我们会在 GitHub 上持续更新这个教程: https://github.com/phodal/build-ai-coding-assistant,欢迎在 GitHub 上讨论。
2023 年,生成式 AI 的火爆,让越来越多的组织开始引入 AI 辅助编码。与在 2021 年发布的 GitHub Copilot 稍有差异的是,代码补全只是重多场景中的一个。大量的企业内部在探索结合需求生成完整代码、代码审查等场景,也引入生成式 AI,来提升开发效率。
在这个背景下,我们(Thoughtworks)也开发了一系列的开源工具,以帮助更多的组织构建自己的 AI 辅助编码助手:
AutoDev,基于 JetBrains 平台的全流程 AI 辅助编码工具。
Unit Eval,代码补全场景下的高质量数据集构建与生成工具。
Unit Minions,在需求生成、测试生成等测试场景下,基于数据蒸馏的数据集构建工具。
由于,我们设计 AutoDev 时,各类开源模型也在不断演进。在这个背景下,它的步骤是:
构建 IDE 插件与度量体系设计。基于公开模型 API,编写和丰富 IDE 插件功能。
模型评估体系与微调试验。
围绕意图的数据工程与模型演进。
也因此,这个教程也是围绕于这三个步骤展开的。除此,基于我们的经验,本教程的示例技术栈:
插件:Intellij IDEA。AutoDev 是基于 Intellij IDEA 构建的,并且自带静态代码分析能力,所以基于它作为示例。我们也提供了 VSCode 插件的参考架构,你可以在这个基础上进行开发。
模型:DeepSeek Coder 6.7b。基于 Llama 2 架构,与 Llama 生态兼容
微调:Deepspeed + 官方脚本 + Unit Eval。
GPU:RTX 4090x2 + OpenBayes。(PS: 用我的专用邀请链接,注册 OpenBayes,双方各获得 60 分钟 RTX 4090 使用时长,支持累积,永久有效:https://openbayes.com/console/signup?r=phodal_uVxU )
由于,我们在 AI 方面的经验相对比较有限,难免会有一些错误,所以,我们也希望能够与更多的开发者一起,来构建这个开源项目。
功能设计:定义你的 AI 助手
结合 JetBrains 2023《开发者生态系统》报告的人工智能部分 ,我们可以总结出一些通用的场景,这些场景反映了在开发过程中生成式 AI 可以发挥作用的领域。以下是一些主要的场景:
代码自动补全:在日常编码中,生成式 AI 可以通过分析上下文和学习代码模式,提供智能的代码自动补全建议,从而提高开发效率。
解释代码:生成式 AI 能够解释代码,帮助开发者理解特定代码片段的功能和实现方式,提供更深层次的代码理解支持。
生成代码:通过学习大量的代码库和模式,生成式 AI 可以生成符合需求的代码片段,加速开发过程,尤其在重复性工作中发挥重要作用。
代码审查:生成式 AI 能够进行代码审查,提供高质量的建议和反馈,帮助开发者改进代码质量、遵循最佳实践。
自然语言查询:开发者可以使用自然语言查询与生成式 AI 进行交互,提出问题或请求,以获取相关代码片段、文档或解释,使得开发者更轻松地获取需要的信息。
其它。诸如于重构、提交信息生成、建模、提交总结等。
而在我们构建 AutoDev 时,也发现了诸如于创建 SQL DDL、生成需求、TDD 等场景。所以。我们提供了自定义场景的能力,以让开发者可以自定义自己的 AI 能力,详细见:https://ide.unitmesh.cc/customize。
场景驱动架构设计:平衡模型速度与能力
在日常编码时,会存在几类不同场景,对于 AI 响应速度的要求也是不同的(仅作为示例):
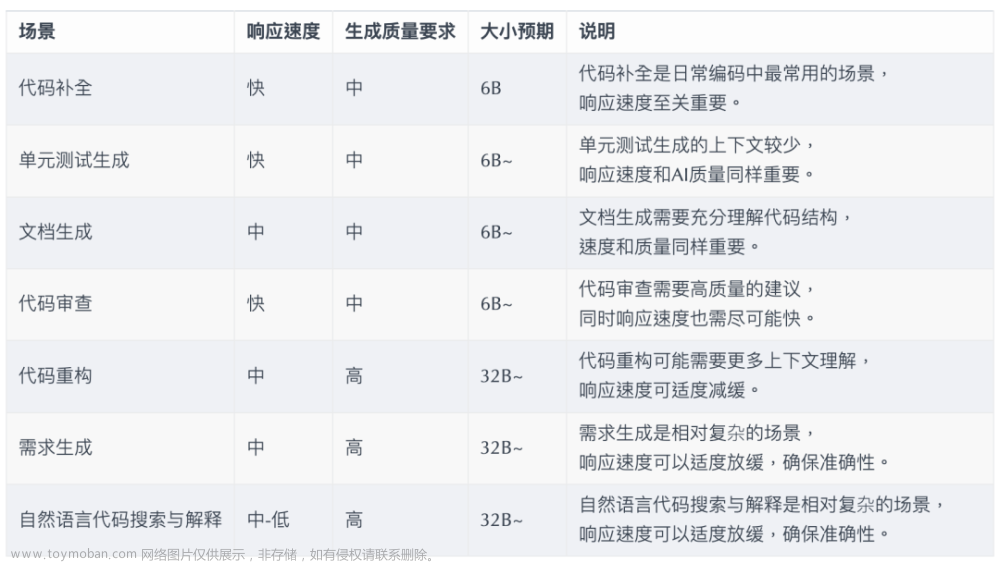
PS:这里的 32B 仅作为一个量级表示,因为在更大的模型下,效果会更好。
因此,我们将其总结为:一大一中一微三模型,提供全面 AI 辅助编码:
高质量大模型:32B~。用于代码重构、需求生成、自然语言代码搜索与解释等场景。
高响应速度中模型:6B~。用于代码补全、单元测试生成、文档生成、代码审查等场景。
向量化微模型:~100M。用于在 IDE 中进行向量化,诸如:代码相似度、代码相关度等。
重点场景介绍:补全模式
AI 代码补全能结合 IDE 工具分析代码上下文和程序语言的规则,由 AI 自动生成或建议代码片段。在类似于 GitHub Copilot 的代码补全工具中, 通常会分为三种细分模式:
行内补全(Inline)
类似于 FIM(fill in the middle)的模式,补全的内容在当前行中。诸如于: BlotPost blogpost = new,补全为: BlogPost();, 以实现: BlogPost blogpost = new BlogPost();。
我们可以 Deepseek Coder 作为例子,看在这个场景下的效果:
<|fim▁begin|>def quick_sort(arr):
if len(arr) <= 1:
return arr
pivot = arr[0]
left = []
right = []
<|fim▁hole|>
if arr[i] < pivot:
left.append(arr[i])
else:
right.append(arr[i])
return quick_sort(left) + [pivot] + quick_sort(right)<|fim▁end|>在这里,我们就需要结合光标前和光标后的代码。
块内补全(InBlock)
通过上下文学习(In-Context Learning)来实现,补全的内容在当前函数块中。诸如于,原始的代码是:
fun createBlog(blogDto: CreateBlogDto): BlogPost{
}补全的代码为:
val blogPost = BlogPost(
title = blogDto.title,
content = blogDto.content,
author = blogDto.author
)
return blogRepository.save(blogPost)块间补全(AfterBlock)
通过上下文学习(In-Context Learning)来实现,在当前函数块之后补全,如:在当前函数块之后补全一个新的函数。诸如于,原始的代码是:
fun createBlog(blogDto: CreateBlogDto): BlogPost{
//...
