本文来自于《Large language models, explained with a minimum of math and jargon》,不嵌入任何笔者的个人理解,只是对原文的总结与记录。
文章作者是Tim Lee和Sean Trott,Tim Lee是一位拥有计算机科学硕士学位的记者,Sean Trott是加州大学圣地亚哥分校的认知科学家。
当ChatGPT于去年秋天推出时,它在科技行业和更大的世界中引发了冲击波,至今天,几乎每个人都听说过LLM,并且有数千万人尝试过它们,但是仍然没有多少人了解它们是如何工作的,大多数人只听说过LLM被训练成“预测下一个单词”,并且它们需要大量的文本来做到这一点,但仅此而已。
而由于LLM的开发方式与传统软件那种由人类程序员提供明确的分步指令不同,ChatGPT建立在数十亿个普通语言单词训练的神经网络上,因此,地球上没有人完全了解LLM的内部工作原理,这需要再过数年或数十年才能被人类完全解析。
本文则试图通过不使用技术术语或高级数学的方式下,令普罗大众对LLM内部的工作原理有一定的理解。
本文将首先解释词向量,然后将深入研究Transformer,最后将解释这些模型是如何训练的。
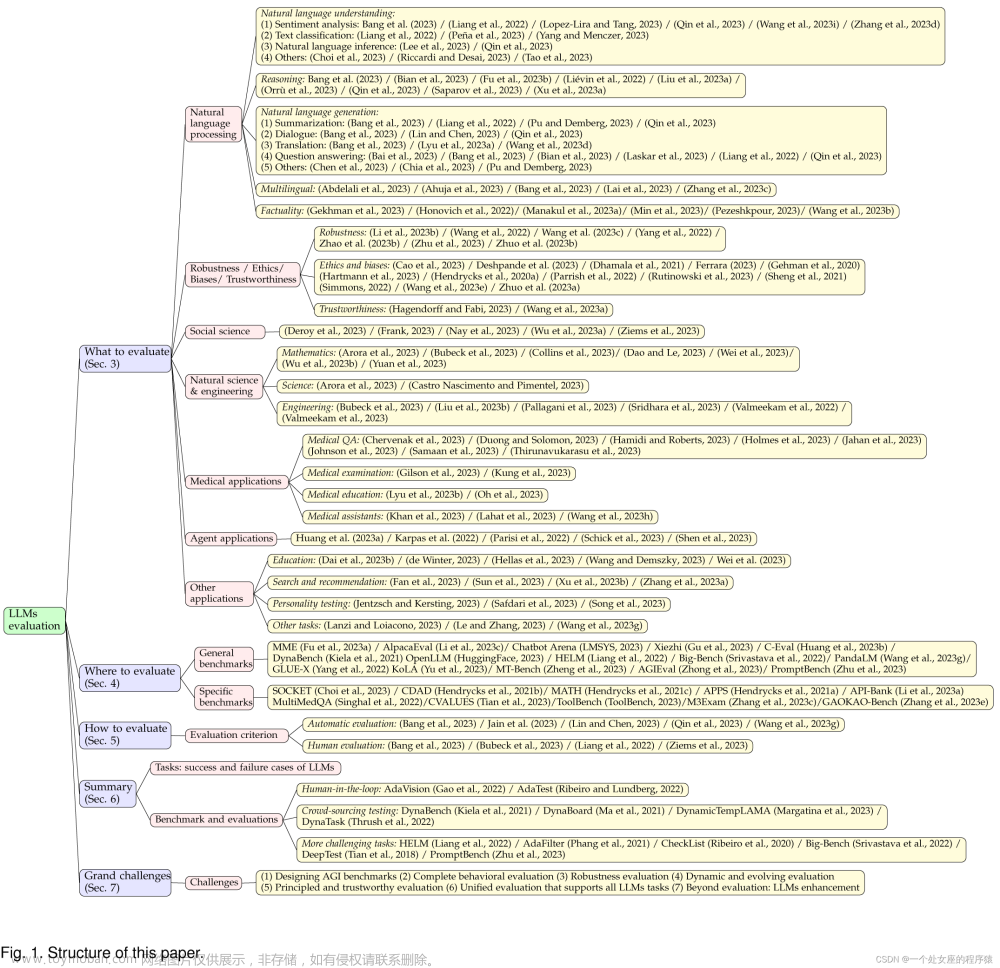
1 Word vectors 词向量
词向量是LLM用于表示单词的方式,它是一长串数字,如下是表示单词cat的词向量:
LLM使用词向量的原因是:
(1) 假设有一个词空间,通过词向量的数值的远近,用于表示两个或多个词之间是否有相似的含义,例如,在词空间中,最接近猫的词包括狗和宠物等;
(2) 词向量由于由数值构成,因此可以通过词向量的运算来“推理”单词,例如,谷歌研究人员将单词“biggest”的词向量,去掉“big”的词向量,再加上“small”的词向量,最终推理出来的是“smallest”;

词向量真正开始被提出并广而研究,是Google于2013年提出的word2vec项目,谷歌分析了从谷歌新闻收集的数百万份文档,以确定哪些单词往往出现在相似的句子中,随后,一个神经网络被训练来预测哪些单词与其他哪些单词同时出现,学会了在词空间中将相似的单词放在一起。
