系列文章目录
李沐《动手学深度学习》预备知识 张量操作与数据处理
教材:李沐《动手学深度学习》
一、线性代数
(一)标量、向量、矩阵、张量
-
标量(scalar)
仅包含一个数值被称为标量,标量由只有一个元素的张量表示。import torch x = torch.tensor(3.0) y = torch.tensor(2.0) x + y, x * y, x / y, x**y -
向量
向量可以被视为标量值组成的列表,向量由一维张量表示。一般来说,张量可以具有任意长度,取决于机器的内存限制。x=torch.arange(4) x向量中的标量值被称为元素或分量。在代码中,可以通过张量的索引来访问任一元素。
x[3]向量的长度、维度、形状
向量的长度通常称为向量的维度(dimension),与普通的Python数组一样,可以通过调用Python的内置len()函数来访问张量的长度。len(x)形状(shape)是一个元素组,列出了张量沿每个轴的长度(维数)。
x.shape -
矩阵
矩阵通常用粗体、大写字母来表示, 在代码中表示为具有两个轴的张量。A=torch.arange(20).reshape(5,4) A矩阵的转置
A.T -
张量
张量是描述具有任意数量轴的维数组的通用方法。
当我们开始处理图像时,张量将变得更加重要,图像以维数组形式出现, 其中3个轴对应于高度、宽度,以及一个通道(channel)轴, 用于表示颜色通道(红色、绿色和蓝色)。
(二)张量运算的基本性质
标量、向量、矩阵和任意数量轴的张量有一些实用的属性。 例如,任何按元素的一元运算都不会改变其操作数的形状。 同样,给定具有相同形状的任意两个张量,任何按元素二元运算的结果都将是相同形状的张量。
矩阵的Hadamard积(Hadamard product)
两个矩阵的按元素乘法称为Hadamard积,数学符号为
⨀
\bigodot
⨀。矩阵A和矩阵B的Hadamard积为:
A
⨀
B
=
[
a
11
b
11
a
12
b
12
⋯
a
1
n
b
1
n
a
21
b
21
a
22
b
22
⋯
a
2
n
b
2
n
⋮
⋮
⋱
⋮
a
m
1
b
m
1
a
m
2
b
m
2
⋯
a
m
n
b
m
n
]
A\bigodot B=\begin{bmatrix} a_{11} b_{11} & a_{12}b_{12} & \cdots & a_{1n}b_{1n}\\ a_{21} b_{21} & a_{22}b_{22} & \cdots & a_{2n}b_{2n}\\ \vdots & \vdots & \ddots & \vdots \\ a_{m1} b_{m1} & a_{m2}b_{m2} & \cdots & a_{mn}b_{mn}\\ \end{bmatrix}
A⨀B=
a11b11a21b21⋮am1bm1a12b12a22b22⋮am2bm2⋯⋯⋱⋯a1nb1na2nb2n⋮amnbmn
将张量乘以或加上一个标量不会改变张量的形状,其中张量的每个元素都将与标量相加或相乘。
a=2
X=torch.arange(24).reshape(2,3,4)
a+X,a*X,(a*X).shape
(三)降维
- 计算张量元素的和
默认情况下,调用求和函数会沿所有的轴降低张量的维度,使它变为一个标量。
可以指定张量沿哪一个轴来通过求和降低维度。 在矩阵中,指定axis=0可以求和所有行的元素,指定axis=1可以求和所有列的元素。#向量求和 x=torch.arange(4,dtype=torch.float32) x,x.sum() #矩阵求和 A.sum()#按行求和 A_sum_axis0=A.sum(axis=0) A_sum_axis0 #按列求和 A_sum_axis1=A.sum(axis=1) #沿着行和列求和,等价于对所有元素求和 A.sum(axis=[0,1]) - 非降维求和
非降维求和是指在调用函数来计算总和时保持轴数不变。
由于sum_A在对每行进行求和后仍保持两个轴,我们可以通过广播将A除以sum_A。sum_A=A.sum(axis=1,keepdims=True) sum_A,sum_A.shape
调用cumsum函数可以沿某个轴计算A元素的累计总和,此函数不会沿任何轴降低输入张量的维度。A/sum_AA.cumsum(axis=0)
(四)点积
两个向量的点积是相同位置的按元素乘积的和。
import numpy as np
y=np.ones(4)
x,y,np.dot(x,y)
我们也可以通过执行按元素乘法,然后进行求和来表示两个向量的点积。
