1、kafka消费者消费方式
kafka 的消费者(Consumer)采用 pull 的方式主动从 broker 中拉取数据,这种不足之处会有:当 broker 中没有消息时,消费者会不断循环取数据,一直返回空数据。
2、消费者组
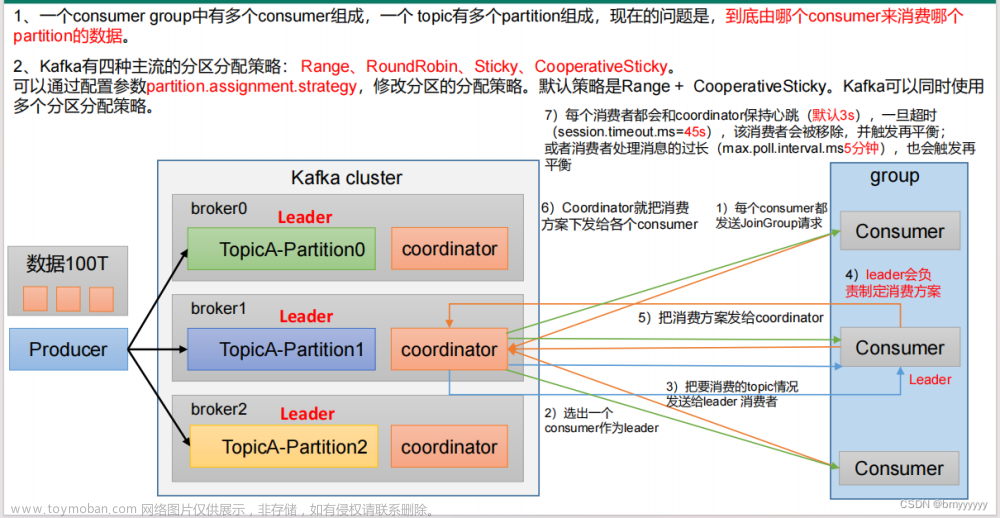
Consumer Group(CG):消费者组,由多个consumer组成。形成一个消费者组的条件,是所有消费者的 group_id 相同。
1)、 消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费。 2)、消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
3)、在命令行中,使用消费者消费消息没有指定消费者组,会自动分配一个消费者组,而不是没没有消费者组。
4)、如果向消费组中添加更多的消费者大于主题分区数量,则有一部分消费者就会闲置,不会接收任何消息。
5)、如果消费组中的消费者小于主题分区数量,则部分消费者消费的分区数量不止一个。
2.1、消费者重要参数
| 参数名称 | 描述 |
|---|---|
| bootstrap.servers | 向Kafka 集群建立初始连接用到的host/port 列表。示例:node-1:9092,node-2:9092... |
| key.deserializer 和value.deserializer | 指定接收消息的key 和value 的反序列化类型。一定要写全限定类名。 |
| group.id | 标记消费者所属的消费者组。(必须参数) |
| enable.auto.commit | 默认值为true,消费者会自动周期性地向服务器提交偏移量。 |
| auto.commit.interval.ms | 如果设置了 enable.auto.commit 的值为true, 则该值定义了消费者偏移量向Kafka 提交的频率,默认5s。 |
| auto.offset.reset | 当Kafka 中没有初始偏移量或当前偏移量在服务器中不存在(如,数据被删除了),该如何处理? earliest:自动重置偏移量到最早的偏移量。 latest:默认,自动重置偏移量为最新的偏移量。 none:如果消费组原来的(previous)偏移量不存在,则向消费者抛异常。 anything:向消费者抛异常。 |
| offsets.topic.num.partitions | __consumer_offsets 的分区数,默认是50 个分区。 |
| heartbeat.interval.ms | Kafka 消费者和coordinator 之间的心跳时间,默认3s。该条目的值必须小于 session.timeout.ms ,也不应该高于session.timeout.ms 的1/3。 |
| session.timeout.ms | Kafka 消费者和coordinator 之间连接超时时间,默认45s。超过该值,该消费者被移除,消费者组执行再平衡。 |
| max.poll.interval.ms | 消费者处理消息的最大时长,默认是 5 分钟 。超过该值,该消费者被移除,消费者组执行再平衡。 |
| fetch.min.bytes | 默认1个字节。消费者获取服务器端一批消息最小的字节数。 |
| fetch.max.wait.ms | 默认500ms 。如果没有从服务器端获取到一批数据的最小字节数 。该时间到,仍然会返回数据。 |
| fetch.max.bytes | 默认Default: 52428800 (50m)。消费者 获取 服务器端 一 批消息最大的字节数 。如果服务器端一批次的数据大于该值50m)仍然可以拉取回来这批数据,因此,这不是一个绝对最大值。一批次的大小受 message.max.bytes (broker config) or max.message.bytes (topic config)影响。 |
| max.poll.records | 一次poll拉取数据返回消息的最大条数, 默认是 500 条 。 |
2.2、消费者代码实现
2.2.1、引入依赖
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.6.1</version>
</dependency>2.2.2、消费者代码实现(自定义消费者组实现)
public class KafkaConsumerTest {
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "node-1:9092,node-2:9092");
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
// 指定分区策略
properties.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG, "org.apache.kafka.clients.consumer.RoundRobinAssignor");
// 指定消费者组,必须参数
properties.put(ConsumerConfig.GROUP_ID_CONFIG, " test1");
KafkaConsumer<String,String> consumer = new KafkaConsumer<>(properties);
// 订阅主题,可以定义多个主题
List<String> topics = new ArrayList<>();
topics.add("topic1");
// 订阅
consumer.subscribe(topics);
while (true){
// 拉取消息
ConsumerRecords<String, String> msg = consumer.poll(Duration.ofSeconds(1));
for (ConsumerRecord<String, String> consumerRecord : msg) {
System.out.println(consumerRecord);
System.out.println(consumerRecord.value());
}
}
}
}2.2.3、消费者代码实现(指定主题分区实现)
public class KafkaConsumerTest {
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "node-1:9092,node-2:9092");
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
// 指定分区策略
properties.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG, "org.apache.kafka.clients.consumer.RoundRobinAssignor");
// 指定消费者组,必须参数
properties.put(ConsumerConfig.GROUP_ID_CONFIG, " test1");
KafkaConsumer<String,String> consumer = new KafkaConsumer<>(properties);
// 订阅主题分区
List<TopicPartition> topicPartitions = new ArrayList<>();
topicPartitions.add(new TopicPartition("topic1", 1));
consumer.assign(topicPartitions);
while (true){
// 拉取消息
ConsumerRecords<String, String> msg = consumer.poll(Duration.ofSeconds(1));
for (ConsumerRecord<String, String> consumerRecord : msg) {
System.out.println(consumerRecord);
System.out.println(consumerRecord.value());
}
}
}
}3、总结
本文介绍kafka的消费者是如何消费消息,简单介绍消费者的使用,关于消费者更高级的部分,关注我,在博客和微信公众号中都会发布。
本人是一个从小白自学计算机技术,对运维、后端、各种中间件技术、大数据等有一定的学习心得,想获取自学总结资料(pdf版本)或者希望共同学习,关注微信公众号:it自学社团。后台回复相应技术名称/技术点即可获得。(本人学习宗旨:学会了就要免费分享)文章来源:https://www.toymoban.com/news/detail-808508.html
 文章来源地址https://www.toymoban.com/news/detail-808508.html
文章来源地址https://www.toymoban.com/news/detail-808508.html
到了这里,关于kafka之消费者(Consumer)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!