}补全的代码为:
fun updateBlog(id: Long, blogDto: CreateBlogDto): BlogPost{
//...
}
fun deleteBlog(id: Long) {
//...
}在我们构建对应的 AI 补全功能时,也需要考虑应用到对应的模式数据集,以提升补全的质量,提供更好的用户体验。
编写本文里的一些相关资源:
Why your AI Code Completion tool needs to Fill in the Middle
Exploring Custom LLM-Based Coding Assistance Functions
重点场景介绍:代码解释
代码解释旨在帮助开发者更有效地管理和理解大型代码库。这些助手能够回答关于代码库的问题、 提供文档、搜索代码、识别错误源头、减少代码重复等, 从而提高开发效率、降低错误率,并减轻开发者的工作负担。
在这个场景下,取决于我们预期的生成质量,通常会由一大一微或一中一微两个模型组成,更大的模型在生成的质量上结果更好。结合,我们在 Chocolate Factory 工具中的设计经验,通常这样的功能可以分为几步:
理解用户意图:借助大模型理解用户意图,将其转换为对应的 AI Agent 能力调用或者 function calling 。
转换意图搜索:借助模型将用户意图转换为对应的代码片段、文档或解释,结合传统搜索、路径搜索和向量化搜索等技术,进行搜索及排序。
输出结果:交由大模型对最后的结果进行总结,输出给用户。
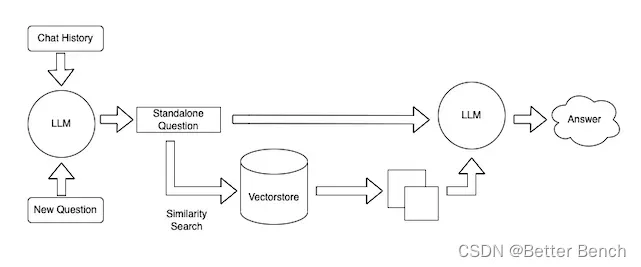
作为一个 RAG 应用,其分为 indexing 和 query 两个部分。
在 indexing 阶段,我们需要将代码库进行索引,并涉及到文本分割、向量化、数据库索引等技术。其中最有挑战的一个内容是拆分,我们参考的折分规则是:https://docs.sweep.dev/blogs/chunking-2m-files 。即:
代码的平均 Token 到字符比例约为1:5(300 个 Token),而嵌入模型的 Token 上限为 512 个。
1500 个字符大约对应于 40 行,大致相当于一个小到中等大小的函数或类。
挑战在于尽可能接近 1500 个字符,同时确保分块在语义上相似且相关上下文连接在一起。
在不同的场景下,我们也可以通过不同的方式进行折分,如在 Chocolate Factory 是通过 AST 进行折分,以保证生成上下文的质量。
在 querying 阶段,需要结合我们一些传统的搜索技术,如:向量化搜索、路径搜索等,以保证搜索的质量。同时,在中文场景下,我们也需要考虑到转换为中文 的问题,如:将英文转换为中文,以保证搜索的质量。
相关工具:https://github.com/BloopAI/bloop
-
相关资源:
Prompt 策略:代码库 AI 助手的语义化搜索设计
其它:日常辅助
对于日常辅助来说,我们也可以通过生成式 AI 来实现,如:自动创建 SQL DDL、自动创建测试用例、自动创建需求等。这些只需要通过自定义提示词, 结合特定的领域知识,便可以实现,这里不再赘述。
架构设计:上下文工程
除了模型之外,上下文也是影响 AI 辅助能力的重要因素。在我们构建 AutoDev 时,我们也发现了两种不同的上下文模式:
相关上下文:基于静态代码分析的上下文生成,可以构建更好质量的上下文,以生成更高质量的代码和测试等,依赖于 IDE 的静态代码分析能力。
相似上下文:基于相似式搜索的上下文,可以构建更多的上下文,以生成更多的代码和测试等,与平台能力无关。
简单对比如下:

在支持 IDE 有限时,相关上下文的才会带来更高的性价高。
相似上下文架构:GitHub Copilot 案例
GitHub Copilot 采用了相似上下文的架构模式,其精略的架构分层如下:
监听用户操作(IDE API )。监听用户的 Run Action、快捷键、UI 操作、输入等,以及最近的文档操作历史(20 个文件)。
IDE 胶水层(Plugin)。作为 IDE 与底层 Agent 的胶水层,处理输入和输出。
上下文构建(Agent)。JSON RPC Server,处理 IDE 的各种变化,对源码进行分析,封装为 “prompt” (疑似) 并发送给服务器。
服务端(Server)。处理 prompt 请求,并交给 LLM 服务端处理。
在 “公开” 的 Copilot-Explorer 项目的研究资料里,可以看到 Prompt 是如何构建出来的。如下是发送到的 prompt 请求:
{
"prefix": "# Path: codeviz\\app.py\n#....",
"suffix": "if __name__ == '__main__':\r\n app.run(debug=True)",
"isFimEnabled": true,
"promptElementRanges": [
{
"kind": "PathMarker",
"start": 0,
"end": 23
},
{
"kind": "SimilarFile",
"start": 23,
"end": 2219
},
{
"kind": "BeforeCursor",
"start": 2219,
"end": 3142
}
]
}其中:
用于构建 prompt 的
prefix部分,是由 promptElements 构建了,其中包含了:BeforeCursor,AfterCursor,SimilarFile,ImportedFile,LanguageMarker,PathMarker,RetrievalSnippet等类型。从几种PromptElementKind的名称,我们也可以看出其真正的含义。用于构建 prompt 的
suffix部分,则是由光标所在的部分决定的,根据 tokens 的上限(2048 )去计算还有多少位置放下。而这里的 Token 计算则是真正的 LLM 的 token 计算,在 Copilot 里是通过 Cushman002 计算的,诸如于中文的字符的 token 长度是不一样的,如:{ context: "console.log('你好,世界')", lineCount: 1, tokenLength: 30 },其中 context 中的内容的 length 为 20,但是 tokenLength 是 30,中文字符共 5 个(包含,)的长度,单个字符占的 token 就是 3。
如下是一个更详细的 Java 应用的上下文示例:
// Path: src/main/cc/unitmesh/demo/infrastructure/repositories/ProductRepository.java
// Compare this snippet from src/main/cc/unitmesh/demo/domain/product/Product.java:
// ....
// Compare this snippet from src/main/cc/unitmesh/demo/application/ProductService.java:
// ...
// @Component
// public class ProductService {
// //...
// }
//
package cc.unitmesh.demo.repositories;
// ...
@Component
publicclassProductRepository{
//...在计算上下文里,GitHub Copilot 采用的是 Jaccard 系数 (Jaccard Similarity) ,这部分的实现是在 Agent 实现,更详细的逻辑可以参考: 花了大半个月,我终于逆向分析了Github Copilot。
相关资源:
上下文工程:基于 Github Copilot 的实时能力分析与思考
相关上下文架构:AutoDev 与 JetBrains AI Assistant 案例
如上所述,相关代码依赖于静态代码分析,主要借助于代码的结构信息,如:AST、CFG、DDG 等。在不同的场景和平台之下,我们可以结合不同的静态代码分析工具, 如下是常见的一些静态代码分析工具:
TreeSitter,由 GitHub 开发的用于生成高效的自定义语法分析器的框架。
Intellij PSI (Program Structure Interface),由 JetBrains 开发的用于其 IDE 的静态代码分析接口。
LSP(Language Server Protocol),由微软开发的用于 IDE 的通用语言服务器协议。
Chapi (common hierarchical abstract parser implementation) ,由笔者(@phodal)开发的用于通用的静态代码分析工具。
在补全场景下,通过静态代码分析,我们可以得到当前的上下文,如:当前的函数、当前的类、当前的文件等。如下是一个 AutoDev 的生成单元测试的上下文示例:
// here are related classes:
// 'filePath: /Users/phodal/IdeaProjects/untitled/src/main/java/cc/unitmesh/untitled/demo/service/BlogService.java
// class BlogService {
// blogRepository
// + public BlogPost createBlog(BlogPost blogDto)
// + public BlogPost getBlogById(Long id)
// + public BlogPost updateBlog(Long id, BlogPost blogDto)
// + public void deleteBlog(Long id)
// }
// 'filePath: /Users/phodal/IdeaProjects/untitled/src/main/java/cc/unitmesh/untitled/demo/dto/CreateBlogRequest.java
// class CreateBlogRequest ...
// 'filePath: /Users/phodal/IdeaProjects/untitled/src/main/java/cc/unitmesh/untitled/demo/entity/BlogPost.java
// class BlogPost {...