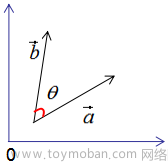
将两个向量规范化得到单位长度后,点积表示它们夹角的余弦。
(五)矩阵向量积、矩阵乘法
-
矩阵向量积
矩阵向量积Ax是一个列向量,其第i个元素是点积 a i T x a_i^Tx aiTx。在代码中使用mv函数表示矩阵-向量积。 当我们为矩阵A和向量x调用torch.mv(A, x)时,会执行矩阵-向量积。矩阵向量积运算要求A的列维数(沿轴1的长度)必须与x的维数(其长度)相同。
A.shape,x.shape,torch.mv(A,x) -
矩阵乘法
我们可以将矩阵-矩阵乘法看作简单地执行多次矩阵-向量积,并将结果拼接在一起,形成一个矩阵。在代码中使用mm函数表示矩阵乘法。B=torch.ones(4,3) torch.mm(A,B)
(六)范数
向量的范数表示一个向量有多大。 这里考虑的大小(size)概念不涉及维度,而是分量的大小。
在线性代数中,向量范数是将向量映射到标量的函数
f
f
f。 给定任意向量
x
x
x,向量范数满足一些属性:
- 如果我们按常数因子缩放向量的所有元素, 其范数也会按相同常数因子的绝对值缩放;
f ( α x ) = ∣ α ∣ f ( x ) f(\alpha x)=|\alpha|f(x) f(αx)=∣α∣f(x) - 三角不等式性质;
f ( x + y ) ≤ f ( x ) + f ( y ) f(x+y)\leq f(x)+f(y) f(x+y)≤f(x)+f(y) - 范数必须是非负的。
f ( x ) ≥ 0 f(x)\geq 0 f(x)≥0
常见的范数包括L1范数、L2范数、Frobenius范数等。
u=torch.tensor([3.0,-4.0])
#计算L2范数
print(torch.norm(u))
#计算L1范数
print(torch.abs(u).sum())
#计算Frobenius范数
print(torch.norm(torch.ones((4,9))))
在深度学习中,我们经常试图解决优化问题: 最大化分配给观测数据的概率; 最小化预测和真实观测之间的距离。 用向量表示物品(如单词、产品或新闻文章),以便最小化相似项目之间的距离,最大化不同项目之间的距离。 目标,或许是深度学习算法最重要的组成部分(除了数据),通常被表达为范数。
二、微积分(导数、偏导数、梯度、链式法则)
深度学习中模型拟合的任务可以分解为两个关键问题:
- 优化(optimization):用模型拟合观测数据的过程;
- 泛化(generalization):数学原理和实践者的智慧,能够指导我们生成出有效性超出用于训练的数据集本身的模型。
- 导数和微分
导数的计算是几乎所有深度学习优化算法的关键步骤。在深度学习中,我们通常选择对于模型参数可微的损失函数。简而言之,对于每个参数, 如果我们把这个参数增加或减少一个无穷小的量,可以知道损失会以多快的速度增加或减少。 - 偏导数
将微分的思想推广到多元函数(multivariate function)上,就涉及到了偏导数的思想。 - 梯度
连结一个多元函数对其所有变量的偏导数,就得到了该函数的梯度(gradient)向量。 - 链式法则
在深度学习中,多元函数通常是复合(composite)的,链式法则可以被用来微分复合函数。
三、自动微分
深度学习框架通过自动计算导数,即 自动微分(automatic differentiation)来加快求导。 自动微分使系统能够随后反向传播梯度。
实际中,根据设计好的模型,系统会构建一个计算图(computational graph),来跟踪计算是哪些数据通过哪些操作组合起来产生输出。 这里,反向传播(backpropagate)意味着跟踪整个计算图,填充关于每个参数的偏导数。
深度学习框架可以自动计算导数:我们首先将梯度附加到想要对其计算偏导数的变量上,然后记录目标值的计算,执行它的反向传播函数,并访问得到的梯度。
- 例1:
y
=
2
X
T
X
y=2X^TX
y=2XTX的梯度
#让 backward 可以追踪这个参数并且计算它的梯度 x.requires_grad_(True) x.grad y.backward() x.grad #返回:tensor([0., 4., 8., 12.]) - 例2:求和函数的梯度
#在默认情况下,PyTorch会累积梯度,我们需要清除之前的值 x.grad.zero_() y=x.sum() y.backward() x.grad #返回:tensor([1., 1., 1., 1.])
