基于python机器学习XGBoost算法农业数据可视化分析预测系统
一、项目简介
基于python机器学习XGBoost算法农业数据可视化分析预测系统,旨在帮助农民和相关从业者更好地预测农作物产量,以优化农业生产。该系统主要包括四个功能模块。
首先,农作物数据可视化模块利用Echarts、Ajax、Flask、PyMysql技术实现了可视化展示农作物产量相关数据的功能。
其次,产量预测模块使用pandas、numpy等技术,通过对气象和农作物产量关系数据集的分析和训练,实现了对农作物产量的预测功能。该模块可以对当前或未来某一时间段的农作物产量进行预测,并提供预测结果的可视化展示。
然后,用户登录与用户注册模块使用layui、Flask、PyMysql技术实现了用户登录和注册功能。用户可以通过登录系统后,利用该系统提供的预测和可视化功能,更好地规划和管理自己的农业生产。
最后,数据管理模块使用layui、Flask、PyMysql技术,实现了用户管理、公告管理和农作物数据管理等功能。系统管理员可以通过后台界面对用户信息、公告信息和农作物数据进行管理和维护,保证系统的正常运行和信息安全。
本系统的实现对农业生产的优化具有积极的意义。通过对气象和农作物产量关系数据的分析和训练,该系统可以帮助用户更好地了解不同作物产量随时间变化的趋势和规律,提高农作物的产量和品质,促进农业生产的可持续发展。
二、开发环境
| 开发环境 | 版本/工具 |
|---|---|
| PYTHON | 3.x |
| 开发工具 | PyCharm2021 |
| 操作系统 | Windows 10 |
| 内存要求 | 16GB |
| 浏览器 | Firefox |
| 数据库 | MySQL 8.0 |
| 数据库工具 | Navicat Premium 15 |
| 项目框架 | FLASK、layui |
三、项目技术
后端:Flask、sklearn、PyMySQL、MySQL、urllib
前端:Jinja2、Jquery、Ajax、layui
四、功能结构
农业数据大屏可视化模块:通过ECharts实现数据可视化,展示农作物产量的趋势、关联因素等。
机器学习预测农作物产量模型构建与训练:使用Scikit-learn、Pandas、NumPy构建机器学习模型,对农作物产量进行预测。
用户登录与注册:通过Flask、PyMySQL、LAYUI实现用户登录和注册功能。
系统后台管理模块:
用户模块:管理用户信息,权限等。
公告模块:发布和管理系统相关公告信息。
农作物数据管理模块:存储和管理与农作物产量预测相关的数据集。
预测可视化后台交互:提供用户与预测数据的交互界面,使用Ajax请求后端数据接口展示数据可视化结果。
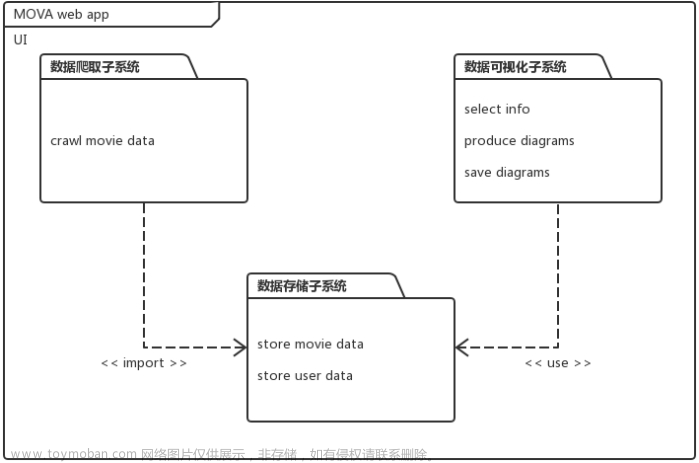
系统结构图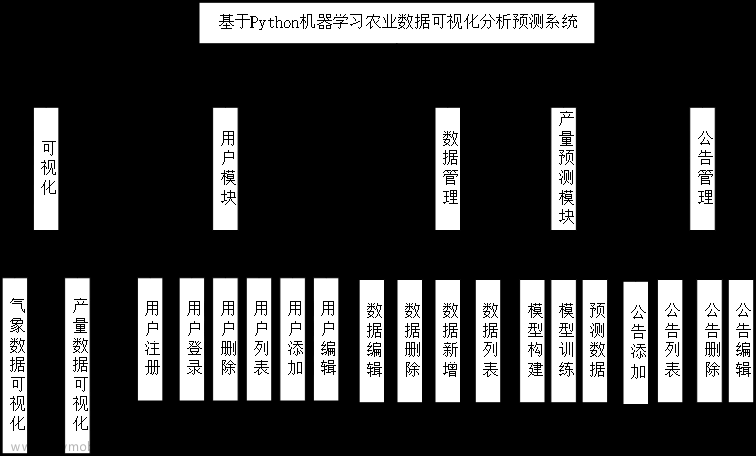
五、功能实现
模型构建
def model(X_data,y_label,testst,prediction):
"""模型搭建
"""
global params_xgb #模型参数,设置全局变量便于调参
n_splits = 25
res = []
kf = KFold(n_splits = n_splits, shuffle=True, random_state=520)
for i, (train_index, test_index) in enumerate(kf.split(X_data)):
print('第{}次训练...'.format(i+1))
train_data = X_data.iloc[train_index]
train_label = y_label.iloc[train_index]
valid_data = X_data.iloc[test_index]
valid_label = y_label.iloc[test_index]
xgb_train = xgb.DMatrix(train_data, label=train_label)
xgb_valid = xgb.DMatrix(valid_data, valid_label)
evallist = [(xgb_valid, 'eval'), (xgb_train, 'train')]
cgb_model = xgb.train(params_xgb, xgb_train, num_boost_round=500 , evals=evallist, verbose_eval=500, early_stopping_rounds=300, feval=myFeval)
valid = cgb_model.predict(xgb_valid, ntree_limit=cgb_model.best_ntree_limit)
valid_score = mean_squared_error(valid_label,valid)*0.5
if valid_score > 0.01:
#验证集分数不好的模型丢弃
continue
xgb_test = xgb.DMatrix(testst)
preds = cgb_model.predict(xgb_test, ntree_limit=cgb_model.best_ntree_limit)
res.append(preds)
print("\n")

