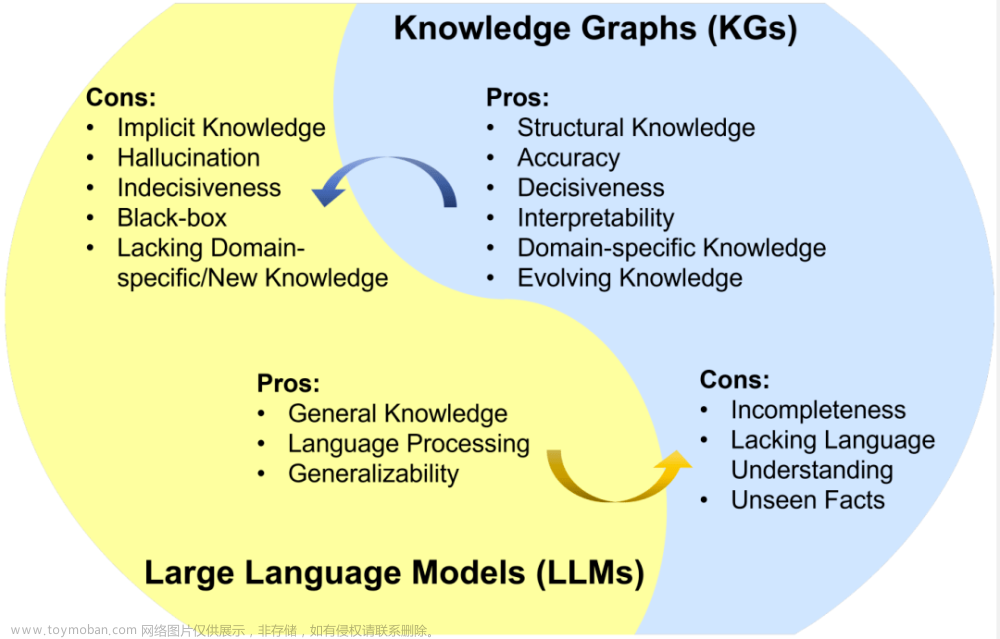
我们在以前的文章中已经介绍了使用大语言模型将非结构化文本转换为知识图谱。但是对于知识图谱的创建是一个很复杂的过程,比如需要对属性增加限制,创建符合特定主题/模式的图谱,并且有时文档非常大,无法作为单个提示处理,所以在切分后的提示中创建的图谱需要前后一致。

所以本文将介绍和比较使用LLM转换非结构化文本的四种方法,这些方法在不同的场景中都可能会用到。

使用LLM预训练本体(ontologies)
LLM似乎已经接受了各种标准本体(如SCHEMA)的预先培训。ORG, FOAF, SKOS, RDF, RDFS, OWL等。所以通过适当的系统提示来指导使用这个预训练的本体,再加上包含非结构化文本的用户提示,我们可以获得想要的转换后的图谱结构。

提示如下
Translate the following user text to an RDF graph using the RDF, RDFS, and OWL ontologies formatted as TTL.
Use the prefix ex: with IRI <http://example.com/> for any created entities.
LLM的相应如下
@prefix ex: <http://example.com/> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix owl: <http://www.w3.org/2002/07/owl#> .
ex:PeterJones rdf:type ex:Person ;
rdf:label "Peter Jones" .
ex:BethHampton rdf:type ex:Person ;
rdf:label "Beth Hampton" .
ex:BrunelUniversity rdf:type ex:University ;
rdf:label "Brunel University" .
ex:George rdf:type ex:Person ;
rdf:label "George" .
ex:James rdf:type ex:Person ;
rdf:label "James" .
ex:Harold rdf:type ex:Person ;
rdf:label "Harold" .
ex:PeterJones ex:studiedAt ex:BrunelUniversity ;
ex:marriedTo ex:BethHampton ;
ex:hasChild ex:George, ex:James, ex:Harold .
对于gpt-3.5-turbo在创建新属性时没有问题。如果我们修改系统提示符,只使用SCHEMA.ORG
Translate the following user text to an RDF graph using the SCHEMA.ORG ontologies formatted as TTL.
Use the prefix ex: with IRI <http://example.com/> for any created entities.
也会得到相应的输出
@prefix ex: <http://example.com/> .
@prefix schema: <https://schema.org/> .
ex:PeterJones a schema:Person ;
schema:spouse ex:BethHampton ;
schema:alumniOf ex:BrunelUniversity .
ex:BethHampton a schema:Person ;
schema:spouse ex:PeterJones .
ex:BrunelUniversity a schema:EducationalOrganization .
ex:George a schema:Person .
ex:James a schema:Person .
ex:Harold a schema:Person .
ex:PeterJones schema:children ex:George, ex:James, ex:Harold .
ex:BethHampton schema:children ex:George, ex:James, ex:Harold .
这是最简单的方法,因为我们不需要做任何的操作,完全的使用LLM已经训练好的内容,并且也能得到很好的输出。提示也非常简洁(约41个token),不会占用太多的字符。
但是转换仅限于LLM预先训练过的那些“标准”本体。如果你问ChatGPT是在什么标准本体上进行训练的,他不会给你想要的答案,这样对我们来说就是一个黑盒。并且在文本到图谱的转换中生成的实体还需要在各个图谱之间进行对齐。
在LLM提示中添加本体