@ApiOperation(value = "Create a new blog")
@PostMapping("/")
publicBlogPost createBlog(@RequestBodyCreateBlogRequest request) {在这个示例中,会分析 createBlog 函数的上下文,获取函数的输入和输出类: CreateBlogRequest、 BlogPost 信息,以及 BlogService 类信息,作为上下文(在注释中提供)提供给模型。在这时,模型会生成更准确的构造函数,以及更准确的测试用例。
由于相关上下文依赖于对不同语言的静态代码分析、不同 IDE 的 API,所以,我们也需要针对不同的语言、不同的 IDE 进行适配。在构建成本上,相对于相似上下文成本更高。
步骤 1:构建 IDE 插件与度量体系设计
IDE、编辑器作为开发者的主要工具,其设计和学习成本也相对比较高。首先,我们可以用官方提供的模板生成:
IDEA 插件模板
VSCode 插件生成
然后,再往上添加功能(是不是很简单),当然不是。以下是一些可以参考的 IDEA 插件资源:
Intellij Community 版本源码
IntelliJ SDK Docs Code Samples
Intellij Rust
当然了,更合适的是参考AutoDev 插件。
JetBrains 插件
可以直接使用官方的模板来生成对应的插件:https://github.com/JetBrains/intellij-platform-plugin-template
对于 IDEA 插件实现来说,主要是通过 Action 和 Listener 来实现的,只需要在 plugin.xml 中注册即可。详细可以参考官方文档:IntelliJ Platform Plugin SDK
版本兼容与兼容架构
由于我们前期未 AutoDev 考虑到对 IDE 版本的兼容问题,后期为了兼容旧版本的 IDE,我们需要对插件进行兼容性处理。所以,如官方文档:Build Number Ranges 中所描述,我们可以看到不同版本,对于 JDK 的要求是不一样的,如下是不同版本的要求:
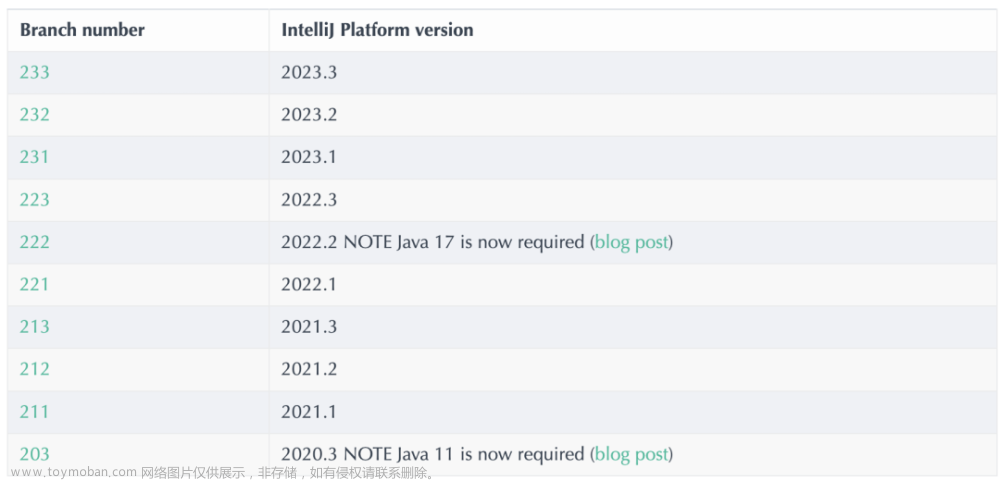
并配置到 gradle.properties 中:
pluginSinceBuild = 223
pluginUntilBuild = 233.*后续配置兼容性比较麻烦,可以参考 AutoDev 的设计。
补全模式:Inlay
在自动代码补全上,国内的厂商主要参考的是 GitHub Copilot 的实现,逻辑也不复杂。
采用快捷键方式触发
其主要是在 Action 里监听用户的输入,然后:

采用自动触发方式
其主要通过 EditorFactoryListener 监听用户的输入,然后:根据不同的输入,触发不同的补全结果。核心代码如下:
classAutoDevEditorListener: EditorFactoryListener{
override fun editorCreated(event: EditorFactoryEvent) {
//...
editor.document.addDocumentListener(AutoDevDocumentListener(editor), editorDisposable)
editor.caretModel.addCaretListener(AutoDevCaretListener(editor), editorDisposable)
//...
}
classAutoDevCaretListener(val editor: Editor) : CaretListener{
override fun caretPositionChanged(event: CaretEvent) {
//...
val wasTypeOver = TypeOverHandler.getPendingTypeOverAndReset(editor)
//...
llmInlayManager.disposeInlays(editor, InlayDisposeContext.CaretChange)
}
}
classAutoDevDocumentListener(val editor: Editor) : BulkAwareDocumentListener{
override fun documentChangedNonBulk(event: DocumentEvent) {
//...
val llmInlayManager = LLMInlayManager.getInstance()
llmInlayManager
.editorModified(editor, changeOffset)
}
}
}再根据不同的输入,触发不同的补全结果,并对结构进行处理。
渲染补全代码
随后,我们需要实现一个 Inlay Render,它继承自 EditorCustomElementRenderer。
日常辅助功能开发
结合 IDE 的接口能力,我们需要添加对应的 Action,以及对应的 Group,以及对应的 Icon。如下是一个 Action 的示例:
<add-to-group group-id="ShowIntentionsGroup" relative-to-action="ShowIntentionActions" anchor="after"/>
如下是 AutoDev 的一些 ActionGroup:

在编写 ShowIntentionsGroup 时,我们可以参考 AutoDev 的实现来构建对应的 Group:
<groupid="AutoDevIntentionsActionGroup"class="cc.unitmesh.devti.intentions.IntentionsActionGroup"
icon="cc.unitmesh.devti.AutoDevIcons.AI_COPILOT"searchable="false">
<add-to-groupgroup-id="ShowIntentionsGroup"relative-to-action="ShowIntentionActions"anchor="after"/>
</group>多语言上下文架构
由于 Intellij 的平台策略,使得运行于 Java IDE(Intellij IDEA)与在其它 IDE 如 Python IDE(Pycharm)之间的差异性变得更大。我们需要提供基于多平台产品的兼容性,详细介绍可以参考:Plugin Compatibility with IntelliJ Platform Products
首先,将插件的架构进一步模块化,即针对于不同的语言,提供不同的模块。如下是 AutoDev 的模块化架构:
java/ # Java 语言插件
src/main/java/cc/unitmesh/autodev/ # Java 语言入口
src/main/resources/META-INF/plugin.xml
plugin/ # 多平台入口
src/main/resources/META-INF/plugin.xml
src/ # 即核心模块
main/resource/META-INF/core.plugin.xml在 plugin/plugin.xml 中,我们需要添加对应的 depends,以及 extensions,如下是一个示例:
<idea-pluginpackage="cc.unitmesh"xmlns:xi="http://www.w3.org/2001/XInclude"allow-bundled-update="true">
<xi:includehref="/META-INF/core.xml"xpointer="xpointer(/idea-plugin/*)"/>
<content>
<modulename="cc.unitmesh.java"/>
<!-- 其它模块 -->
</content>
</idea-plugin>而在 java/plugin.xml 中,我们需要添加对应的 depends,以及 extensions,如下是一个示例:
<idea-pluginpackage="cc.unitmesh.java">
<!--suppress PluginXmlValidity -->
<dependencies>
<pluginid="com.intellij.modules.java"/>
<pluginid="org.jetbrains.plugins.gradle"/>
</dependencies>
</idea-plugin>随后,Intellij 会自动加载对应的模块,以实现多语言的支持。根据我们预期支持的不同语言,便需要对应的 plugin.xml,诸如于:
cc.unitmesh.javascript.xml
cc.unitmesh.rust.xml
cc.unitmesh.python.xml
cc.unitmesh.kotlin.xml
cc.unitmesh.java.xml
cc.unitmesh.go.xml
cc.unitmesh.cpp.xml最后,在不同的语言模块里,实现对应的功能即可。
上下文构建
为了简化这个过程,我们使用 Unit Eval 来展示如何构建两种类似的上下文。
静态代码分析
通过静态代码分析,我们可以得到当前的函数、当前的类、当前的文件等。再结合路径相似性,寻找最贴进的上下文。
private fun findRelatedCode(container: CodeContainer): List<CodeDataStruct> {
// 1. collects all similar data structure by imports if exists in a file tree
val byImports = container.Imports
.mapNotNull {
context.fileTree[it.Source]?.container?.DataStructures
}
.flatten()
// 2. collects by inheritance tree for some node in the same package
val byInheritance = container.DataStructures
.map {
(it.Implements+ it.Extend).mapNotNull { i ->
context.fileTree[i]?.container?.DataStructures
}.flatten()
}
.flatten()
val related = (byImports + byInheritance).distinctBy { it.NodeName}
// 3. convert all similar data structure to uml
return related
}
classRelatedCodeStrategyBuilder(private val context: JobContext) : CodeStrategyBuilder{
override fun build(): List<TypedIns> {
// ...