使用XGBoost(Extreme Gradient Boosting)算法进行回归任务的模型搭建函数。
-
参数说明:
-
X_data: 训练数据的特征。 -
y_label: 训练数据的目标标签。 -
testst: 测试数据的特征,用于进行预测。 -
prediction: 预测结果的存储列表。
-
-
交叉验证:
- 该模型使用了 K 折交叉验证(KFold),将数据集分成训练集和验证集,循环进行训练和验证。这有助于评估模型的性能,并减少由于数据集划分不同而引起的波动。
-
XGBoost模型训练:
- 使用 XGBoost 中的
xgb.train函数进行模型训练。 - 参数
params_xgb是全局变量,应该在代码其他地方定义,包含了 XGBoost 模型的超参数设置。 - 训练中使用了早停法(early stopping),如果在一定迭代次数内验证集分数没有提高,则提前结束训练。
- 使用 XGBoost 中的
-
模型预测:
- 使用训练好的模型对验证集和测试集进行预测。
- 验证集预测结果与真实标签计算均方误差(Mean Squared Error),如果分数大于0.01,则该模型被丢弃。
- 如果验证集分数较好,将测试集的预测结果添加到
res列表中。
-
输出信息:
- 打印每次训练的信息,包括训练次数、验证集分数等。
封装类用于网格调参
class XGBoostre(object):
"""封装类用于网格调参
"""
def __init__(self,**kwargs):
self.params = kwargs
if "num_boost_round" in self.params:
self.num_boost_round = self.params["num_boost_round"]
self.params.update({'objective': 'reg:squarederror','silent': 0,'seed': 1000})
def fit(self,x_train,y_train):
xgb_train = xgb.DMatrix(x_train, label=y_train)
self.bst = xgb.train(params=self.params, dtrain=xgb_train, num_boost_round=self.num_boost_round, verbose_eval=100, feval=myFeval)
def predict(self,x_pred):
dpred = xgb.DMatrix(x_pred)
return self.bst.predict(dpred)
def kfold(self,x_train,y_train,n_fold=5):
xgb_train = xgb.DMatrix(x_train, label=y_train)
bst_cv = xgb.cv(params=self.params, dtrain=xgb_train,feval=myFeval,num_boost_round=self.num_boost_round, nfold=n_fold,)
return bst_cv.iloc[-1,:]
def plt_feature_importance(self):
feat = pd.Series(self.bst.get_fscore()).sort_values(ascending=False)
feat.plot(title = "Feature_importance")
def get_params(self,deep=True):
return self.params
def set_params(self,**params):
self.params.update(params)
return self

