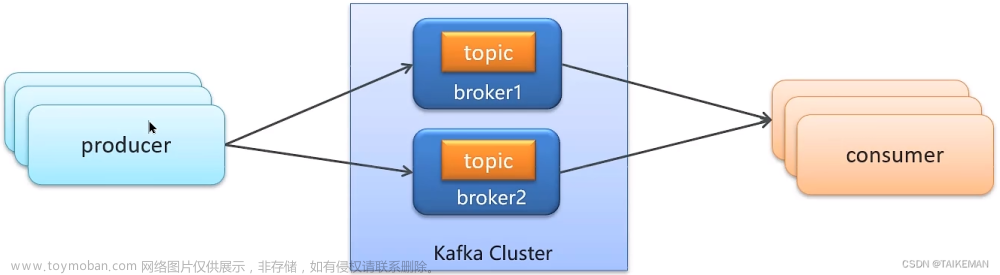
一、概念介绍
Apache Kafka是一个分布式流处理平台,用于构建实时数据管道和流应用。它可以处理网站、应用或其他来源产生的大量数据流,并能实时地将这些数据流传输到另一个系统或应用中进行处理。
核心概念:
-
Topic(主题):消息的分类,用于区分不同的业务消息。
-
Producer(生产者):消息的发送者,负责向Kafka发送消息。
-
Consumer(消费者):消息的接收者,负责从Kafka订阅并拉取消息。
-
Broker(代理):Kafka服务实例,负责消息的存储和转发。
-
Partition(分区):物理上的概念,每个Topic包含一个或多个Partition,用于实现负载均衡和扩展性。
-
Offset(偏移量):消息在Partition中的唯一标识,用于Consumer定位消息。
-
Zookeeper:Kafka的协调服务,用于管理集群配置、Broker状态等。
二、安装部署
-
环境准备:
-
安装Java环境(JDK 8 或更高版本)。
-
下载Kafka安装包。
-
准备Zookeeper集群(如果使用Kafka自带的Zookeeper,则可以跳过此步骤)。
-
-
安装步骤:
-
解压Kafka安装包到指定目录。
-
配置Kafka的环境变量(可选)。
-
修改Kafka配置文件(
config/server.properties),设置Broker ID、Zookeeper连接地址等。 -
启动Kafka服务(
bin/kafka-server-start.sh config/server.properties)。
-
三、基本使用
-
创建Topic:
-
使用命令行工具创建Topic(
bin/kafka-topics.sh --create --zookeeper <ZOOKEEPER_CONNECT> --replication-factor <RF> --partitions <NUM_PARTITIONS> --topic <TOPIC_NAME>)。 -
或者通过Kafka的管理API进行创建。
-
-
发送消息:
-
使用命令行工具发送消息(
bin/kafka-console-producer.sh --broker-list <BROKER_LIST> --topic <TOPIC_NAME>)。 -
或者编写Producer程序,使用Kafka的Producer API发送消息。
-
-
消费消息:
-
使用命令行工具消费消息(
bin/kafka-console-consumer.sh --bootstrap-server <BOOTSTRAP_SERVER> --topic <TOPIC_NAME> --from-beginning)。 -
或者编写Consumer程序,使用Kafka的Consumer API订阅并消费消息。
-
四、常用命令
-
查看Topic列表:
bin/kafka-topics.sh --list --zookeeper <ZOOKEEPER_CONNECT> -
查看Topic详情:
bin/kafka-topics.sh --describe --zookeeper <ZOOKEEPER_CONNECT> --topic <TOPIC_NAME> -
删除Topic:
bin/kafka-topics.sh --delete --zookeeper <ZOOKEEPER_CONNECT> --topic <TOPIC_NAME> -
修改Topic分区数:
Kafka不直接支持修改分区数,但可以通过创建新Topic并迁移数据的方式实现。
-
查看Consumer Group:
bin/kafka-consumer-groups.sh --bootstrap-server <BOOTSTRAP_SERVER> --list -
查看Consumer Group详情:
bin/kafka-consumer-groups.sh --bootstrap-server <BOOTSTRAP_SERVER> --describe --group <GROUP_ID> -
重置Consumer Group Offset:
bin/kafka-consumer-groups.sh --bootstrap-server <BOOTSTRAP_SERVER> --reset-offsets --to-earliest --group <GROUP_ID> --topic <TOPIC_NAME>
五、应用场景
-
日志处理与分析:
Kafka非常适合处理大量的日志文件,如Web服务器日志、数据库日志和操作系统日志等。这些日志可以被快速地发布和订阅,并通过各种工具(如ElasticSearch、Logstash、Kibana等)进行聚合和分析。
-
实时数据处理:
Kafka能够处理实时事件,如实时交易、实时搜索结果和实时社交媒体更新等。由于其快速的数据发布和订阅能力,使得实时处理成为可能。
-
传感器数据处理:
在物联网(IoT)环境中,Kafka可以处理来自各种传感器(如温度、湿度、气压传感器等)的数据,并将这些数据快速地发布和订阅到分布式处理系统中。
-
流处理:
Kafka为流处理提供了多种消息传输模式,如点对点模式、多主节点模式和发布/订阅模式等。这使得Kafka可以与各种流处理框架(如Apache Storm、Apache Flink等)集成,进行复杂的数据流处理。
-
系统监控与报警:
类似于日志分析系统,Kafka可以收集各种系统指标,并通过实时监控仪表板和警报系统使用这些指标数据进行系统监控和故障排除。
-
消息传递:
Kafka作为一种可靠且可扩展的消息队列,可以在微服务之间解耦通信。您可以向Kafka发布消息,而其他服务可以订阅这些消息,从而实现服务间的异步通信。
-
数据备份与恢复:
Kafka的持久化特性使其可以用作数据备份和恢复的工具。在发生故障时,可以从Kafka中重新读取数据进行恢复。
-
事件溯源:
在这种场景中,Kafka作为主要事件存储,用于捕获一系列事件中状态的变化。如果发生任何故障、回滚或需要重建状态,可以随时从Kafka中重新应用事件。
六、常见问题及解决方案
-
Broker无法启动:
-
检查Java环境是否安装正确。
-
检查Kafka配置文件中的Broker ID是否冲突。
-
检查Zookeeper服务是否正常。
-
-
消息发送失败:
-
检查Producer的配置是否正确。
-
检查Broker是否可达。
-
检查Topic是否存在且可用。
-
-
消息消费不到:
-
检查Consumer的配置是否正确。
-
检查Consumer是否订阅了正确的Topic。
-
检查Consumer Group的Offset是否正常。
-
-
Zookeeper连接问题:
-
检查Zookeeper服务是否正常。
-
检查Kafka配置文件中的Zookeeper连接地址是否正确。
-
检查网络连通性。
-
-
集群扩展问题:
-
添加新的Broker节点到集群中,并更新Broker的配置文件。
-
使用Kafka的Rebalance工具进行分区重新分配。
-
六、注意事项
-
Kafka集群的Broker数量应为奇数,以确保Zookeeper的Leader选举正常进行。
-
在生产环境中,建议使用独立的Zookeeper集群来管理Kafka。
-
Kafka的Topic分区数应根据业务需求和数据量进行合理规划。
-
在使用Kafka时,应注意消息的顺序性和一致性要求,并根据需要选择合适的Producer和Consumer API。文章来源:https://www.toymoban.com/news/detail-809239.html
-
定期对Kafka集群进行监控和维护,确保服务的稳定性和可用性。文章来源地址https://www.toymoban.com/news/detail-809239.html
到了这里,关于【中间件】消息中间件之Kafka的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!