(一)非标量变量的反向传播
当y不是标量时,向量y关于向量x的导数的最自然解释是一个矩阵。 对于高阶和高维的y和x,求导的结果可以是一个高阶张量。
当调用向量的反向计算时,我们通常会试图计算一批训练样本中每个组成部分的损失函数的导数。 这里,我们的目的不是计算微分矩阵,而是单独计算批量中每个样本的偏导数之和。
# 对非标量调用backward需要传入一个gradient参数,该参数指定微分函数关于self的梯度。
# 本例只想求偏导数的和,所以传递一个1的梯度是合适的
x.grad.zero_()
y = x * x
# 等价于y.backward(torch.ones(len(x)))
y.sum().backward()
x.grad
(二)分离计算
假设y是作为x的函数计算的,而z则是作为y和x的函数计算的。 想象一下,我们想计算z关于x的梯度,但由于某种原因,希望将y视为一个常数, 并且只考虑到x在y被计算后发挥的作用。
这里可以分离y来返回一个新变量u,该变量与y具有相同的值, 但丢弃计算图中如何计算y的任何信息。 换句话说,梯度不会向后流经u到x。 因此,反向传播函数计算 z = u ∗ x z=u*x z=u∗x关于x的偏导数,同时将u作为常数处理, 而不是 z = x ∗ x ∗ x z=x*x*x z=x∗x∗x关于x的偏导数。
x.grad.zero_()
y = x * x
u = y.detach()
z = u * x
z.sum().backward()
x.grad == u
#返回:tensor([True, True, True, True])
由于记录了y的计算结果,我们可以随后在y上调用反向传播, 得到y=xx关于的x的导数,即2x。
x.grad.zero_()
y.sum().backward()
x.grad == 2 * x
#返回:tensor([True, True, True, True])
(三)Python控制流的梯度计算
使用自动微分的一个好处是: 即使构建函数的计算图需要通过Python控制流(例如,条件、循环或任意函数调用),我们仍然可以计算得到的变量的梯度。
在下面的代码中,while循环的迭代次数和if语句的结果都取决于输入a的值。文章来源:https://www.toymoban.com/news/detail-808553.html
def f(a):
b = a * 2
while b.norm() < 1000:
b = b * 2
if b.sum() > 0:
c = b
else:
c = 100 * b
return c
a=torch.randn(size=(),requires_grad=True)
d=f(a)
d.backward()
a.grad==d/a
#返回:tensor(True)
(四)pytorch代码的反向传播实现
PyTorch中的反向传播是通过自动微分(autograd)系统来实现的。自动微分是一种计算梯度的技术,它允许系统在计算图中跟踪操作,并自动计算相对于输入变量的梯度。PyTorch中反向传播的主要步骤:文章来源地址https://www.toymoban.com/news/detail-808553.html
- 张量创建时的跟踪: 当你创建一个张量时,PyTorch会自动开始跟踪它的操作,构建一个计算图;
import torch # 创建张量,并跟踪操作 x = torch.tensor([2.0], requires_grad=True) y = x**2 - 前向传播: 在计算图中执行操作,构成了前向传播过程。这通常包括各种张量运算,例如加法、乘法等。
# 执行前向传播 z = y * 3 - 梯度计算: 在需要计算梯度的张量上调用 backward() 方法。这个方法会根据计算图和链式法则计算相对于每个叶子节点的梯度。
# 计算梯度 z.backward() - 梯度传播: PyTorch使用链式法则来将梯度从输出传播到输入。梯度计算的结果存储在每个涉及到的张量的 .grad 属性中。
# 输出梯度 print(x.grad) - 梯度清零: 在进行多次反向传播时,通常需要在每次反向传播之前将梯度清零,以防止梯度的累积影响。
x.grad.zero_()
四、概率
- 基本概率论
概率论公理、随机变量 - 处理多个随机变量
联合概率、条件概率、贝叶斯定理、边际化、独立性 - 期望和方差
到了这里,关于李沐 《动手学深度学习》预备知识 线性代数与微积分的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!