-
初始化方法
__init__:- 这个方法用于初始化
XGBoostre类的实例。 - 使用
**kwargs来接收任意数量的关键字参数,并将这些参数存储在self.params字典中。 - 如果
"num_boost_round"存在于self.params中,则将其值存储在self.num_boost_round中。 - 设置默认的XGBoost参数,包括目标函数为
'reg:squarederror',不进行静默操作('silent': 0),并设置随机种子为1000。
- 这个方法用于初始化
-
fit 方法:
- 该方法用于训练XGBoost模型。
- 将训练数据
x_train和y_train转换为xgb.DMatrix格式。 - 使用
xgb.train函数进行模型训练,并保存训练好的模型为self.bst。
-
predict 方法:
- 该方法用于使用训练好的模型进行预测。
- 将待预测数据
x_pred转换为xgb.DMatrix格式。 - 使用训练好的模型
self.bst进行预测,并返回预测结果。
-
kfold 方法:
- 该方法执行K折交叉验证。
- 使用
xgb.cv函数进行K折交叉验证,并返回交叉验证的结果。
-
plt_feature_importance 方法:
- 该方法用于绘制特征重要性。
- 获取模型中特征的重要性得分,并将其排序。
- 使用
pd.Series.plot方法绘制特征重要性的条形图。
-
get_params 方法:
- 该方法用于获取当前设置的XGBoost参数。
- 返回存储在
self.params中的参数。
-
set_params 方法:
- 该方法用于更新XGBoost参数。
- 使用传入的关键字参数更新
self.params字典中的参数,并返回更新后的参数。
这个XGBoostre类为XGBoost模型提供了一个封装接口,使得用户可以更方便地进行模型训练、预测和评估,同时还可以进行参数调优和特征重要性分析。
训练模型
if __name__ == "__main__":
deal_loss()
change()
change_week()
params_xgb = {
'booster': 'gbtree',
'objective': 'reg:squarederror',
'eval_metric': 'rmse', # 对于回归问题,默认值是rmse,对于分类问题,默认值是error
'gamma': 0.1, #损失下降多少才分裂
'max_depth': 4,
'lambda': 1.2, #控制模型复杂度的权重值的L2曾泽化参数,参数越大越不容易过拟合
'subsample': 0.9, #随机采样的训练样本
'colsample_bytree': 0.9, #生成树时特征采样比例
'min_child_weight': 3, # 6
'silent': 0, #信息输出设置成1则没有信息输出
'eta': 0.12, #类似学习率
'seed': 1000,
'nthread': 9,
}
X_data,y_label,testst,prediction = get_data()
model(X_data,y_label,testst,prediction)
df = pd.read_csv("result.csv",encoding="gbk")
df["区县id"] = df["columns"].apply(arr)

对预测模型进行训练和预测,然后将结果保存到一个 CSV 文件中,并进行后续的数据处理。
-
XGBoost模型参数设置:
- 定义了一个字典
params_xgb,包含了 XGBoost 模型的超参数设置。这些参数控制了模型的结构和训练过程。
- 定义了一个字典
-
获取数据:
- 调用
get_data()函数,但代码中未提供该函数的实现。这个函数用于获取训练数据 (X_data,y_label) 和测试数据 (testst)。
- 调用
-
模型训练:
- 调用
model函数,传入训练数据和测试数据,进行模型训练和预测。模型的超参数通过params_xgb传递。
- 调用
-
读取CSV文件并进行数据处理:
- 使用 Pandas (
pd) 读取一个 CSV 文件,文件名为 “result.csv”,使用 GBK 编码。 - 对 DataFrame 中的 “columns” 列应用
arr函数,但未提供arr函数的实现。
- 使用 Pandas (
系统可视化数据请求接口

@app.route('/')
def main_page():
month_rain = data_service.get_month_rain_volume()
ave_wind = data_service.get_ave_wind()
count, output, weather = data_service.get_total()
yearly_outputs = data_service.get_yearly_output()
months_temp = data_service.get_months_temp()
times_selling = data_service.get_times_selling()
months_sun = data_service.get_months_sun()
table_list = data_service.get_table_list()
return render_template("main.html", month_rain=month_rain,
ave_wind=ave_wind,
table_list=table_list,
count=count, output=output, weather=weather,
yearly_outputs=yearly_outputs, months_temp=months_temp,
times_selling=times_selling, months_sun=months_sun)
-
数据获取:
-
month_rain = data_service.get_month_rain_volume(): 获取月降雨量的数据,是通过调用get_month_rain_volume函数从data_service中获取。 -
ave_wind = data_service.get_ave_wind(): 获取平均风速的数据,是通过调用get_ave_wind函数从data_service中获取。 -
count, output, weather = data_service.get_total(): 获取总数、输出和天气的数据,是通过调用get_total函数从data_service中获取。 - 其他类似的语句用于获取其他数据,如年度产出、月温度、销售次数、月日照时间等。
-
-
HTML 模板渲染:
-
return render_template("main.html", ...): 使用 Flask 提供的render_template函数渲染 HTML 模板。传递了多个变量作为模板中的参数,这些变量包括上面获取的各种数据。
-
-
返回结果:
-
main.html模板将使用传递的数据进行渲染,然后作为 HTTP 响应返回给用户。
-
模型评分 0.5*mse
def myFeval(preds, xgbtrain):
"""模型评分 0.5*mse
"""
xgbtrain = xgbtrain.get_label() #将xgboost.core.DMatrix类转化为ndarray类别
score = mean_squared_error(xgbtrain,preds)*0.5
return 'myFeval', score

