哈希值(Hash Value),也称为哈希码、散列值或摘要,是一种将任意长度的输入数据转换为固定长度字符串(通常是一串数字和字母)的算法的结果。哈希值通常用于唯一标识数据,以便快速检索或比较数据。哈希值的特点包括:
-
固定长度:无论输入数据的大小如何,哈希函数都会生成固定长度的哈希值。这意味着无论输入数据大小,哈希值的长度是固定的。
-
唯一性:不同的输入数据通常会产生不同的哈希值,但在某些情况下,可能会出现哈希碰撞,即不同的输入数据生成相同的哈希值。好的哈希算法会尽量减少碰撞的概率。
-
不可逆性:哈希函数是单向的,意味着很难从哈希值还原出原始输入数据。这是哈希函数的一个关键特性,使其适用于密码学和数据安全。
-
高效性:哈希函数应该能够快速计算出哈希值,以便在实际应用中能够迅速处理大量数据。
哈希值在各种计算机科学和信息安全领域中有广泛的应用,包括但不限于以下方面:
-
密码学:哈希函数用于存储密码的安全散列,以确保用户密码不以明文存储。这也可以用于验证密码的正确性。
-
数据完整性验证:哈希值用于验证数据是否在传输或存储过程中被篡改。通过比较接收到的数据的哈希值与发送方生成的哈希值,可以检测到数据是否被损坏或篡改。
-
数据结构:哈希表(Hash Table)是一种常见的数据结构,用于快速查找数据。哈希值用作数据的索引,以便快速访问。
-
数字签名:数字签名算法使用哈希函数来生成文件的哈希值,并使用私钥来签名哈希值,以确保文件的完整性和身份验证。
-
数据去重和存储优化:在数据去重和存储优化中,哈希值可用于识别重复的数据块,以节省存储空间。
常见的哈希算法包括MD5、SHA-1、SHA-256、SHA-3等。然而,由于计算能力的提高和安全性问题,某些哈希算法已经不再被广泛使用,尤其是在安全敏感的应用中,更强大的哈希算法被推荐使用。
如果想要快速检查两个文件是否一致,可以使用文件哈希算法(如MD5、SHA-256)来计算每个文件的哈希值,然后比较这些哈希值。如果两个文件的哈希值相同,那么它们的内容相同。
以下是其Python实现:
# 导入 hashlib 模块,以便使用哈希函数
import hashlib
# 定义一个函数,用于计算文件的哈希值
def calculate_file_hash(file_path, hash_algorithm="sha256"):
# 创建一个哈希对象,使用指定的哈希算法
hash_obj = hashlib.new(hash_algorithm)
# 打开文件以二进制只读模式
with open(file_path, "rb") as file:
while True:
# 从文件中读取数据块(64 KB大小)
data = file.read(65536) # 64 KB buffer
if not data:
break
# 更新哈希对象,将数据块添加到哈希值中
hash_obj.update(data)
# 返回哈希值的十六进制表示
return hash_obj.hexdigest()
# 指定要比较的两个文件的路径
file1 = "file1.h5"
file2 = "file2.h5"
# 使用哈希函数计算文件1的哈希值
hash1 = calculate_file_hash(file1)
# 使用哈希函数计算文件2的哈希值
hash2 = calculate_file_hash(file2)
# 比较两个哈希值,如果相同,表示文件内容相同
if hash1 == hash2:
print("两个文件相同")
else:
print("两个文件不同")
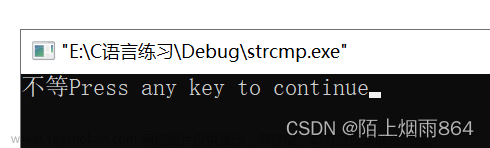
如果哈希值相同,代码将输出"两个文件相同",否则输出"两个文件不同"。哈希值的计算是通过 calculate_file_hash 函数完成的,它使用所选的哈希算法(默认为SHA-256)逐块读取文件数据,将其添加到哈希值中,并最终返回哈希值的十六进制表示。文章来源:https://www.toymoban.com/news/detail-809872.html
安装好hashlib模块,替换文件路径运行即可。文章来源地址https://www.toymoban.com/news/detail-809872.html
到了这里,关于【Python】使用文件哈希算法快速比较两个文件是否相同(代码实现)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!