elasticsearch[七]:ES评分规则详解
一、需求
因为需要对搜索结果进行一个统一化的评分,因此需要仔细研究 ES 本身的评分规则从而想办法把评分统一。
省流:无法确切统一化
二、ES 查询评分规则
之前有说过 ES 的查询评分原理,那么仔细思考之后就会发现,长文本搜索对应的 score 会比短文本搜索的 score 高很多:score = 单个分词评分之和,长文本对应的词更多那么 score 就会更多。
通过在查询中设置参数”explain”:true 来查看具体的分数来源 (explain的输出代价较大。它只是一个调试工具。不要让在生产中使用):
2.1. 查询分数基本结构
request:
post http://localhost:9200/policy_index/_search
{
"size": 20,
"query": {
"match": {
"policyTitle": {
"query": "青年大学习"
}
}
},
"explain": true
}
response:
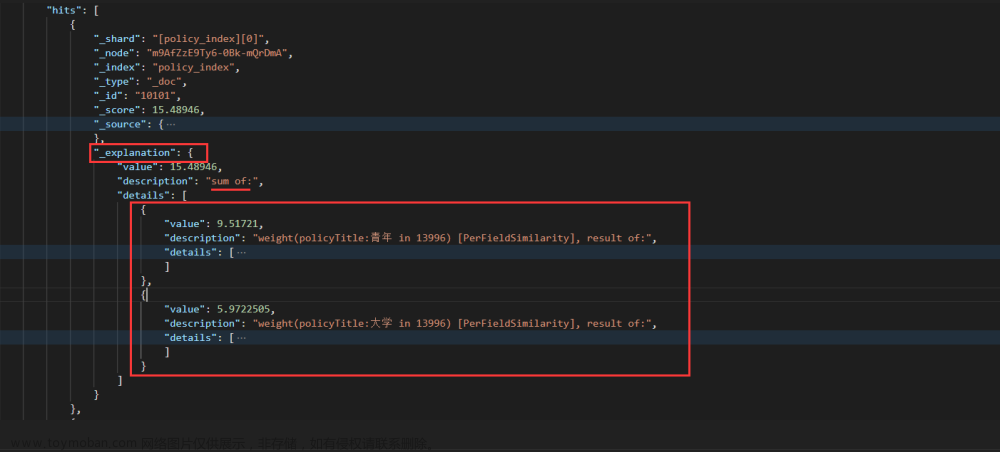
可以看到结果集中的一条结果 explanation 中就是评分的具体信息:
score(总分)=15.48946=score_value(“青年”)+score_value(“大学”)
policyTitle 本身存入时和查询时使用的都是 ik_max_word 分词器 (不单独指定 search_analyzer 即查询默认使用 analyzer 对应的分词器),为细粒度划分,“青年大学习” 被拆分为多个 (可以通过切换分词器或自定义专业词库的形式避免,这里仅做评分解析就不管了)

上面的查询结果中被拆分为青年 + 大学,根据分词结果,青年 + 学习也是可以被检索到的 (三者都有也行):

即查询请求会根据分词器在 ES 内部被重写为以下结构:
"bool": {
"should": [
{"term": { "policyTitle": "青年" }},
{"term": { "policyTitle": "大学" }},
{"term": { "policyTitle": "学习" }}
]
}
}
2.2. 单独分词分数
参考:
博客:https://www.cnblogs.com/wangchuanfu/p/7452809.html
官方文档:https://www.elastic.co/guide/en/elasticsearch/guide/master/relevance-intro.html
https://www.elastic.co/guide/en/elasticsearch/guide/master/scoring-theory.html
单独查看第一篇文档中” 青年” 的得分:9.51721
score(freq=2.0), computed as boost * idf * tf from:
即 score=boost * idf * tf

具体参数:
(一)TF/IDF 评分模型
(1)tf-- 频率
该术语在本文档中出现的频率如何?次数越多,分数越高
如果您不关心术语在字段中出现的频率,而您只关心该术语是否存在,那么您可以在字段映射中禁用术语频率:
(2)idf-- 逆文档频率
该术语在集合中的所有文档中出现的频率是多少?次数越多,分数越低




(二) 向量空间评分模型
具体见官网:https://www.elastic.co/guide/en/elasticsearch/guide/master/scoring-theory.html#vector-space-model
介绍:
向量空间模型提供了一种将多项查询与文档进行比较的方法。输出是一个单一的分数,表示文档与查询的匹配程度。为了做到这一点,模型将文档和查询都表示为向量。
向量实际上只是一个包含数字的一维数组,例如:
[1,2,5,22,3,8]在向量空间模型中,向量中的每个数字都是一个词的权重,用词频 / 逆文档频率计算 (词语越稀有,权重越大)。
(虽然 TF/IDF 是计算向量空间模型项权重的默认方法,但它不是唯一的方法。其他模型如 Okapi-BM25 存在并且在 Elasticsearch 中可用。TF/IDF 是默认值,因为它是一种简单、高效的算法,可以产生高质量的搜索结果,并且经受住了时间的考验。)
待匹配内容会根据数组向量形成一条线,而文档中与其匹配的内容也会形成对应的线,那么线越靠近就说明结果越匹配。
(三) 实用评分函数
对于多项查询,Lucene 采用布尔模型、 TF/IDF 和向量空间模型,并将它们组合在一个高效的包中,一旦文档与查询匹配,Lucene 就会计算该查询的分数,并结合每个匹配项的分数。用于评分的公式称为实用评分函数。
score(q,d) =
queryNorm(q)
· coord(q,d)
· ∑ (
tf(t in d)
· idf(t)²
· t.getBoost()
· norm(t,d)
) (t in q)
1.queryNorm--查询规范化因子
是对查询进行规范化的一种尝试,以便可以将一个查询的结果与另一个查询的结果进行比较。
尽管查询规范的目的是使不同查询的结果具有可比性,但效果并不理想。相关性_score的唯一目的是按照正确的顺序对当前查询的结果进行排序。您不应该尝试比较来自不同查询的相关性分数。
每个文档的查询规范化因子相同,无法更改。
2.coord--协调因子
用于奖励包含较高百分比查询词的文档。文档中出现的查询词越多,文档与查询匹配的可能性就越大,分数越高。
也就是同时包含“青年”“大学”“学习”的文档的分数不仅仅是三者相加的分数,而是会使用协调因子将分数乘以文档中匹配项的数量,然后除以查询中的项总数。
3.tf--词频
4.idf--逆文档频率
5.t.getBoost()--查询提升
用于增加查询中某个字段的重要性:https://www.elastic.co/guide/en/elasticsearch/guide/master/query-time-boosting.html
6.norm--场长范数
字段有多长?字段越短,权重越高。
如果一个术语出现在一个短字段中,那么与同一个术语出现在一个更大的字段中相比,认为更匹配,分数更高。