val findRelatedCodeDs = findRelatedCode(container)
val relatedCodePath = findRelatedCodeDs.map { it.FilePath}
val jaccardSimilarity = SimilarChunker.pathLevelJaccardSimilarity(relatedCodePath, currentPath)
val relatedCode = jaccardSimilarity.mapIndexed { index, d ->
findRelatedCodeDs[index] to d
}.sortedByDescending {
it.second
}.take(3).map {
it.first
}
//...
}
}上述的代码,我们可以通过代码的 Imports 信息作为相关代码的一部分。再通过代码的继承关系,来寻找相关的代码。最后,通过再路径相似性,来寻找最贴近的上下文。
相关代码分析
先寻找,再通过代码相似性,来寻找相关的代码。核心逻辑所示:
fun pathLevelJaccardSimilarity(chunks: List<String>, text: String): List<Double> {
//...
}
fun tokenize(chunk: String): List<String> {
return chunk.split(Regex("[^a-zA-Z0-9]")).filter { it.isNotBlank() }
}
fun similarityScore(set1: Set<String>, set2: Set<String>): Double{
//...
}详细见:SimilarChunker
VSCode 插件
TODO
TreeSitter
TreeSitter 是一个用于生成高效的自定义语法分析器的框架,由 GitHub 开发。它使用 LR(1)解析器,这意味着它可以在 O(n)时间内解析任何语言,而不是 O(n²)时间。它还使用了一种称为“语法树的重用”的技术,该技术使其能够在不重新解析整个文件的情况下更新语法树。
由于 TreeSitter 已经提供了多语言的支持,你可以使用 Node.js、Rust 等语言来构建对应的插件。详细见:TreeSitter。
根据我们的意图不同,使用 TreeSitter 也有不同的方式:
解析 Symbol
在代码自然语言搜索引擎 Bloop 中,我们使用 TreeSitter 来解析 Symbol,以实现更好的搜索质量。
;; methods
(method_declaration
name: (identifier) @hoist.definition.method)随后,根据不同的类型来决定如何显示:
pub static JAVA: TSLanguageConfig= TSLanguageConfig{
language_ids: &["Java"],
file_extensions: &["java"],
grammar: tree_sitter_java::language,
scope_query: MemoizedQuery::new(include_str!("./scopes.scm")),
hoverable_query: MemoizedQuery::new(
r#"
[(identifier)
(type_identifier)] @hoverable
"#,
),
namespaces: &[&[
// variables
"local",
// functions
"method",
// namespacing, modules
"package",
"module",
// types
"class",
"enum",
"enumConstant",
"record",
"interface",
"typedef",
// misc.
"label",
]],
};Chunk 代码
如下是 Improving LlamaIndex’s Code Chunker by Cleaning Tree-Sitter CSTs 中的 TreeSitter 的使用方式:
from tree_sitter importTree
def chunker(
tree: Tree,
source_code: bytes,
MAX_CHARS=512* 3,
coalesce=50# Any chunk less than 50 characters long gets coalesced with the next chunk
) -> list[Span]:
# 1. Recursively form chunks based on the last post (https://docs.sweep.dev/blogs/chunking-2m-files)
def chunk_node(node: Node) -> list[Span]:
chunks: list[Span] = []
current_chunk: Span= Span(node.start_byte, node.start_byte)
node_children = node.children
for child in node_children:
if child.end_byte - child.start_byte > MAX_CHARS:
chunks.append(current_chunk)
current_chunk = Span(child.end_byte, child.end_byte)
chunks.extend(chunk_node(child))
elif child.end_byte - child.start_byte + len(current_chunk) > MAX_CHARS:
chunks.append(current_chunk)
current_chunk = Span(child.start_byte, child.end_byte)
else:
current_chunk += Span(child.start_byte, child.end_byte)
chunks.append(current_chunk)
return chunks
chunks = chunk_node(tree.root_node)
