🤣 爆笑教程 👉 《看表情包学Linux》👈 猛戳订阅 🔥
🤣 爆笑教程 👉 《看表情包学Linux》👈 猛戳订阅 🔥

💭 写在前面:本章核心主题为 "进程地址空间",会通过验证 Linux 进程的地址空间来开头,抛出 "同一个值能有不同内容" 的现象,通过该现象去推导出 "虚拟地址" 的概念。然后带着大家理解为什么虚拟地址不能是物理内存、讲解进程地址空间的概念以及如何设计。讲解什么是区域,对区域的理解,再引出内核中的数据结构是如何维护的,如何加载的问题。最后我们会揭秘文章开头的验证抛出的问题,从而引出 "写时拷贝" 的概念。讲解完写时拷贝后,我们就能理解为什么 "同一个值能有不同内容"的现象,并且也能解释本专栏进程开篇时抛出的 "fork为什么会有两个返回值" 的问题了。文章的最后我们再探讨一下虚拟地址空间存在的意义,会印证 "进程本身是有独立性的" 概念。
 本篇博客全站热榜排名:14
本篇博客全站热榜排名:14
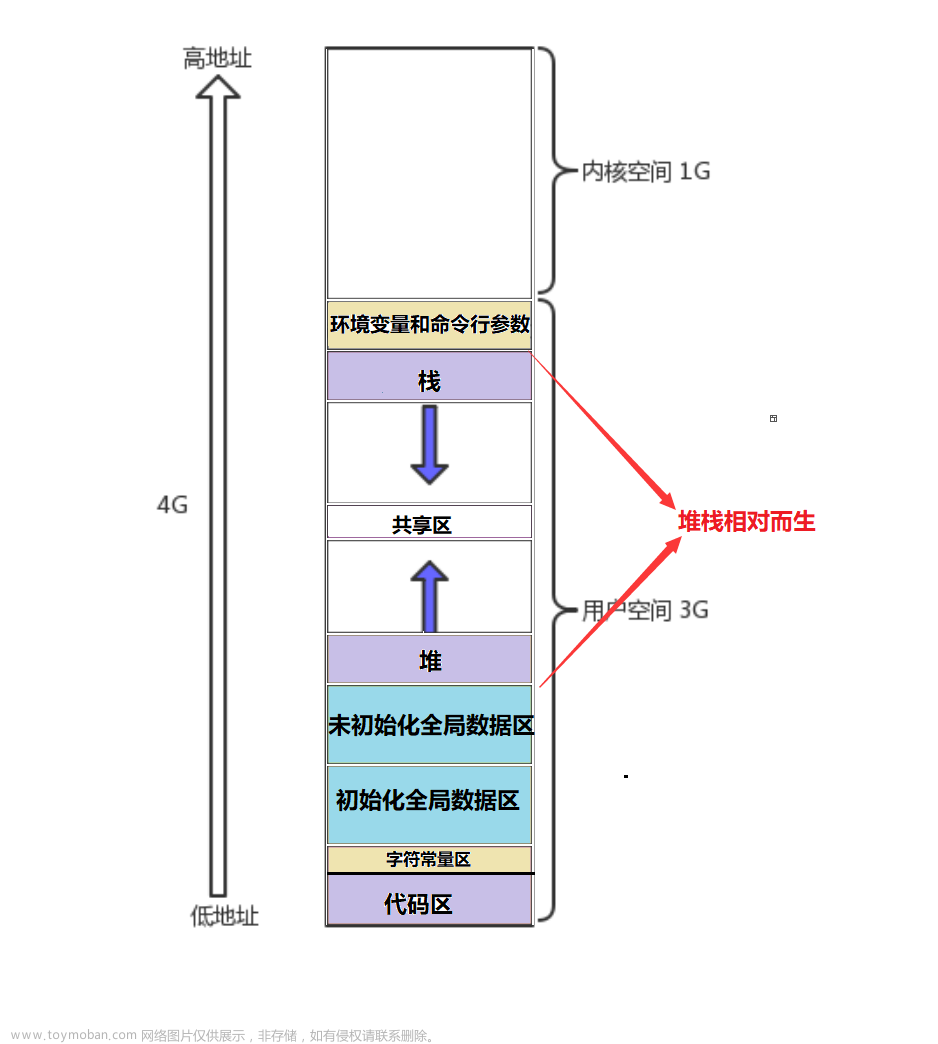
0x00 引入:地址空间是内存吗?非也!

