非数值型的分类变量
有很多非数字的数据,这里介绍如何使用它来进行机器学习。
在本教程中,您将了解什么是分类变量,以及处理此类数据的三种方法。
本课程所需数据集夸克网盘下载链接:https://pan.quark.cn/s/9b4e9a1246b2
提取码:uDzP
1、简介
一个分类变量只接受有限数量的值。
- 考虑一个调查,询问你多久吃一次早餐,并提供四个选项:“从不”,“很少”,“大多数天”或“每天”。在这种情况下,数据是分类的,因为响应属于一组固定的类别。
- 如果人们回答了一份关于他们拥有哪个品牌汽车的调查,响应将属于类别,如“本田”,“丰田”和“福特”。在这种情况下,数据也是分类的。
如果你尝试在没有预处理的情况下将这些变量输入大多数Python机器学习模型中,你将会收到错误。在本教程中,我们将比较三种用于准备分类数据的方法。
2、三种方法的使用
1) 删除分类变量
处理分类变量最简单的方法是从数据集中删除它们。这种方法只有在列中不包含有用信息的情况下才能很好地工作。
2) 有序编码
Ordinal encoding 标签编码将每个惟一值分配给不同的整数。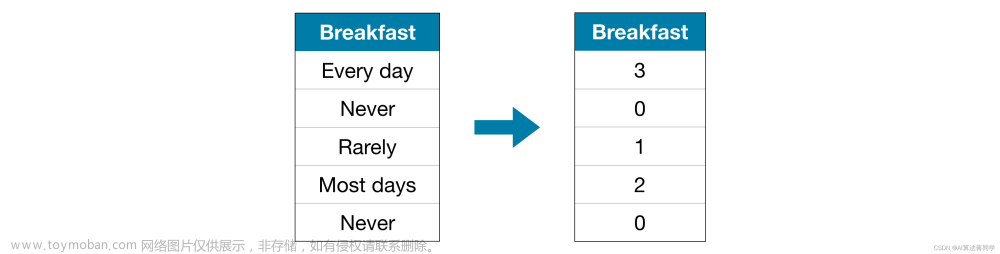
这种方法假设类别的顺序为:“Never”(0)<“rare”(1)<“Most days”(2)<“Every day”(3)。
在本例中,这个假设是有意义的,因为对类别有一个无可争议的排名。并不是所有的分类变量在值中都有一个明确的顺序,但是我们将那些有顺序的变量称为有序变量。对于基于树的模型(如决策树和随机森林),可以期望标签编码能够很好地处理有序变量。
3) One-Hot 编码
One-Hot 编码创建新列,指示原始数据中每个可能值的存在(或不存在)。为了理解这一点,我们将通过一个示例进行介绍。
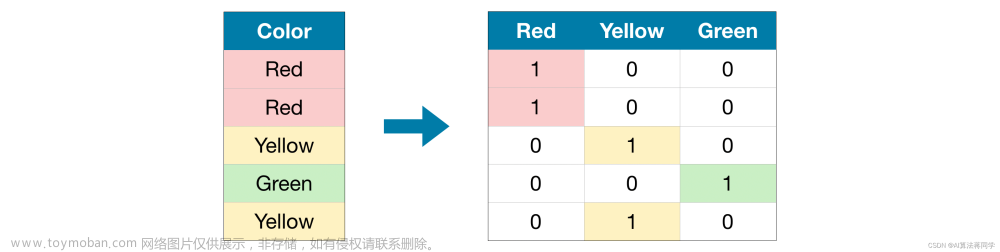
在原始数据集中,“Color”是一个类别变量,有三个类别:“Red”、“Yellow” 和 “Green”。
对应的独热编码包含每个可能值的一列,以及原始数据集中每行的一行。当原值为“Red”时,我们在“Red”列中加1;如果原值为“Yellow”,我们在“Yellow”列中加1,依此类推。与有序编码不同,一个One-Hot不假定类别的顺序。
与有序编码不同,一个One-Hot不假定类别的顺序。
因此,如果分类数据中没有明确的顺序(例如,“Red”既不大于也不小于“Yellow”),可以预期这种方法特别有效。我们把没有内在排序的分类变量称为名义变量。
如果类别变量具有大量值(即,通常不会将其用于超过15个不同值的变量),独热编码通常在分类变量取大量值时表现不佳。
3、举例
在前一个教程中,我们将使用墨尔本住房数据集。
我们将不关注数据加载步骤。相反,您可以想象您已经拥有了 X _ train、 X _ valid、 y _ train 和 y _ valid中的训练和验证数据。文章来源:https://www.toymoban.com/news/detail-810939.html
In [1]:文章来源地址https://www.toymoban.com/news/detail-810939.html
import pandas as pd
from sklearn.model_selection import train_test_split
#读取数据
data = pd.read_csv('E:/data_handle/melb_data.csv')
#从预测器中分离目标
y =data.Price
X = data.drop(['Price'],axis=1)
#将数据划分为训练和验证子集
X_train_full, X_valid_full, y_train, y_valid = train_test_split(X, y, train_size=0.8,test_size=0.2,random_state=0到了这里,关于3、非数值型的分类变量的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!