# 2. Filling in the gaps
for prev, curr in zip(chunks[:-1], chunks[1:]):
prev.end = curr.start
curr.start = tree.root_node.end_byte
# 3. Combining small chunks with bigger ones
new_chunks = []
current_chunk = Span(0, 0)
for chunk in chunks:
current_chunk += chunk
if non_whitespace_len(current_chunk.extract(source_code)) > coalesce \
and"\n"in current_chunk.extract(source_code):
new_chunks.append(current_chunk)
current_chunk = Span(chunk.end, chunk.end)
if len(current_chunk) > 0:
new_chunks.append(current_chunk)
# 4. Changing line numbers
line_chunks = [Span(get_line_number(chunk.start, source_code),
get_line_number(chunk.end, source_code)) for chunk in new_chunks]
# 5. Eliminating empty chunks
line_chunks = [chunk for chunk in line_chunks if len(chunk) > 0]
return line_chunks度量体系设计
常用指标
代码接受率
AI 生成的代码被开发者接受的比例。
入库率
AI 生成的代码被开发者入库的比例。
开发者体验驱动
如微软和 GitHub 所构建的:DevEx: What Actually Drives Productivity: The developer-centric approach to measuring and improving productivity
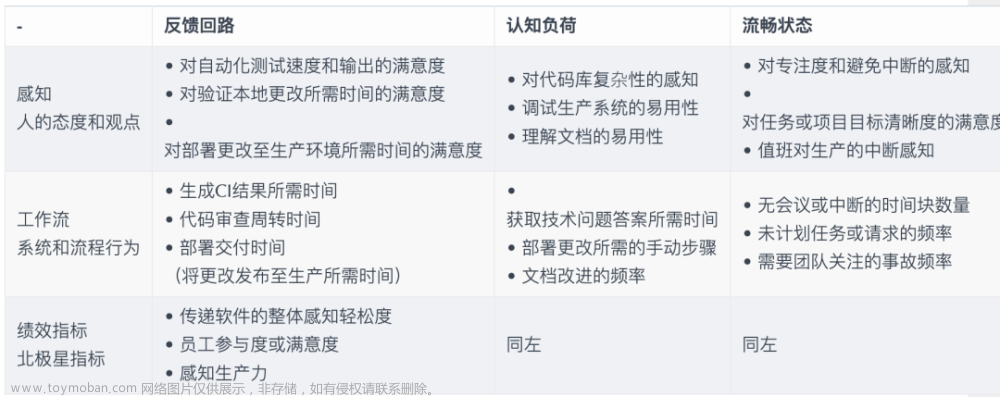
步骤 2:模型评估体系与微调试验
评估数据集:HumanEval
模型选择与测试
在结合公开 API 的大语言模型之后,我们就可以构建基本的 IDE 功能。随后,应该进一步探索适合于内部的模型,以适合于组织内部的效果。
模型选择
现有的开源模型里采用 LLaMA 架构相对比较多,并且由于其模型的质量比较高,其生态也相对比较完善。因此,我们也采用 LLaMA 架构来构建,即:DeepSeek Coder。
OpenBayes 平台部署与测试
随后,我们需要部署模型,并提供一个对应的 API,这个 API 需要与我们的 IDE 接口保持一致。这里我们采用了 OpenBayes 平台来部署模型。详细见: code/server 目录下的相关代码。
pip install -r requirements.txt
python server-python38.py如下是适用于 OpenBayes 的代码,以在后台提供公网 API:
if __name__ == "__main__":
try:
meta = requests.get('http://localhost:21999/gear-status', timeout=5).json()
url = meta['links'].get('auxiliary')
if url:
print("打开该链接访问:", url)
exceptException:
pass
uvicorn.run(app, host="0.0.0.0", port=8080)随后,在 IDE 插件中,我们就可以结合他们来测试功能。
大规模模型部署
结合模型量化技术,如 INT4,可以实现 6B 模型在消费级的显卡上进行本地部署。
(TODO)
模型微调
有监督微调(SFT)是指采用预先训练好的神经网络模型,并针对你自己的专门任务在少量的监督数据上对其进行重新训练的技术。
数据驱动的微调方法
结合 【SFT最佳实践 】中提供的权衡考虑:
样本数量少于 1000 且需注重基座模型的通用能力:优先考虑 LoRA。
如果特定任务数据样本较多且主要注重这些任务效果:使用 SFT。
如果希望结合两者优势:将特定任务的数据与通用任务数据进行混合配比后,再使用这些训练方法能得到更好的效果。
这就意味着:
| 任务类型 | 样本数量 | 通用编码数据集 |
|---|---|---|
| IDE AI 功能支持 | 少于 1000 | 需要 |
| 内部代码补全 | 大于 10,000 | 不需要 |
| IDE + 代码补全 | 大于 10,000 | 需要 |
通常来说,我们测试是结合 IDE 的功能,以及代码补全的功能,因此,我们需要合并两个数据集。
数据集构建
根据不同的模型,其所需要的指令也是不同的。如下是一个基于 DeepSeek + DeepSpeed 的数据集示例:
{
"instruction": "Write unit test for following code.\n<SomeCode>",
"output": "<TestCode>"
}下面是 LLaMA 模型的数据集示例:
{
"instruction": "Write unit test for following code.",
"input": "<SomeCode>",
"output": "<TestCode>"
}数据集构建
我们构建 Unit Eval 项目,以生成更适合于 AutoDev 的数据集。
代码补全。行内(Inline)、块内(InBlock)、块间(AfterBlock)三种场景。
单元测试生成。生成符合上下文的单元测试。
而为了提供 IDE 中的其他功能支持,我们结合了开源数据集,以及数据蒸馏的方式来构建数据集。
开源数据集
在 GitHub、HuggingFace 等平台上,有一些开源的数据集。
Magicoder: Source Code Is All You Need 中开源的两个数据集:
https://huggingface.co/datasets/ise-uiuc/Magicoder-OSS-Instruct-75K