在大多多情况下,我们希望使用非标准或自定义本体。LLM不太可能在这样的本体上进行预训练,因此我们需要在提示中包含完整的本体。
Translate the following user text to an RDF graph using the following schema1: <http://inova8.com/schema/1/> ontologies formatted as TTL.
Use the prefix ex: with IRI <http://example.com/> for any created entities.
Only use pre-defined classes and properties from the schema1: <http://inova8.com/schema/1/> ontology.
Use the properties and classes in the schema1: ontology.
Include individuals, their data, and relationships.
... the full ontology in TTL format ...
我们需要对转换的内容进行详细的说明,这导致提示token增加到了~3567,使用与之前相同的输入提示,LLM也可以很好地转换文本:
ex:PeterJones rdf:type schema1:CC ;
:dc "Peter" ;
:de "Jones" ;
:oa ex:BrunelUniversity ;
:oh ex:BethHampton ;
:of ex:business .
ex:BethHampton rdf:type schema1:CC ;
:dc "Beth" ;
:de "Hampton" ;
:oa ex:BrunelUniversity ;
:oh ex:PeterJones ;
:of ex:business .
ex:BrunelUniversity rdf:type schema1:CA ;
rdfs:label "Brunel University" .
ex:George rdf:type schema1:CC ;
rdfs:label "George" ;
:od ex:PeterJones ;
:od ex:BethHampton .
ex:James rdf:type schema1:CC ;
rdfs:label "James" ;
:od ex:PeterJones ;
:od ex:BethHampton .
ex:Harold rdf:type schema1:CC ;
rdfs:label "Harold" ;
:od ex:PeterJones ;
:od ex:BethHampton .
ex:PeterJones :oh ex:BethHampton .
ex:BethHampton :oh ex:PeterJones .
当我们将自定义的内容包含在提示中时,LLM似乎可以理解用RDF、RDFS和OWL表示的本体,并且能够将非结构化文本转换为自定义本体。
但是这导致提示现在非常长,以为系统提示token开销很大。这将增加成本也会减慢响应时间,因为时间与要处理的token成正比。并且这个结果仍然需要对齐。
使用本体进行微调