词向量当然还有其他的计算方式,比如用于类比,谷歌的词向量捕捉到了一些其他的关系:
(1) 瑞士人之于瑞士(Swiss is to Switzerlands),就像柬埔寨人之于柬埔寨(Cambodian is to Cambodia);
(2) 巴黎之于法国(Paris is to France),就像柏林之于德国(Berlin is to Germany);
(3) 不道德之于首先(Unethical is to Ethical),就像可能之于不可能(Possibly is to Impossibly);
(4) Mouse之于Mice(老鼠),就像Dollar之于Dollars(美元);
(5) 男人之于女人(Man is to Woman),就像国王之于王后(King is to Queen);
而由于这些向量是根据人类使用单词的方式构建的,因此它们也反射出了人类语言中存在的偏见(Bias),例如,在一些向量模型中,Doctor(医生)减去Man(男人)加上Woman(女人)的结果是Nurse(护士),而减轻这种偏见,也是词向量研究的一个重要领域。
词向量是语言模型中很重要的部分,它们编码了有关单词之间微妙但重要的信息——如果语言模型学习了一些有关于猫的知识,例如它有时会去看宠物,那么小狗或者其他宠物也应该会有类似的动作;如果语言模型对巴黎和法国之间的关系有所了解,那么它也有可能认识到柏林和德国的关系,以及罗马和意大利之间的关系。
2 词义取决于上下文
由于单词通常具有多种含义,因此简单的词向量方案并不总能准确地描述自然语言的事实信息。
例如以下两个句子:
(1) John picks up a magazine.
(2) Susan works for a magazine.
magazine在这两个句子中虽然意义相近,但并不相同,John拿起的是一本杂志,而Susan则是在一家出版社工作。
而bank在以下两个句子中的含义则并不相同:
(1) The bank wired John the money.
(2) The university is on the left bank of the river.