https://huggingface.co/datasets/ise-uiuc/Magicoder-Evol-Instruct-110K
在 License 合适的情况下,我们可以直接使用这些数据集;在不合适的情况下,我们可以拿来做一些实验。
数据蒸馏
数据蒸馏。过去的定义是,即将大型真实数据集(训练集)作为输入,并输出一个小的合成蒸馏数据集。但是,我们要做的是直接用 OpenAI 这一类公开 API 的模型:
生成符合预期的数据集。
对数据集进行筛选,以保证数据集的质量。
对数据集进行扩充,以保证数据集的多样性。
对数据集进行标注,以保证数据集的可用性。
微调示例:OpenBayes + DeepSeek
在这里我们使用的是,以及 DeepSeek 官方提供的脚本来进行微调。
云 GPU: OpenBayes
GPU 算力:4090x2 (目测和微调参数有关,但是我试了几次 4090 还是不行)
微调脚本:https://github.com/deepseek-ai/DeepSeek-Coder
数据集:6000
我在 OpenBayes 上传了的 DeepSeek 模型:OpenBayes deepseek-coder-6.7b-instruct,你可以在创建时直接使用这个模型。

数据集信息
由 Unit Eval + OSS Instruct 数据集构建而来:
150 条补全(Inline,InBlock,AfterBlock)数据集。
150 条单元测试数据集。
3700 条 OSS Instruct 数据集。
而从结果来看,如何保持高质量的数据是最大的挑战。
测试视频:开源 AI 辅助编程方案:Unit Mesh 端到端打通 v0.0.1 版本
参数示例:
DATA_PATH="/openbayes/home/summary.jsonl"
OUTPUT_PATH="/openbayes/home/output"
MODEL_PATH="/openbayes/input/input0/"
!cd DeepSeek-Coder/finetune && deepspeed finetune_deepseekcoder.py \
--model_name_or_path $MODEL_PATH \
--data_path $DATA_PATH \
--output_dir $OUTPUT_PATH \
--num_train_epochs 1 \
--model_max_length 1024 \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 1 \
--evaluation_strategy "no" \
--save_strategy "steps" \
--save_steps 375 \
--save_total_limit 10 \
--learning_rate 1e-4 \
--warmup_steps 10 \
--logging_steps 1 \
--lr_scheduler_type "cosine" \
--gradient_checkpointing True \
--report_to "tensorboard" \
--deepspeed configs/ds_config_zero3.json \
--bf16 True运行日志:
`use_cache=True` is incompatible with gradient checkpointing. Setting`use_cache=False`...
0%| | 0/375[00:00<?, ?it/s]`use_cache=True` is incompatible with gradient checkpointing. Setting`use_cache=False`...
{'loss': 0.6934, 'learning_rate': 0.0, 'epoch': 0.0}
{'loss': 0.3086, 'learning_rate': 3.0102999566398115e-05, 'epoch': 0.01}
{'loss': 0.3693, 'learning_rate': 4.771212547196624e-05, 'epoch': 0.01}
{'loss': 0.3374, 'learning_rate': 6.020599913279623e-05, 'epoch': 0.01}
{'loss': 0.4744, 'learning_rate': 6.989700043360187e-05, 'epoch': 0.01}
{'loss': 0.3465, 'learning_rate': 7.781512503836436e-05, 'epoch': 0.02}
{'loss': 0.4258, 'learning_rate': 8.450980400142567e-05, 'epoch': 0.02}
{'loss': 0.4027, 'learning_rate': 9.030899869919434e-05, 'epoch': 0.02}
{'loss': 0.2844, 'learning_rate': 9.542425094393248e-05, 'epoch': 0.02}
{'loss': 0.3783, 'learning_rate': 9.999999999999999e-05, 'epoch': 0.03}其它:
详细的 Notebook 见:code/finetune/finetune.ipynb
微调参数,详细见:Trainer
步骤 3:围绕意图的数据工程与模型演进
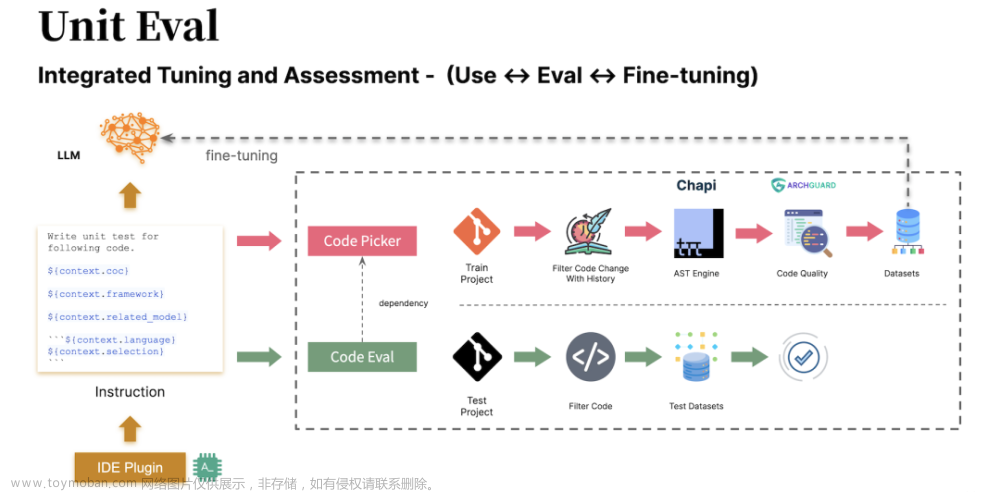
Unit Eval 是一个针对于构建高质量代码微调的开源工具箱。其三个核心设计原则:
统一提示词(Prompt)。统一工具-微调-评估底层的提示词。
代码质量管道。诸如于代码复杂性、代码坏味道、测试坏味道、API 设计味道等。
可扩展的质量阈。自定义规则、自定义阈值、自定义质量类型等。
即要解决易于测试的数据集生成,以及易于评估的模型评估问题。
IDE 指令设计与演化
AutoDev 早期采用的是 OpenAI API,其模型能力较强,因此在指令设计上比较强大。而当我们需要微调里,我们需要更简单、易于区分的指令来构建。
模板指令
如下是在 AutoDev 中精简化后的 Prompt 示例:
Write unit test for following code.
