准备阶段
- 配套软件包Ascend-cann-toolkit和Ascend-cann-nnae
- 适配昇腾的Pytorch
- 适配昇腾的Torchvision Adapter
- 下载ChatGLM3代码
- 下载chatglm3-6b模型,或在modelscope里下载
避坑阶段
- 每个人的服务器都不一样,在ChatGLM3/issues中别人只需要修改指定驱动,但是我的不行

- 删除模型文件包中的model.safetensors.index.json,否则加载模型时会自动加载safetensors文件,而不加载bin文件
/home/anaconda3/envs/sakura/lib/python3.9/site-packages/torch_npu/contrib/transfer_to_npu.py:124: RuntimeWarning: torch.jit.script will be disabled by transfer_to_npu, which currently does not support it, if you need to enable torch.jit.script, please do not use transfer_to_npu.
warnings.warn(msg, RuntimeWarning)
Loading checkpoint shards: 0%| | 0/7 [00:00<?, ?it/s]
Traceback (most recent call last):
File "/home/HwHiAiUser/work/ChatGLM3/basic_demo/cli_demo.py", line 22, in <module>
model = AutoModel.from_pretrained(MODEL_PATH, trust_remote_code=True).npu().eval()
File "/home/anaconda3/envs/sakura/lib/python3.9/site-packages/transformers/models/auto/auto_factory.py", line 558, in from_pretrained
return model_class.from_pretrained(
File "/home/anaconda3/envs/sakura/lib/python3.9/site-packages/transformers/modeling_utils.py", line 3187, in from_pretrained
) = cls._load_pretrained_model(
File "/home/anaconda3/envs/sakura/lib/python3.9/site-packages/transformers/modeling_utils.py", line 3560, in _load_pretrained_model
state_dict = load_state_dict(shard_file)
File "/home/anaconda3/envs/sakura/lib/python3.9/site-packages/transformers/modeling_utils.py", line 467, in load_state_dict
with safe_open(checkpoint_file, framework="pt") as f:
FileNotFoundError: No such file or directory: "/home/HwHiAiUser/models/chatglm3-6b/model-00001-of-00007.safetensors"
/home/anaconda3/envs/sakura/lib/python3.9/tempfile.py:817: ResourceWarning: Implicitly cleaning up <TemporaryDirectory '/tmp/tmp1ygjyx3i'>
_warnings.warn(warn_message, ResourceWarning)

添加代码
找到ChatGLM3/basic_demo/cli_demo.py
添加以下代码:
import torch
import torch_npu
import torchvision
import torchvision_npu
from torch_npu.contrib import transfer_to_npu
import os
import platform
import time
torch_device = "npu:3" # 0~7
torch.npu.set_device(torch.device(torch_device))
torch.npu.set_compile_mode(jit_compile=False)
option = {}
option["NPU_FUZZY_COMPILE_BLACKLIST"] = "Tril"
torch.npu.set_option(option)
print("torch && torch_npu import successfully")
模型加载部分修改为:文章来源:https://www.toymoban.com/news/detail-810007.html
model = AutoModel.from_pretrained(MODEL_PATH, trust_remote_code=True).npu().eval()
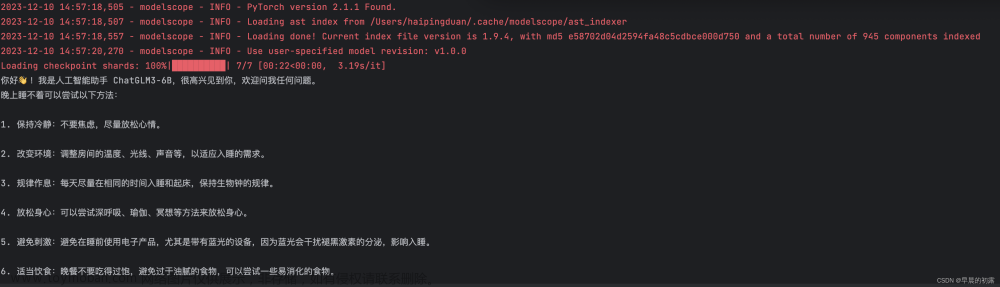
结果展示
 文章来源地址https://www.toymoban.com/news/detail-810007.html
文章来源地址https://www.toymoban.com/news/detail-810007.html
到了这里,关于昇腾910b部署Chatglm3-6b进行流式输出【pytorch框架】NPU推理的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!