第一句中bank的意思是银行,第二句中的bank则表示河流旁边的土地。
当一个词有两个不相关的含义时,就像bank一样,称为同音异义词(homonym);当一个词有两个密切相关的含义时,如magazine,称为多义词(polysemy)。
像ChatGPT这样的LLM能够根据该单词出现的上下文,用不同的向量表示同一个单词。例如表示银行的bank和表示河流旁边的bank的词向量是不一样的,表示杂志的magazine和表示杂志社的magazine也是不一样的。
3 将词向量转化为词预测
GPT-3是ChatGPT背后的大语言模型,它由数十层的Transformer组成,每一层都采用一系列向量作为输入(输入文本中的每个单词对应一组向量),并添加了一些信息用于阐明该单词的含义,以更好地预测下一个单词。
下面是一个示例:
Google在2017年的一篇具有里程碑意义的论文中,将LLM的这些具有神经网络架构的层(Layer)命名为Transformer。
示例中的结构是从下往上,最下面一层是部分句子,即“John wants his bank to cash the”,它将被通过word2vec转化为一组向量,作为第一层Transformer的输入。
第一层Transformer通过一定的思考,确认wants和cash两个词是动词,于是在这两个词后添加括号,标注其为动词,转化为向量后传递给下一层的Transformer(当然,这是一种用我们比较能简单理解的方式,实际上Transformer的处理更为复杂)。我们将在第一层Transformer之后添加的这些信息(verb)称为隐藏状态。
第二层Transformer也为这个句子添加了一些上下文:bank是一个财务机构,his是指John的。这时这个句子“John wants his bank to cash the”变成了“John wants(verb) his(John’s) bank(financial institution) to cash(verb) the”,括号中的单词为每一层的Transformer所学习到的内容。
当然,以上只是特意将Transformer的工作内容简化,使我们能够更好理解的一个例子,实际的LLM会包含更多层的Transformer,例如GPT-3包含了96层Transformer。
研究表明,LLM的前几层侧重于理解句子的语法并解决歧义,而后面的层则更偏重于对整个句子的高阶理解。
例如,当LLM“通读”一篇短篇小说时,它似乎会跟踪有关故事人物的各种信息:性别和年龄、与其他人物的关系、过去和现在的位置、个性和目标等等。
研究人员并不能确切地了解LLM是如何跟踪这些信息的,但从逻辑上讲,模型应该是通过修改隐藏状态向量(hidden state vectors)后,一层一层往下传递来实现信息跟踪的。
GPT-3使用了12288个维度的词向量,也就是说,每个词都由12288个数字的列表表示,是Google的word2vec的20倍,我们可以把这些额外的维度看作是一个“暂存空间”,GPT-3可以用它来存储每个词的上下文注释,即隐藏状态向量hidden state vectors,前几层的注释可以被后几层读取和修改,使模型能够逐渐加深对整个段落的理解。
假设我们使用96层的LLM来解释一个1000字的故事时,第60层可能包括John的注释信息,例如“(main character, male, married to Cheryl, cousin of Donald, from Minnesota, currently in Boise, trying to find his missing wallet)”,即“(主要性格、性别、跟Donald的表姐Cheryl结婚了、来自于Minnesota、目前在Boise、试图找到他丢失的钱包)”,而这些信息(甚至更多信息)将被以某种方式编码为一组与John关联的12288个数字的列表,而同样,故事中的其他单词例如Cheryl、Donald、Boise、Wallet等,也有可能有与之相关的12288维度的向量注释与之对应。
这些信息作为hidden state vectors,将一层一层地往后传递,传到第96层后,第96层即可根据这些信息,预测下一个单词的内容。
4 Transformer的内部逻辑
我们来看Transformer内部发生了什么,一般来讲,Transformer通过以下两步来新增或更新每个单词的隐藏状态hidden state:
(1) Attention Step,每个单词“环顾四周”,寻找具有相关上下文并相互共享信息的其他单词;