${context.testFramework}
${context.coreFramework}
${context.testSpec}
```${context.language}
${context.related_model}
${context.selection}
```其中包含了:
技术栈上下文
测试技术栈上下文
代码块(类、函数)的输入和输出信息
而这个模板指令,也是我们在 Unit Eval 中所采用的指令。
统一指令模板
为了实现统一的指令模板,我们引入了 Apache Velocity 模板引擎来实现,并通过 Chocolate Factory 实现底层的通用逻辑:
工具侧。在 IDE 插件中,直接通过 Velocity 模板引擎、基于 Chocolate Factory 来实现指令的生成。
数据集成。在 Unit Eval 中,生成适用于模板的数据集。
结果评估。基于 Chocolate Factory 的实现,对模板的结果进行评估。
高质量数据集生成
年初(2023 年 4 月),我们做了一系列的代码微调探索, 在那篇 《AI 研发提效的正确姿势:开源 LLM + LoRA 》里,企业应该开始着力于:
规范与流程标准化
工程化的数据准备
高质量的脱敏数据
只有微调是不够的,模型需要与工具紧密相结合。
质量流水线设计示例

基于 Thoughtworks 在软件工程的丰富经验,以及 Thoughtworks 的架构治理开源工具 ArchGuard 作为基础设施。在 UnitEval 中,我们也将代码质量的筛选构建成 pipeline 的方式:
代码复杂度。在当前的版本设计里,可以直接通过代码复杂度来决定是否放代码文件进入数据库。
不同的坏味道检查类型。诸如于代码坏味道、测试坏味道等。
特定的规则检查。Controller 的 API 设计、Repository 的 SQL 设计 等。
而基于 ArchGuard 中所提供的丰富代码质量和架构质量分析能力,诸如 OpenAPI、 SCA(软件依赖分析)能力,我们也在思考未来是否也加入相关的设计。
实现高质量数据集生成
如下是 Unit Eval 0.3.0 的主要代码逻辑:
val codeDir = GitUtil
.checkoutCode(config.url, config.branch, tempGitDir, config.gitDepth)
.toFile().canonicalFile
logger.info("start walk $codeDir")
val languageWorker = LanguageWorker()
val workerManager = WorkerManager(
WorkerContext(
config.codeContextStrategies,
config.codeQualityTypes,
config.insOutputConfig,
pureDataFileName = config.pureDataFileName(),
config.completionTypes,
config.maxCompletionEachFile,
config.completionTypeSize,
qualityThreshold = InsQualityThreshold(
complexity = InsQualityThreshold.MAX_COMPLEXITY,
fileSize = InsQualityThreshold.MAX_FILE_SIZE,
maxLineInCode = config.maxLineInCode,
maxCharInCode = config.maxCharInCode,
maxTokenLength = config.maxTokenLength,
)
)
)
workerManager.init(codeDir, config.language)随后是根据不同的质量门禁,来进行不同的质量检查:
fun filterByThreshold(job: InstructionFileJob) {
val summary = job.fileSummary
if(!supportedExtensions.contains(summary.extension)) {
return
}
// limit by complexity
if(summary.complexity > context.qualityThreshold.complexity) {
logger.info("skip file ${summary.location} for complexity ${summary.complexity}")
return
}
// like js minified file
if(summary.binary || summary.generated || summary.minified) {
return
}
// if the file size is too large, we just try 64k
if(summary.bytes > context.qualityThreshold.fileSize) {
logger.info("skip file ${summary.location} for size ${summary.bytes}")
return
}
// limit by token length
val encoded = enc.encode(job.code)
val length = encoded.size
if(length > context.qualityThreshold.maxTokenLength) {
logger.info("skip file ${summary.location} for over ${context.qualityThreshold.maxTokenLength} tokens")
println("| filename: ${summary.filename} | tokens: $length | complexity: ${summary.complexity} | code: ${summary.lines} | size: ${summary.bytes} | location: ${summary.location} |")
return
}
val language = SupportedLang.from(summary.language)
val worker = workers[language] ?: return
worker.addJob(job)
}在过虑之后,我们就可以由不同语言的 Worker 来进行处理,诸如 JavaWorker、PythonWorker 等。
val lists = jobs.map { job ->
val jobContext = JobContext(
job,
context.qualityTypes,
fileTree,
context.insOutputConfig,
context.completionTypes,
context.maxCompletionInOneFile,
project = ProjectContext(
compositionDependency = context.compositionDependency,
),
context.qualityThreshold
)
context.codeContextStrategies.map { type ->
val codeStrategyBuilder = type.builder(jobContext)
codeStrategyBuilder.build()
}.flatten()
}.flatten()根据用户选择的上下文策略,我们就可以构建出不同的上下文,如:相关上下文、相似上下文等
在上下文策略中检查代码质量
SimilarChunksStrategyBuilder 主要逻辑如下
使用配置中指定的规则检查以识别存在问题的数据结构。
收集所有具有相似数据结构的数据结构。
为每个被识别的数据结构中的函数构建完成生成器。
过滤掉具有空的前置和后置光标的完成生成器。
使用JavaSimilarChunker计算块补全的相似块。
为每个完成生成器创建SimilarChunkIns对象,包括语言、前置光标、相似块、后置光标、输出和类型的相关信息。
返回生成的SimilarChunkIns对象的列表。
在规则检查里,我们可以通过不同的规则来检查不同的代码质量问题,如:代码坏味道、测试坏味道、API 设计味道等。文章来源:https://www.toymoban.com/news/detail-809404.html
fun create(types: List<CodeQualityType>, thresholds: Map<String, Int> = mapOf()): List<QualityAnalyser> {
return types.map { type ->
when(type) {
CodeQualityType.BadSmell-> BadsmellAnalyser(thresholds)
CodeQualityType.TestBadSmell-> TestBadsmellAnalyser(thresholds)
CodeQualityType.JavaController-> JavaControllerAnalyser(thresholds)
CodeQualityType.JavaRepository-> JavaRepositoryAnalyser(thresholds)
CodeQualityType.JavaService-> JavaServiceAnalyser(thresholds)
}
}
}其它
我们会在 GitHub 上持续更新这个教程: https://github.com/phodal/build-ai-coding-assistant,欢迎在 GitHub 上讨论。文章来源地址https://www.toymoban.com/news/detail-809404.html
到了这里,关于构建你自己的 AI 辅助编码助手:从 IDE 插件、代码数据生成和模型微调(万字长文)...的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!