 程序地址空间是内存吗?不是!程序地址空间不是内存!
程序地址空间是内存吗?不是!程序地址空间不是内存!
其实,我们称之为程序地址空间都不准确,应该叫 进程地址空间,这是一个系统级的概念!
0x01 验证:Linux 进程地址空间
 我们来写个代码验证一下 Linux 进程地址空间!
我们来写个代码验证一下 Linux 进程地址空间!

💬 代码:Linux 进程地址空间
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int un_g_val;
int g_val = 100;
int main(int argc, char* argv[], char* env[])
{
printf("code addr : %p\n", main);
printf("init global addr : %p\n", &g_val);
printf("uninit global addr : %p\n", &un_g_val);
char* m1 = (char*)malloc(100);
printf("heap addr : %p\n", m1);
printf("stack addr : %p\n", &m1);
int i = 0;
for (i = 0; i < argc; i++) {
printf("argv addr : %p\n", argv[i]);
}
for (i = 0; env[i]; i++) {
printf("env addr : %p\n", env[i]);
}
}
🚩 运行结果如下:

我们发现,整体的地址是依次增大的。
 请注意,堆和栈之间能观察到有非常大的地址镂空。
请注意,堆和栈之间能观察到有非常大的地址镂空。
下面我们来验证一下堆和栈的 "挤压式" 增长方向的问题,在刚才的代码中我们加上如下代码:
/* 堆上申请四块空间 */
char* m1 = (char*)malloc(100);
char* m2 = (char*)malloc(100);
char* m3 = (char*)malloc(100);
char* m4 = (char*)malloc(100);
printf("heap addr : %p\n", m1);
printf("heap addr : %p\n", m2);
printf("heap addr : %p\n", m3);
printf("heap addr : %p\n", m4);现在我们再验证一下栈区, 依次入栈,我们取地址将其分别打印出来:
printf("stack addr : %p\n", &m1);
printf("stack addr : %p\n", &m2);
printf("stack addr : %p\n", &m3);
printf("stack addr : %p\n", &m4);
 我们发现,堆区向地址增大方向增长,栈区向地址减少方向增长。
我们发现,堆区向地址增大方向增长,栈区向地址减少方向增长。
"堆和栈相对而生"
我们一般在 C 函数中定义的变量,通常在栈上保存,那么先定义的一定是地址比较高的,
后定义的地址一定是比较低的。因为先定义的先入栈,后定义的后入栈。
 我们再来理解一下 static 变量,如何理解 static 变量?
我们再来理解一下 static 变量,如何理解 static 变量?
我们知道:一个变量在函数内被定义,如果声明其为 static,那么它的作用域不变,但它的生命周期会随着程序存在一直存在。
凭什么在函数内定义 static 变量,该变量就能寿与天齐了?

我们可以加入一个 static 变量进刚才的代码中,我们来观察观察:
static int s = 100;
我们的 s 是被初始化的,所以就被当成了全局变量,它只是一个写在函数内的全局变量。
 这也就是为什么它能够寿与天齐,因为它本来就是全局变量。
这也就是为什么它能够寿与天齐,因为它本来就是全局变量。
🔺 结论:函数内定义的变量用 static 修饰,本质是编译器会把该变量编译进全局数据区。
0x02 感知:地址空间的存在
💬 我们还是写代码去观察分析:
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int g_val = 100;
int main(void)
{
pid_t id = fork();
if (id == 0) {
// child
while (1) {
printf("我是子进程: %d, ppid: %d, g_val: %d, &g_val: %p\n\n", getpid(), getppid(), g_val, &g_val);
sleep(1);
}
}
else {
// father
while (1) {
printf("我是父进程: %d, ppid: %d, g_val: %d, &g_val: %p\n\n", getpid(), getppid(), g_val, &g_val);
sleep(2);
}
}
}🚩 运行结果如下:

结论:当父子进程没有人修改全局数据的时候,父子是共享该数据的。
 如果此时尝试写入,比如我们让子进程有一个修改的操作。
如果此时尝试写入,比如我们让子进程有一个修改的操作。
我们在子进程那定义一个 flag, sleep(1) 执行五次,即五秒之后给它改值:
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int g_val = 100;
int main(void)
{
pid_t id = fork();
if (id == 0) {
// child
int flag = 0;
while (1) {
printf("我是子进程: %d, ppid: %d, g_val: %d, &g_val: %p\n\n", getpid(), getppid(), g_val, &g_val);
sleep(1);
flag++;
// 五秒之后开始更改
if (flag == 5) {
g_val = 200;
printf("我是子进程,全局数据我已做修改,注意查看!\n");
}
}
}
else {
// father
while (1) {
printf("我是父进程: %d, ppid: %d, g_val: %d, &g_val: %p\n\n", getpid(), getppid(), g_val, &g_val);
sleep(2);
}
}
}🚩 运行结果如下:

💡 发现:父子进程读取同一个变量(因为地址一样),但是后续没有人修改的情况下,父子进程读取到的内容却不一样。
 父子进程打出来的地址是一样的,值却不一样!?
父子进程打出来的地址是一样的,值却不一样!?
" 妈妈生的(即答)"
既然如此,那我就告诉你真相 —— 我们在 C/C++ 中使用的地址,绝对不是物理地址!
(梅开二度) 震惊,居然不是物理地址……
听到这就像是《三体》中所说的 "物理学从来就没有存在过" 一样。
 如果是物理地址,上面出现的那种现象是不可能产生的!
如果是物理地址,上面出现的那种现象是不可能产生的!
不是物理地址,那是什么呢?本章我们还不能证明,需要后续章节的铺垫才能够讲解。
 我们先抛出概念:我们在 C/C++ 中使用的地址,是 虚拟地址。
我们先抛出概念:我们在 C/C++ 中使用的地址,是 虚拟地址。
虚拟地址在我们 Linux 下也称为 线性地址,有些教材中也称之为 逻辑地址。这三个概念实际上是不一样的,但是在 Linux 下它是一样的(这和其本身的空间布局有关系)。
 我们再抛出一个问题:为什么我的操作系统不让我直接看到物理内存呢?
我们再抛出一个问题:为什么我的操作系统不让我直接看到物理内存呢?
如果能让你直接看到物理内存,或者让你访问物理内存,岂不是会出乱子。
内存就是一个硬件,不能阻拦你访问!只能被动地进行读取和写入!
0x03 讲解:进程地址空间
每一个进程在启动的时侯都会让操作系统给它创建一个地址空间,该地址空间就是 进程地址空间
操作系统为了管理一个进程,给该进程维护一个 task_struct 叫做进程控制块。

首先,每一个进程都会有一个自己的进程地址空间。
操作系统要不要管理这些进程地址空间呢?当然是要管理了,我们还是引出前几章提出的:
先描述,再组织。
所谓的进程地址空间,其实是内核的一个数据结构!叫做 mm_struct 。
 下面我们就来讲解,究竟什么是地址空间!
下面我们就来讲解,究竟什么是地址空间!
在上一章,我们谈论过进程的概念,竞争和独立、并行和并发,我们要需要谈论其中的 独立性。
进程具备独立性,简单来说就是一个进程挂掉或崩溃是不会波及其他进程的。
- 进程相关的数据结构是独立的,进程的代码和数据是独立的。
 说得好,但是独立性又和地址空间有什么关系呢?我们来讲个故事。
说得好,但是独立性又和地址空间有什么关系呢?我们来讲个故事。
💭 小故事环节:
《重生之我是财阀老板私生子》
韩国某个财阀老板非常滴有钱,他有 3 个私生子,每个私生子都并不知道对方的存在,他们都以为自己是独生子。因为他们彼此不知道对方的存在,所以他们在生活和工作上也没有交集,不会有任何互相的影响(这就是独立性的体现)。财阀老板为了维护自己的独立性:
他就对大儿子说:"儿子,你好好学习,以后老爹钱都是你的。",大儿子一听卧槽真好,高枕无忧,就好好学习,一想到自己以后有钱,就更想学习了。
然后又对二儿子说:"儿子,好好工作,等以后我就把公司给你。",二儿子一听热泪盈眶,于是就好好工作,等着将来有一天可以继承公司。
后来又对三儿子说:"儿子,你好好干活,等你长大老爹的家产交给你!",三儿子知道自己以后会继承老爹的所有财产,开心坏了,就努力的干活。
只要在财阀爹的可承受范围内,孩子要多少钱他都给多少钱,所以三个儿子自然都认为自己有很多钱。财阀老板给他的三个儿子画了一张虚拟的、不存在的大饼,让他们都能努力学习工作干活(这个步骤就是给他们分别建立了进程地址空间)。
上面的故事中,财阀老板就是操作系统,三个私生子就是进程,
 财阀老板给他的三个儿子画的大饼,我们就称之为 "进程地址空间"。
财阀老板给他的三个儿子画的大饼,我们就称之为 "进程地址空间"。
所以,进程地址空间并不是物理上存在的概念,而是在逻辑上抽象的一个虚拟的空间。
财阀老板给三个私生子画饼,就是为了维护这三个私生子互相之间的独立性,
如果让私生子知道自己并不是唯一,那以后分割财产必然会造成矛盾,
 对他来说自然就不是一件好事。
对他来说自然就不是一件好事。
所以,进程地址空间,就是就是给进程画的大饼。
进程地址空间 → 逻辑上抽象的概念 → 让每个进程都认为自己独占系统的所有资源
📚 概念:操作系统通过软件的方式,给进程提供一个软件视角,认为自己是独占系统的所有资源(内存)。