(2) Feed-Forward Step,每个单词“思考”上一步收集的信息,并尝试预测下一个单词;
LLM使用网状的方式来执行这两个步骤,这有益于LLM充分利用GPU芯片的大规模并行处理能力,且有助于LLM扩展到包含成千上万个单词的段落。
4.1 注意力步骤Attention Step
我们可以把注意力机制视为单词的匹配服务,在匹配服务执行过程中,每个单词都会生成一个查询向量清单,用于描述它所查找的单词的特征,同时会生成一个关键词向量清单用于描述其自身的特征。神经网络通过计算点积的方法,将每个关键词向量与每个查询向量进行比较以找到最匹配的单词,找到匹配项后,它会将信息从生成关键词向量的单词传输到生成查询向量的单词。
以上文中提到的“John wants his bank to cash the”为例,his的查询向量可能是“我在寻找描述男性的名词”,而John的关键词向量可能是“我是描述男性的名词”,于是神经网络经过点积计算后,将生成“我是描述男性的名词”这个关键词向量的单词John,传输到生成“我在寻找描述男性的名词”这个查询向量的单词his,即:

每个注意力层(attention layer)都有几个注意力头(attention heads),这意味着这种信息交换过程在每一层都会并行的发生几次,而每个注意力头的工作不一样:
(1) 一些注意力头可能会将代词与名词匹配;
(2) 一些注意力头可能专注于解决同意异义词的含义;
(3) 一些注意力头可能会将两个词的短语联系在一起,例如“John Biden”;
等等。
注意力头通常都是按顺序操作,一层注意力头操作的的结果成为下一层注意力头的输入,而每一项任务都经常需要几个注意力头的工作。
GPT-3的最大版本有96层,每一层有96个注意力头,因此GPT-3每次预测一个新词时,都会执行9216次注意力操作。
接下来我们来看一下真实环境中,LLM内部是如何工作的。
去年,Redwood Research的研究人员对GPT-2如何预测“When Mary and John went to the store, John gave a drink to”的下一个词进行了研究。
GPT-2预测到下一个单词是Mary,研究人员发现,有三种类型的注意力头促成了这一预测:
(1) 他们称之为名称移动头(Name Mover Heads)的三个注意力头将信息从Mary向量复制到最终的输入向量to,GPT-2使用to中的信息来预测下一个单词;
(2) 被称为主语抑制头(Subject Inhibition Heads)的四个注意力头将John进行标记,阻止名称移动头将John的信息复制到to中;
(3) 标记重复头(Duplicate Token Heads)的二个注意力头将第二个John向量标记为第一个John向量的副本,以辅助主语抑制头决策不复制John的信息到to的hidden state中;
简而言之,这九个注意力头使GPT-2能够发现“John gave a drink to John”(John给John喝了一杯)是无意义的,而决策应该是“John gave a drink to Mary”。
虽然Redwood Research的五人团队做了这些研究,并且发表了一篇25页的论文来阐述他们是如何识别和验证这些注意力,但这仍然不足以全面解释为什么GPT-2会决策Mary是下一个单词,例如在另一些句子“when Mary and John went to the restaurant, John gave his key to”中,显然预测Mary是这个句子的下一个词并不怎么合理,更合理的是“the valet”服务员。
4.2 前馈步骤Feed-forward Step
注意力头在词向量之间传递信息之后,是一个前馈网络(Feed-forward network),前馈网络“思考”每个词向量并试图预测下一个词。前馈步骤阶段会单独分析每个单词,且能访问之前由注意力头复制的任何信息,但不会进行任何信息交换。
以下是GPT-3的最大版本中前馈层的结构:

其中绿色和紫色的圆圈是神经元:计算输入加权和的数学函数。
这只是GPT-3前馈层的基本结构,GPT-3前馈层的实际结构,比这要复杂得多,其输出层有12288个神经元(对应于模型的12288维度的词向量),隐藏层有49152个神经元。
因此在最大版本的GPT-3中,前馈层的隐藏层中有49152个神经元,每个神经元有12288个输入(因此有12288个权重参数)。而每个神经元有12288个输出神经元,有49152个输入值(因此有49152个权重参数),这意味着每个前馈层有4915212288+1228848152=12亿个权重参数。而由于有96个前馈层,因此总共有12亿*96=1160亿个参数。
