问题描述
当我在调试模型的时候,出现了如下的问题
/opt/conda/conda-bld/pytorch_1656352465323/work/aten/src/ATen/native/cuda/IndexKernel.cu:91: operator(): block: [5,0,0], thread: [63,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && “index out of bounds”` failed.
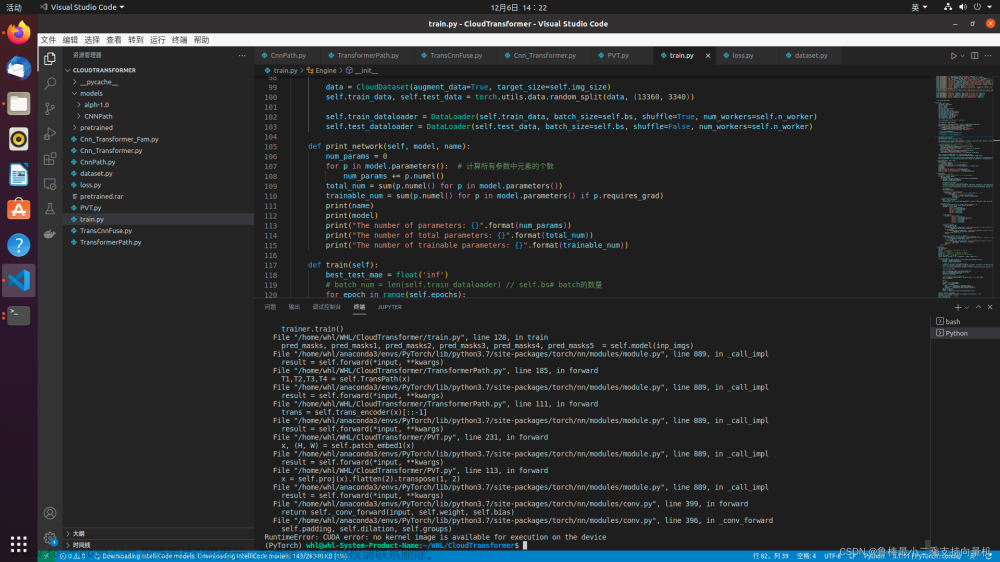
通过提示信息可以知道是个数组越界的问题。但是如图一中第二行话所说这个问题可能并不出在提示的代码段。
一开始碰到这个问题就一个劲儿地查看提示的错误代码,发现调整了代码段之后,问题依然存在在并且提示的问题代码变化了。
解决思路
首先明确一点,如图中描述的"RuntimeError: CUDA error: device-side assert triggered"该类问题,不应该仅从提示的代码进行检查。问题可能出在别的地方。
通过检查代码,以及查找出现类似问题的解中发现对于,“index >= -sizes[i] && index < sizes[i] && “index out of bounds””,这类数组越界的问题,如果大家的模型任务是用于分类任务,可以查看下自己模型在设置类别数量时,数值是否大于数据集中的给定的类别。
发现问题:
因为本人自己修改了COCO的dataset,所以在赋值类别数量的时候如下代码文章来源:https://www.toymoban.com/news/detail-810514.html
num_classes = 20 if args.dataset_file != 'coco' else 91
修改过后的的dataset_file名称为coco_vl,所以类别给了20,实际模型在最后预测阶段的类别应该为91,所以在criterion阶段(计算loss)时会报数值越界错误。
更改代码如下:文章来源地址https://www.toymoban.com/news/detail-810514.html
num_classes = 20 if args.dataset_file != 'coco' and args.dataset_file != 'coco_vl' else 91
总结
- 分类任务模型中,出现类似于数值越界的问题,可以优先查看下dataset中的类别是否填写符合要求,不应该小于模型预测的类别数量。
- 出现device-side assert triggered的BUG不能只关注报错代码
到了这里,关于【RuntimeError: CUDA error: device-side assert triggered】问题与解决的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!


![[已解决]RuntimeError: CUDA error: no kernel image is available for execution on the device](https://imgs.yssmx.com/Uploads/2024/02/782952-1.png)