- 总结
查询分数 = 分词分数之和
分词分数 = boost 提升 * tf 词语出现频率 * idf 词语在所有文档的此字段中出现频率,其他的参数根据需求设定
三、ES 自定义评分规则
即 function_score,这个之前有比较详细的讲解,更具体的案例应用和参数讲解见官网:https://www.elastic.co/guide/en/elasticsearch/guide/master/function-score-query.html
在我的案例中使用的是在 policyTitle+textContent 中查询词语,并根据省份 + 分类得到一个比例与查询分数进行相乘的形式来计算 score,发送 query 请求并 explain 查看是否符合我们设定的需求:
总分:39.185825
- 查询得分:10.312058
由词语在 policyTitle 和 textContent 中的分数之和组成,正常√

- 自定义得分:3.8000002
由 script_score 和衰减函数 linear 的得分 2.8+1 组成,正常√
其中 script_score 由分类决定,如果分类与用户的用户画像分类匹配,返回指定权重的分数,用户画像由类似
{金融贸易 = 0.70000005, 医疗健康 = 0.1, 其他 = 0.1, 工业 = 0.1} 形式构成,说明用户常看金融类,那么金融类的得分会更高。

总分 = 查询得分 * 自定义得分,正常√,这样就会让符合条件的文档分数大幅提高
- 测试
上面查询的是一个没有特别属性的中义词,会返回令人满意的结果,下面搜索一些具有特殊省份、分类的词语,观察 function_score 是否会因为设定的省份和分类而极大影响,导致返回不合理的结果。
(1) 特殊省份
根据分类判断,正常√

(2) 特殊分类
这里发现省份和分类的影响还是很大的
除非查询本身的分数很高,否则会更倾向于符合 function 中分类和省份的结果。。
搜索:工业废水


(3) 特殊省份 + 特殊分类
这里体现的更明显,由于省份分数为 0/1,在查询时甚至完全忽略省份,完全由分类决定
搜索:北京工业废水

考虑控制分类的返回值不超过 1.5,尽管用户可能在某一个分类中经常浏览,但是为了避免搜素结果过多的由分类决定而导致查询的结果不理想,于是进行一定的权重控制。控制不匹配分类等的最低返回值为 1,这样即使分类、省份都不匹配,如果查询得分很高依然不会受到太大影响,不至于让用户完全无法看到这样的结果。
这样一来,保证 function 无论如何在 1-2.5 之间。(考虑通过衰减因子改变省份的值,例如不再是 0/1,而是 0/0.5,从而减小省份的影响,形成 1-2 的 function 分数 – 最终选择的方案)
(4) 修改后再次查询
①特殊分类:工业废水
文档相关性占比很大,分类和省份占比 (1-2)

②特殊省份 + 特殊分类:北京工业废水
这里发现由于在文档中查询 “北京工业废水”,由于查询分数不会专注于“北京”,因此往往会按照“工业废水” 的高评分 * 自定义评分来得到高分,暂时想到的解决是:
如果涉及特殊省份的查询,引导用户自己单独选中侧边栏的省份选项后再查询 (告知用户这样搜索效果更好)
去除 TF 词频的影响,即不在意词语在文档中出现了多少次,只在意是否出现,那么就可以比较好的保证文档中能出现大部分的搜索语句,但是这个就涉及到用户希望出现的结果是什么样的,需要考虑。

四、总结
总之,score = 查询得分 (分词得分之和) 与自定义得分综合计算的结果,其中查询得分涉及比较多,不太好改,而且考虑到查询结果对不同用户的得分观感都是不一样的,不可能用匹配度之类的确切结果进行描述,于是选择以排名第一的结果为 100 分,将分数称为 “推荐指数” 等形式的主观词汇,当然后续根据用户体验还会尝试修改,目前想到的解决方案就是这样了。文章来源:https://www.toymoban.com/news/detail-808147.html
参考链接:
https://blog.csdn.net/qq_51641196/article/details/130073774?spm=1001.2014.3001.5502文章来源地址https://www.toymoban.com/news/detail-808147.html
到了这里,关于elasticsearch[七]:ES评分规则详解[查询评分规则、自定义评分规则]的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!



![ElasticSearch[八]:自定义评分功能、使用场景讲解以及 function_score常用的字段解释](https://imgs.yssmx.com/Uploads/2024/01/820889-1.png)