在2020年的一篇论文中,Tel Aviv University大学的研究人员发现,前馈层通过模式匹配来工作——隐藏层中的每个神经元都匹配输入文本中的特定模式。

以下是16层版本的GPT-2中神经元匹配的一些模式:
(1) 第 1 层中的神经元匹配以“substitutes”结尾的单词序列;
(2) 第 6 层中的神经元匹配与军事相关的序列,并以“base”或“bases”结尾;
(3) 第 13 层中的神经元匹配以“下午 3 点到 7 点之间”或“从周五晚上 7:00 到”等时间范围结尾的序列;
(4) 第 16 层中的神经元匹配与电视节目相关的序列,例如“原始的NBC日间版本已存档”或“时间延迟使该集的观众增加了57%”;
正如我们所见,模式在后面几层中变得越来更加抽象,早期的层倾向于匹配特定的单词,而后期的层匹配更广泛的语义类别(如电视节目或时间间隔)的短语。这种匹配当然不是因为前馈层一次性检查了多个单词,而是因为“原始的NBC日间版本已存档”或“时间延迟使该集的观众增加了57%”这些向量已经被加入到“archived”这个词的关键词向量中,在“Television”进行查询时,注意力头将archived的关键词向量复制到了archived向量的隐藏向量中。
当神经元匹配其中一种模式时,它会向词向量添加信息。虽然这些信息并不总是容易解释,但在许多情况下,您可以将其视为对下一个单词的初步预测。
对于前馈层,Brown University的研究员基于24层的GPT-2,对其如何预测“Q: What is the capital of France? A: Paris Q: What is the capital of Poland? A:”进行了进一步研究,研究人员发现,GPT-2的前15层看起来像是在进行随意猜测,而在第16至19层,GPT-2猜测出答案应该是Poland(虽然不对,但更加接近),而在第20层,GPT-2得出结论是Warsaw这个正确答案,并在后续的几层一直保持了这个正确答案。
Brown University的研究员发现,第20个前馈层通过添加一个向量,将国家向量映射到其相应首都的向量,将Ploand转化为Warsaw,这种处理方式称为向量计算(Vector Arithmetic),它能完成类似于将小写单词转换为大写单词、将现在时态转换为过去时态等工作。
因此,注意力头(Attention Heads)从提示中较早的单词中检索信息,而前馈层(Feed-forward Layers)使语言模型能够“记住”提示中没有的信息。
5 如何训练语言模型
许多早期的机器学习算法要求训练样本由人类手工标记。例如,训练数据可能是狗或猫的照片,每张照片都有人工提供的标签(“狗”或“猫”)。人类需要标记数据,这使得创建足够大的数据集来训练强大的模型变得困难且昂贵。
LLM 的一个关键创新是它们不需要明确标记的数据。相反,他们通过尝试预测普通文本段落中的下一个单词来学习。几乎任何书面材料(从维基百科页面到新闻文章再到计算机代码)都适合训练这些模型。
例如,一个 LLM 可能会被输入“我喜欢我的奶油咖啡”,并应该预测“糖”作为下一个单词。一个新初始化的语言模型在这方面将非常糟糕,因为它的每个权重参数(在最强大的 GPT-3 版本中为 1750 亿个)都将从一个基本上是随机数开始。但是,随着模型看到更多的例子(数千亿个单词),这些权重会逐渐调整,以做出越来越好的预测。
我们可以这样类比,假设你要去洗澡,你希望温度恰到好处:不要太热,也不要太冷。您以前从未使用过这个水龙头,因此您将旋钮指向随机方向并感受水温。如果太热,你把它转向一个方向;如果天气太冷,你就把它转向另一个方向。越接近合适的温度,所做的调整就越小。
现在让我们对这个类比做一些改动。首先,假设有 50,257 个水龙头,而不仅仅是一个。每个水龙头对应一个不同的词,如猫或银行。你的目标是让水只从水龙头中流出,与序列中的下一个单词相对应。
其次,水龙头后面有一堆相互连接的管道,这些管道上也有一堆阀门。因此,如果水从错误的水龙头流出,您可以调整水龙头上的旋钮。你派出一群聪明的松鼠向后追踪每根管道,并调整它们沿途发现的每个阀门。
这会变得很复杂,因为同一根管道可能对接了多个水龙头。因此,需要仔细考虑才能弄清楚哪些阀门要拧紧,哪些阀门要松动,以及松动多少。
显然,如果你从字面上理解它,这个例子很快就会变得非常难以理解。建立一个拥有 1750 亿个阀门的管道网络既不现实也没有用。但多亏了摩尔定律,计算机可以而且确实在这种规模下运行。