0x04 理解:区域和页表
什么叫做区域?我们来拿一张桌子来理解,初中的时候我和我的同桌分过 "38线" 。

我们把一张桌子分为两个区域,对桌子进行区域划分:

比如,既然要标出区域,定义一个桌面区域,其实用两个变量就可以表示了:
struct destop_area {
int start; // 区域起始位置
int end; // 区域结束位置
};
struct destop_area A = {1,50};
struct destop_area B = {50, 100};

抢地盘对桌面区域进行划分,调整区域的大小只需要让 end 加上 "调整值" 就行。
这就是区域的概念,我们只需要定义 start 和 end 就可以表示了。
每个区域范围都是可以有对应的编号的,比如以厘米为单位,我的修正带就放在了 50cm。
我们的 mm_struct 里面不就是区域范围吗?所以 mm_struct 就可以靠 start 和 end 定义:
struct mm_struct {
long code_start;
long code_end;
long init_start;
long init_end;
long uninit_start;
long uninit_end;
long heap_start;
long heap_end;
long stack_start;
long stack_end;
...
}程序加载到内存,由程序变成进程后,由操作系统给每个进程构建的一个页表结构,就是 页表。
 我们来看看内核代码,就是用一个 start 一个 end 来呈现区域空间。
我们来看看内核代码,就是用一个 start 一个 end 来呈现区域空间。

每个区域都有一个 start 和 end,它们之间就有了地址,地址我们称之为虚拟地址,
 然后这些虚拟地址经过页表,就能映射到内存中了。
然后这些虚拟地址经过页表,就能映射到内存中了。