自定义评估函数 myFeval,用于在XGBoost模型训练过程中评估模型的性能。
-
参数解释:
-
preds: 预测的目标变量值。 -
xgbtrain: XGBoost训练数据,通常是xgboost.DMatrix类型。
-
-
函数逻辑:
-
xgbtrain = xgbtrain.get_label(): 将xgbtrain转换为ndarray类型,通过调用get_label()方法获取标签。这是将XGBoost的DMatrix转换为NumPy数组的操作。 -
score = mean_squared_error(xgbtrain, preds) * 0.5: 计算均方误差(Mean Squared Error,MSE),然后乘以0.5。这是一个模型评估指标,用于衡量模型预测值与实际标签之间的平方差。将MSE乘以0.5可能是为了得到更合适的评估分数。 -
return 'myFeval', score: 返回一个元组,包含自定义评估名称 ‘myFeval’ 和计算得到的分数。该评估函数主要用于XGBoost模型训练中,作为
eval_metric参数的值。这个函数的设计是为了与XGBoost的内置评估函数保持一致,并且使用MSE的一半作为最终评估分数。
-
六、系统实现
启动项目

可视化模块主要实现了对各个地区农业产量的轮播数据展示、对气象变化归路展 示、对气象天气进行分类统计、对日照时间进行统计柱状图分析等功能。实现流程首先 通过浏览器发动 http 请求,Flask 接收到请求后,通过 PyMysql 对数据库进行查询,然 后格式化与分析后响应给前端,前端通过 Echarts 技术在进行可视化解析与渲染,最终 实现可视化效果。

用户模块核心带主要是用户登录时候的校验,这里以用户登录的业务逻辑层代码为
例,如下图 所示。

登录页面

注册页面
管理员登录系统后台管理:
系统用户管理
公告管理

产量数据管理
气象数据管理

产量预测可视化分析


系统个人登录管理
普通用户登录:


七、总结
基于XGBoost的算法分析预测具有许多优势,这些优势使得XGBoost成为许多应用场景的首选算法之一。
-
高性能:
- XGBoost是一种梯度提升算法,它在性能上表现出色。通过使用并行处理和基于特征的分裂方法,XGBoost能够快速、高效地处理大规模数据集。
-
强大的正则化:
- XGBoost通过正则化项(如L1和L2正则化)提供了对模型的强大控制,有助于防止过拟合。这使得模型更具泛化能力,可以适用于不同的数据集。
-
处理缺失值:
- XGBoost能够自动处理缺失值。在实际应用中,数据中的缺失值是常见的问题,而XGBoost能够有效地处理这些情况,而不需要进行额外的数据处理。
-
可解释性:
- XGBoost具有一定的可解释性,可以输出特征的重要性得分。这对于理解模型对农作物产量预测中哪些特征起到关键作用非常有帮助,从而为农业决策提供支持。
-
适用于多种任务:
- XGBoost不仅可以用于回归问题(如农作物产量预测),还可以用于分类和排序等任务。这种通用性使得XGBoost在不同类型的问题中都能够展现出色的性能。
-
可扩展性:
- XGBoost具有良好的可扩展性,可以应对大规模数据和高维特征。它支持分布式计算,可以在分布式环境中运行,提高了处理大规模数据时的效率。
-
特征重要性评估:
- XGBoost可以输出特征的相对重要性,帮助用户理解模型对输入特征的依赖程度。这对于农作物产量预测系统的可解释性和可理解性非常有价值。
八、结语
总结来说,XGBoost在性能、鲁棒性和可解释性等方面都表现出色,使其成为解决复杂问题的强大工具,也为农业数据预测提供了可靠的建模手段。
需项目资料/商业合作/交流探讨等可以添加下面个人名片,感谢各位的喜欢与支持!文章来源:https://www.toymoban.com/news/detail-810606.html
后续持续更新更多优质内容!文章来源地址https://www.toymoban.com/news/detail-810606.html
到了这里,关于基于python集成学习算法XGBoost农业数据可视化分析预测系统的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!