模型架构

亮点以及合作机构

模型部署
-
大型语言模型的特点:
- 巨大的内存开销:由于庞大的参数量,大型语言模型需要很大的内存。
- 自回归生成方式:为加速推理,常常缓存键值对(KV),进一步增加内存开销。
- 动态Shape问题:请求和生成的token数不固定,增加了推理过程的复杂性。
- 相对简单的模型结构:大部分基于Transformer架构,结构比计算机视觉模型更简单。
-
部署中的技术挑战:
- 如何在低存储设备(如消费者显卡、移动端)上部署。
- 加速token生成速度。
- 解决动态Shape问题,实现无间断推理。
- 高效地管理和利用内存。
- 提升系统吞吐量,降低请求响应时间。
-
优化技术点:
- 模型变形。
- DBT量化。
- Attention优化。
- 计算和访存优化。
- 针对大型语言模型特有的策略,如continuous batching。
-
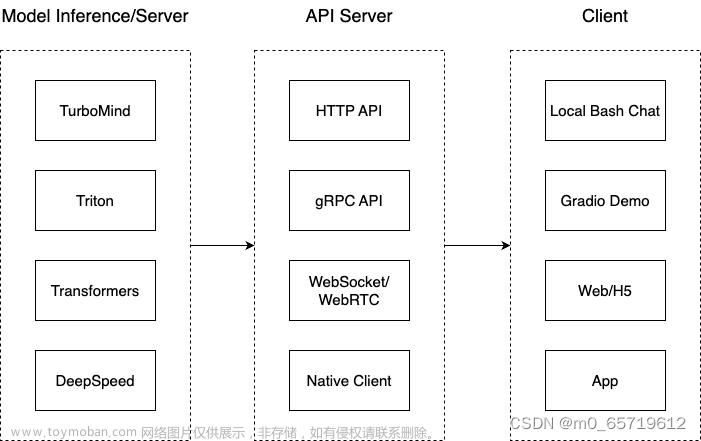
LMD Play:高效推理框架:
- 提供大模型部署的全流程解决方案。
- 包括模型轻量化和推理服务。
- 提供不同接口,如Python接口、IPC接口和RESTful接口。
- 核心功能模块包括模型轻量化(支持4比特权重量化、8比特KV量化等)。


智能体
-
大型语言模型的局限性:
- 新信息和知识获取:大型语言模型本身不具备获取最新信息和知识的能力。
- 回复可靠性问题:可能存在回答不准确或不可靠的情况。
- 数学计算能力:大型语言模型在处理数学计算方面的能力有限。
- 外部工具的使用和交互:需要与外部工具进行有效的交互。
-
智能体框架解决方案:
- 基于大型语言模型构建智能体,以解决上述局限性。
- 智能体框架通常包括不同的模块,以大型语言模型作为核心进行规划、推理和执行。
- 可以调用不同的动作,例如网络搜索、Python代码解释器等。
- 利用大型语言模型的推理能力进行规划和调用链设计。
-
智能体策略和流程:
- 智能体可能采用不同的流程和策略,如“plan-act”迭代、反思(reflection)等。
- 智能体策略的设计可能根据不同的研究或应用需求而有所不同。
-
开源智能体框架Lagent:
- 支持不同类型的智能体能力。
- 轻量级,适用于各种应用场景。

-
智能体执行流程:
- 核心流程包括根据输入选择和执行工具,判断技术条件,以及在需要时继续调用工具。
- 包含特定流程如react、rewoo和 autoGPT等,每个流程都有不同的智能体调用逻辑。
-
Lagent框架的实现与灵活性:
- Lagent已实现了这些智能体流程。
- 开发者可以轻松地开发,增加定制化功能。
- 支持不同的大型语言模型,如ChatGPT、InternLM、LLAMA等。
- 与Hugging Face Transformers兼容,易于接入Transformer中的大型语言模型。
-
模型接入的便捷性:
- Legend框架支持快速集成现有的大型语言模型。
- 提供灵活的框架以适应不同的需求和场景。

工具箱集合
-
Agent Lego与Lagent的区别:
- Lagent:用于构建智能体的整体框架。
- Agent Lego:重点在于提供大型模型可调用的工具集合。
-
Agent Lego的特点:
- 基于Open Lab的积累,提供了丰富的工具,包括视觉工具等。
- 支持包括Stable Diffusion和Hugging Face中的经典模型。
- 兼容多个主流智能检测系统,如Lang Chain和Transformer Agents。
- 提供灵活的多模态工具调用接口,支持各种输入输出格式的工具函数。
- 简化接口设计,便于开发新工具。
- 支持一键式远程工具部署,方便使用和调试大型模型智能体。
-
Agent Lego的应用效果:文章来源:https://www.toymoban.com/news/detail-807916.html
- 结合Lagent和Agent Lego,可以轻松将大型语言模型与环境连接,调用更多工具完成任务。
 文章来源地址https://www.toymoban.com/news/detail-807916.html
文章来源地址https://www.toymoban.com/news/detail-807916.html
到了这里,关于书生浦语大模型--开源体系的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!