0x05 揭秘:原来是写时拷贝!
❓ 思考:程序是如何变成进程的?
程序被编译出来,没有被加载的时候,程序内部有地址吗?有!
 有没有区域?也有!
有没有区域?也有!
🔍 区分:我们程序内部的地址和内存的地址是没有关系的。
编译程序的时候,我们就认为程序是按照 ~ 进行编址的。
虚拟地址空间,不仅仅是操作系统会考虑,编译器也会考虑。
每个进程都会创建一个 task_struct,每一个进程都会维护一个 mm_struct,自己有对应的区域,当我们的程序加载到内存时,程序有自己的加载到物理内存的物理地址,虚拟地址和物理地址建立映射关系,进程访问某个区域当中的地址时,经过页表找到对应的代码和数据。当找到代码和数据后,代码加入到对应的 CPU 中,代码中的地址在加载中就已经转化成了线性地址/虚拟地址,所以 CPU 可以继续照着这个逻辑向后运行。
所以刚才我们代码测试,打印看到的虚拟地址值是一样的,并且内容也是一样的。在没有人写入的时候,虚拟地址到物理地址之间映射的页表是一样的,所以指向的代码和数据都是一样的。
因为进程具有独立性,比如如果此时子进程把变量改了(写入),就会导致父进程识别的问题就出现了父进程和子进程不一的情况,因为进程是具有独立性的,所以我们就要做到互不影响。我们的子进程要进行修改了,影响到父进程怎么办?没关系!操作系统会出手!当我们识别到子进程要修改时,操作系统会重新给子进程开辟一段空间,并且把 100 拷贝下来,重新给进程建立映射关系,所以子进程的页表就不再指向父进程所对应的 100 了,而直接指向新的 100。你在做修改时又把它的值从 100 改成 200 时,我们就出现了 "改的时候永远改的是页表的右侧,左侧不变" 的情况,所以最后你看到了父子进程的虚拟地址一样,但是经过页表映射到了不同的物理内存,所以了你看到了一个是 100 一个是 200,父子进程的数据不同的结果。
我们的操作系统当我们的父子对数据进行修改时,操作系统会给修改的一方重新开辟一块空间,并且把原始数据拷贝到新空间当中,这种行为就是 写时拷贝!
当父子有任何一个进程尝试修改对应变量时,有一个人想修改,就会触发写时拷贝,让他去拷贝新的物理内存,这只需要重新构建也表的映射关系,虚拟地址是不发生任何变化的,所以最终你看的结果是虚拟地址不变,而内容不同。
 现在再看,一点都不神奇了。
现在再看,一点都不神奇了。
通过页表,将父子进程的数据就可以通过写时拷贝的方式,进行了分离。
这就做到父子进程具有独立性,父子进程不互相影响。
0x06 回顾:fork 有两个返回值的问题
我们在讲解进程的第一个章节就提出过一个问题,关于 fork 为什么有两个返回值的问题。
当时我们还提出了两个问题,局限于当时还没有讲到进程地址空间,所以没有办法深入讲解。

 我们当时说过要在 "进程地址空间" 讲完后再讲,现在就可以讲了!
我们当时说过要在 "进程地址空间" 讲完后再讲,现在就可以讲了!
我们先回顾一下上下文:

💬 代码:验证 fork 返回值的问题,我们把 id 给打印出来:
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
int main(void) {
pid_t id = fork();
printf("Hello, World! id: %d\n", id);
sleep(1);
}
 fork 有两个返回值,
fork 有两个返回值,pid_t id,同一个变量为什么会有两个返回值?
本章我们就可以理解了,因为当它 return 的时候,pid_t id 是属于父进程的栈空间中定义的。
fork 内部 return 会被执行两次,return 的本质就是通过寄存器将返回值写入到接收返回值的变量中。当我们的 id = fork() 时,谁先返回,谁就要发生 写时拷贝。所以,同一个变量会有不同的返回值,本质是因为大家的虚拟地址是一样的,但大家的物理地址是不一样的。
0x07 探讨:为什么要有虚拟地址空间?
 如果我们没有虚拟地址空间,直接让进程访问物理内存是不安全的。
如果我们没有虚拟地址空间,直接让进程访问物理内存是不安全的。
有了虚拟地址空间,就是给访问内存添加了一层软硬关键层,可以对转化过程进行审核,非法的访问就可以被直接拦截了,可以 保护内存。
还能够将 进程管理 和 Linux 内存管理,通过地址空间进行功能模块的解耦。
让进程或者程序可以以一种统一的视角看待内存!
有了虚拟地址空间,还可以让进程或者程序可以 以统一的视角看待内存。方便以统一的方式来编译和加载所有的可执行程序。如此一来,就可以简化进程本身的设计和实现。

📌 [ 笔者 ] 王亦优
📃 [ 更新 ] 2023.2.14
❌ [ 勘误 ] /* 暂无 */
📜 [ 声明 ] 由于作者水平有限,本文有错误和不准确之处在所难免,
本人也很想知道这些错误,恳望读者批评指正!| 📜 参考资料 C++reference[EB/OL]. []. http://www.cplusplus.com/reference/. Microsoft. MSDN(Microsoft Developer Network)[EB/OL]. []. . 百度百科[EB/OL]. []. https://baike.baidu.com/.文章来源:https://www.toymoban.com/news/detail-809163.html 比特科技. Linux[EB/OL]. 2021[2021.8.31 xiw文章来源地址https://www.toymoban.com/news/detail-809163.html |
到了这里,关于【看表情包学Linux】进程地址空间 | 区域和页表 | 虚拟地址空间 | 初识写时拷贝的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!