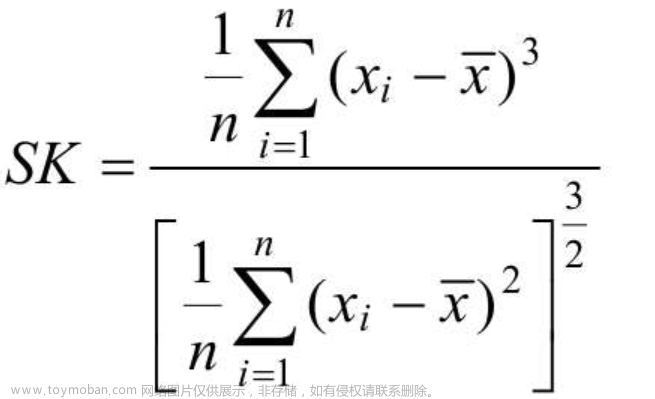简述 / 前言
前面讲了数据分析中的第一步:数据预处理,下面就是数据分析的其中一个重头戏:描述性统计,具体内容为:平均数(均值)、方差、标准差、极大值、极小值、中位数、百分位数、用箱型图表示分位数。
1. 平均数(均值)、方差、标准差、极大值、极小值
| 关键方法 | 含义 |
|---|---|
.mean() |
求均值 |
.var() |
求方差 |
.std() |
求标准差 |
.max() |
求极大值 |
.min() |
求极小值 |
示例:
import pandas as pd
import numpy as np
import math
np.random.seed(2024)
df = pd.DataFrame(columns=['num']) # 构造原始数据文件
df['num'] = [np.random.ranf() * 10 for i in range(10)]
print(df, '\n')
# num列的平均值
print(f"列num的平均值(均值)为:{df['num'].mean()}")
# num列的方差
print(f"列num的方差为:{df['num'].var()}")
# num列的标准差(方法一)
print(f"列num的标准差(方法一)为:{df['num'].std()}")
# num列的标准差(方法二)
print(f"列num的标准差(方法二)为:{math.sqrt(df['num'].var())}")
# num列的极大值
print(f"列num的极大值为:{df['num'].max()}")
# num列的极小值
print(f"列num的极小值为:{df['num'].min()}")
输出:
num
0 5.880145
1 6.991087
2 1.881520
3 0.438086
4 2.050190
5 1.060629
6 7.272401
7 6.794005
8 4.738457
9 4.482958
列num的平均值为:4.158947812331025
列num的方差为:6.793267492129306
列num的标准差(方法一)为:2.6063897429450775
列num的标准差(方法二)为:2.6063897429450775
列num的极大值为:7.2724014368445475
列num的极小值为:0.43808563746864815
2. 中位数
关键方法:.median()
示例:
import pandas as pd
import numpy as np
np.random.seed(2024)
df = pd.DataFrame(columns=['num']) # 构造原始数据文件
df['num'] = [np.random.ranf() * 10 for i in range(10)]
print(df, '\n')
# num列的中位数
print(f"列num的中位数为:{df['num'].median()}")
输出:
num
0 5.880145
1 6.991087
2 1.881520
3 0.438086
4 2.050190
5 1.060629
6 7.272401
7 6.794005
8 4.738457
9 4.482958
列num的中位数为:4.610707639442616
3. 百分位数
关键方法:.quantile(q=0.5, interpolation="linear"),各参数含义如下:
| 参数 | 含义 |
|---|---|
| q | 要计算的分位数,取值范围为:[0, 1],常取:0.25, 0.5(默认值), 0.75
|
| interpolation | 插值类型,可以选:linear(默认值), lower, higher, midpoint, nearest
|
示例:
import pandas as pd
import numpy as np
np.random.seed(2024)
df = pd.DataFrame(columns=['num']) # 构造原始数据文件
df['num'] = [np.random.ranf() * 10 for i in range(10)]
print(df, '\n')
# num列的下分位数(25%)
print(f"列num的下分位数(25%)为:{df['num'].quantile(0.25)}")
# num列的中位数(50%)
print(f"列num的中位数(50%)为:{df['num'].quantile(0.50)}")
# num列的上分位数(75%)
print(f"列num的上分位数(75%)为:{df['num'].quantile(0.75)}")
# 或者
print(f"\n列num的分位数(25%、50%、75%)为:\n{df['num'].quantile([.25, .5, .75])}")
输出:
num
0 5.880145
1 6.991087
2 1.881520
3 0.438086
4 2.050190
5 1.060629
6 7.272401
7 6.794005
8 4.738457
9 4.482958
列num的下分位数(25%)为:1.9236870812745168
列num的中位数(50%)为:4.610707639442616
列num的上分位数(75%)为:6.565540223677057
列num的分位数(25%、50%、75%)为:
0.25 1.923687
0.50 4.610708
0.75 6.565540
Name: num, dtype: float64
4. 用箱型图表示分位数
关键方法:df['column']..plot.box()
一般写法:df['column'].plot.box(patch_artist=True, notch=True, color=color, figsize=(8, 6)),各参数含义如下:
| 参数 | 含义 |
|---|---|
| patch_artist | 箱型图是否需要填充颜色(True:填充颜色;False:不填充颜色,只保留边缘颜色) |
| notch | 是否用凹进的方式显示中位数(50%)(True:中位数用凹进的方式表示;False:中位数用一条线段表示) |
| color | 箱型图的颜色 |
| figsize | 图片大小 |
示例【patch_artist 和 notch 都为 True】:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(2024)
df = pd.DataFrame(columns=['num']) # 构造原始数据文件
df['num'] = [np.random.ranf() * 10 for i in range(10)]
df['num'].plot.box(patch_artist=True, notch=True, color='green', figsize=(8, 6)) # 绘制箱状图
plt.show()
输出:
示例【patch_artist 和 notch 都为 False】:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(2024)
df = pd.DataFrame(columns=['num']) # 构造原始数据文件
df['num'] = [np.random.ranf() * 10 for i in range(10)]
df['num'].plot.box(patch_artist=False, notch=False, color='green', figsize=(8, 6)) # 绘制箱状图
plt.show()
输出:
从这个箱型图可以很清晰的看出样本数据的极小值和极大值,以及上分位数(75%),中位数(50%)和下分位数(25%)。
除了上面那种写法,还有下面这种写法:df.plot.box(column=column, patch_artist=True, notch=True, color=color, figsize=(8, 6)),就是把 column 放到 box 方法里面。
那么上述代码可以改为:文章来源:https://www.toymoban.com/news/detail-811037.html
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(2024)
df = pd.DataFrame(columns=['num']) # 构造原始数据文件
df['num'] = [np.random.ranf() * 10 for i in range(10)]
# df['num'].plot.box(patch_artist=False, notch=False, color='green', figsize=(8, 6)) # 绘制箱状图
# 或者
df.plot.box(column='num', patch_artist=False, notch=False, color='green', figsize=(8, 6)) # 绘制箱状图
plt.show()
输出的结果是一样的~文章来源地址https://www.toymoban.com/news/detail-811037.html
到了这里,关于【Python 数据分析】描述性统计:平均数(均值)、方差、标准差、极大值、极小值、中位数、百分位数、用箱型图表示分位数的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!