前两种方法的主要问题是局限于预训练的本体,或者在提示中包含自定义本体时开销很大。所以我们可以对LLM进行微调使用KG对LLM进行微调是非常简单的,因为图的本质是三元组:
{:subject :predicate :object}
我们可以将其映射到提示中进行训练。下面的内容都是可以从图中自动生成的。
{“messages”: [
{"role": "system", "content": "Complete the following graph edge"},
{"role": "user", "content": "What is <:subject> <predicate>?"},
{"role": "assistant", "content": " <:subject> is <:predicate> <:object>."}]
}
…
这个问题就变成了训练LLM将一种语言(非结构化英语文本)翻译成另一种语言(使用微调本体语义的高度结构化rdf图)。
messages”: [
{"role": "system", "content": "Translate the following user text to an RDF graph using the Schema1 ontology."},
{"role": "user", "content": "{example unstructured text}"},
{"role": "assistant", "content": "{RDF graph using custom Schema1 ontology semantics}"}]
}
…
所以问题就变成了创建一个具有代表性的微调训练集(100~200个)和RDF转换集。但是如何设计提示呢?我们来直接问问LLM,因为她最了解自己,哈。
I want to fine-tune an LLM on this Schema1 ontology.
This training aims to take an example user text and the assistant translates it into an RDF graph based on the Schema1 ontology.
Please create a comprehensive set of 50 example system, user, and assistant messages in JSONL message conversational chat format format for fine-tuning an LLM to translate text to Schema1 ontology RDF.
The system content should be the instruction to translate the user text to the assistant RDF graph response using Sxchema1 ontology.
The user text should be examples that cover all the concepts within the Schema1 ontology.
The assistant content should be an RDF graph using the Schema1 ontology of the translation of the user text examples.
Use the prefix ex: with IRI <http://example.com/> for any created entities.
Use the message format as follows:
{"messages": [
{"role": "system", "content": "<system_content>"},
{"role": "user", "content": "<user_content>},
{"role": "assistant", "content": "<assistant_content>"}
]}
gpt-3.5-turbo以正确的格式做出了回应。
{“messages”: [
{“role”: “system”, “content”: “
Translate the following user text to an RDF graph using the Schema1 ontology.”},
{“role”: “user”, “content”: “
John Smith is a professor who graduated from a reputed college.”},
{“role”: “assistant”, “content”: “
@prefix ex: <http://example.com/> .
@prefix schema1: <http://inova8.com/schema/1/> .
ex:JohnSmith rdf:type schema1:CC ;
schema1:dc \”John\” ;
schema1:de \”Smith\” ;
schema1:of schema1:professor ;
schema1:oa ex:ReputedCollege .
ex:ReputedCollege rdf:type schema1:CA .”}]}
… and so on
我们来试试效果,使用它生成了一个适当大小的(160)转换调优数据集。使用3和10个epoch对LLM进行了微调。
System-prompt (34 tokens):
Translate the following user text to an RDF graph using the Schema1 ontology.
Use the prefix ex: with IRI <http://example.com/> for any created entities.
User-prompt (28 tokens):
Peter Jones and Beth Hampton both studied at Brunel University, then got married, and have three children: George, James, and Harold.
LLM的结果
@prefix ex: <http://example.com/> .
ex:PeterJones a schema1:CC ;
schema1:dc "Peter" ;
schema1:de "Jones" ;
schema1:of schema1:student .
ex:BethHampton a schema1:CC ;
schema1:dc "Beth" ;
schema1:de "Hampton" ;
schema1:of schema1:student .
ex:JonesHamptonMarriage a schema1:CG ;
schema1:og ex:PeterJones ;
schema1:oh ex:BethHampton .
ex:GeorgeJones a schema1:CD ;
schema1:dc "George" ;
schema1:od ex:PeterJones ;
schema1:of ex:BethHampton .
ex:JamesJones a schema1:CD ;
schema1:dc "James" ;
schema1:od ex:PeterJones ;
schema1:of ex:BethHampton .
ex:HaroldJones a schema1:CD ;
schema1:dc "Harold" ;
schema1:od ex:PeterJones ;
schema1:of ex:BethHampton .
可以看到,工作的还不错,LLM自己给自己上了一课,我们只是动动嘴(手)。另外在质量上3 epoch和10 epoch微调的LLM之间的转换质量似乎没有什么差别。
LLM可以使用自定义本体进行微调,调优LLM的提示可以非常简洁(约41个token),因此大部分token成本由要转换的非结构化文本组成。
但是微调需要度量llm理解自定义本体的准确性和图谱转换的准确性的指标,如何判断好坏就是一个需要仔细研究的问题,我们生成的图谱仍然需要对齐。
改进微调的提示
通常情况下,单个本体/模式不足以捕获文本的完整语义,所以需要使用两个或更多本体。这里的一个好消息是经过微调,LLM并没有忘记预训练的本体,所以我们可以将它们结合使用。
Translate the following user text to an RDF graph using both the FOAF, and Schema1 ontologies.
Use the prefix ex: with IRI <http://example.com/> for any created entities.
Peter Jones and Beth Hampton both studied at Brunel University, then got married, and have three children: George, James, and Harold.
Peter, email address peter.jones@inova8.com, has been friends with Paul Williams because of their shared interest in ornithology.
结果如下:
@prefix ex: <http://example.com/> .
ex:PeterJones a schema1:Thing, foaf:Person ;
schema1:email "peter.jones@inova8.com" ;
foaf:name "Peter Jones" ;
foaf:interest ex:Ornithology .
ex:BethHampton a schema1:Thing, foaf:Person ;
foaf:name "Beth Hampton" .
ex:GeorgeJones a schema1:Thing, foaf:Person ;
foaf:name "George Jones" ;
foaf:maker ex:PeterJones .
ex:JamesJones a schema1:Thing, foaf:Person ;
foaf:name "James Jones" ;
foaf:maker ex:PeterJones .
ex:HaroldJones a schema1:Thing, foaf:Person ;
foaf:name "Harold Jones" ;
foaf:maker ex:PeterJones .
ex:BrunelUniversity a schema1:Thing, foaf:Document ;
foaf:name "Brunel University" .
ex:JonesHamptonMarriage a schema1:Thing ;
schema1:spouse ex:PeterJones, ex:BethHampton .
ex:JonesHamptonFamily a schema1:Thing ;
schema1:parent ex:PeterJones, ex:BethHampton ;
schema1:child ex:GeorgeJones, ex:JamesJones, ex:HaroldJones .
ex:PeterJones foaf:knows ex:PaulWilliams .
ex:PaulWilliams a schema1:Thing, foaf:Person ;
foaf:name "Paul Williams" .
可以看到,回复中不仅包含了我们微调的结果,还包含了模型预训练时返回的结果
但是这里有一个问题,当同一概念在本体之间重叠时,我们需要控制LLM返回使用哪个。
总结
对于上面几种方法的对比,我们总结了一个图表:

llm可以有效地将非结构化文本转换为RDF图。自定义本体微调模型的token效率要高得多,因为它不需要在每个转换请求提示符中提供完整本体的开销,当需要转换多个文本时,这可以降低生产环境中的转换成本。
但是我们还没有提到如何建立文本到KG转换的“准确性”测试,并且转换后如何进行实体对齐,我们将在后面的文章中继续介绍。
https://avoid.overfit.cn/post/486b8b13131641509d0ae4a6ade4156d文章来源:https://www.toymoban.com/news/detail-809095.html
作者:Peter Lawrence文章来源地址https://www.toymoban.com/news/detail-809095.html
到了这里,关于4种通过LLM进行文本知识图谱的构建方法对比介绍的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!