到目前为止,我们在本文中讨论的LLM的所有部分——前馈层中的神经元和在单词之间移动上下文信息的注意力头——都是作为一个简单的数学函数链(主要是矩阵乘法)实现的,其行为由可调整的权重参数决定。就像我故事中的松鼠松开和拧紧阀门来控制水流一样,训练算法也会增加或减少语言模型的权重参数来控制信息如何流经神经网络。
训练过程分两步进行。首先有一个“前进通道”,打开水,检查它是否从正确的水龙头流出。然后关掉水,有一个“后退通道”,松鼠沿着每根管道奔跑,拧紧和松开阀门。在数字神经网络中,松鼠的角色由一种称为反向传播的算法扮演,该算法在网络中“向后行走”,使用微积分来估计每个权重参数的变化程度。
完成这个过程——对一个示例进行前向传递,然后向后传递以提高网络在该示例上的性能——需要数千亿次数学运算。训练像 GPT-3 这样大的模型需要重复该过程数十亿次——每个训练数据字一次。 OpenAI 估计,训练 GPT-3 需要超过 3000 亿万亿次浮点计算——这相当于数十种高端计算机芯片的数月工作。
6 综述
我们来尝试进行总结:
(1) LLM使用词向量来表示单词,每个单词的词向量都是一长串数字,被存储在向量空间中,并且由于是数值,因此可以通过运算来进行推理,例如通过运算判断某两个单词之间的关系等;
(2) 由于存在同音异义词和多义词,因此虽然是同一个单词,在向量空间中可能存储在不同的位置,而不同单词可能存储在相近位置,单词的具体词义取决于上下文;
(3) LLM由数十层的Transformer组成,第一层Transformer接受用户的输入(被转化为词向量),然后进行词向量运算和处理后,生成的数据(向量)会被存储在隐藏状态中,然后将原始向量和隐藏状态一起作为输入传给第二层Transformer;第二层Transformer接收到第一层的原始向量和隐藏状态后,继续进行处理,更新隐藏状态,然后将原始向量和新的隐藏状态继续传到第三层Transformer,依此类推;每一层都根据上一层输入的原始向量和隐藏状态进行下一个单词的预测,随着隐藏状态的越来越丰富和准确,使得预测结果越来越准确;
(4) 每一层Transformer内部的处理逻辑类似——注意力头(Attention Heads)从提示中较早的单词中检索信息,而前馈层(Feed-forward Layers)使语言模型能够“记住”提示中没有的信息:
1) Attention Step,注意力步骤,寻找具有相关上下文并相互共享信息的其他单词,每个单词都会生成一个查询向量清单,用于描述它所查找的单词的特征,同时会生成一个关键词向量清单用于描述其自身的特征。神经网络通过计算点积的方法,将每个关键词向量与每个查询向量进行比较以找到最匹配的单词,找到匹配项后,它会将信息从生成关键词向量的单词传输到生成查询向量的单词;
2) Feed-forward Step,前馈步骤,注意力步骤传递信息之后,前馈步骤阶段会单独分析每个单词,且能访问之前由注意力头复制的任何信息,但不会进行任何信息交换,每个单词“思考”上一步收集的信息,并尝试预测下一个单词;
(5) LLM的每一层Transformer都有多个注意力头(一般跟Transformer的层数相同),每个注意力头进行的单词匹配工作和机制都不一样,注意力头通常都是按顺序操作,一层注意力头操作的的结果成为下一层注意力头的输入,而每一项任务都经常需要几个注意力头的工作;
(6) 前馈层由一个神经网络构成,也称多层感知器,神经元的数量即权重参数的数量,如上文所述,GPT-3的前馈层有1160亿个参数,每一层前馈层完成不同的工作,使用向量数学进行推理并得出结果;
(7) LLM不需要通过明确标记的数据进行学习,他们通过尝试预测普通文本段落中的下一个单词来学习,随着模型学习到越多的例子,前馈网络中的参数权重会逐步调整,以做出越来越好的预测,规模越大,LLM的能力越强;
7 写在最后
原文地址:https://www.understandingai.org/p/large-language-models-explained-with
对应视频讲解:https://www.youtube.com/watch?v=dIyQl99oxlg文章来源:https://www.toymoban.com/news/detail-808483.html
鄙文所述,或有未尽周详之处,所论观点仅供诸君参考,切莫尽信,盖因学识有限,难免挂一漏万,敬请方家不吝指正。文章来源地址https://www.toymoban.com/news/detail-808483.html
到了这里,关于大型语言模型,用最少的数学和行话进行解释的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!