一、首先安装VMware虚拟机
虚拟机安装包以及Ubuntu ISO映像下载:https://pan.baidu.com/s/19Ai5K-AA4NZHpfMcCs3D8w?pwd=9999
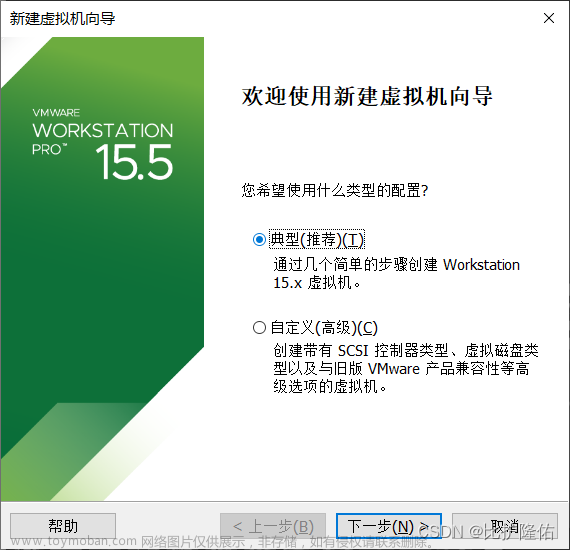
下载完成后,进入VMware,点击右上角【文件】——【新建虚拟机向导】
1.1选择典型
1.2选择光盘映像
映像文件选择上方刚刚下载的ubuntukylin-16.04-desktop-amd64

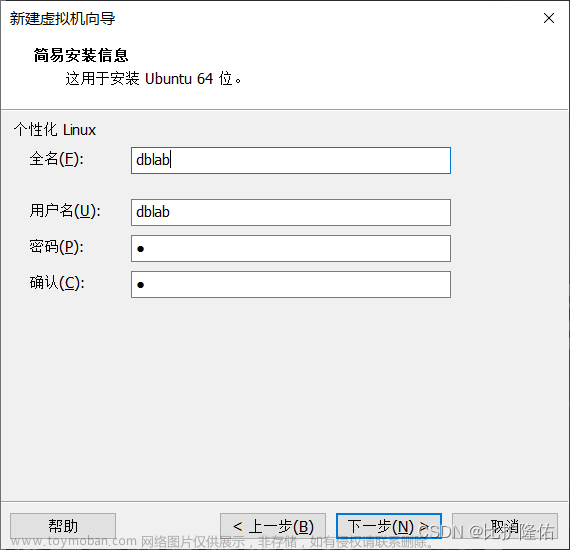
1.3命名
根据自己需求来,无统一规定
1.4安装位置

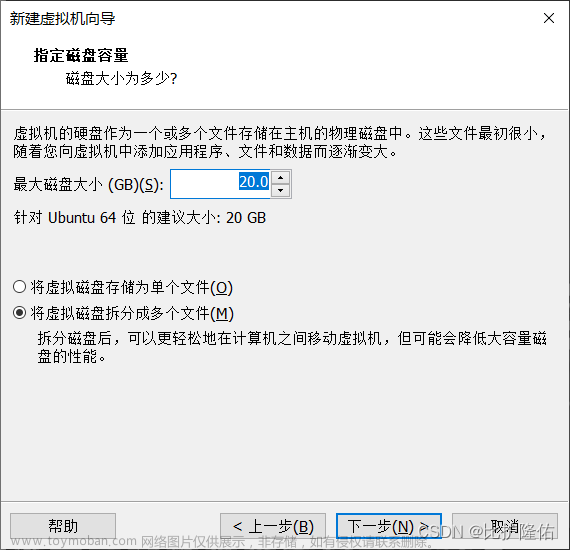
1.5设置磁盘容量
一般为20GB即可
点击下一步,再点击完成,虚拟机就创建完毕了。
二、创建Hadoop用户
2.1运行虚拟机
默认情况下,创建完虚拟机会自动启动,也可以在主页点击绿色启动按钮
第一次启动需要耐心等待安装
点击我们创建的用户登录

如果安装 Ubuntu 的时候不是用的 “hadoop” 用户,那么需要增加一个名为 hadoop 的用户。
首先按 ctrl+alt+t 打开终端窗口,输入如下命令创建新用户 :
(可以直接把命令粘贴过去,右击的Paste是粘贴键,如果Paste键是灰色的话,关机再重启虚拟机就好了)
sudo useradd -m hadoop -s /bin/bash上面这条命令创建了可以登陆的 hadoop 用户,并使用 /bin/bash 作为 shell,该命令会让你输入登录密码来验证操作身份,输入密码后按回车就可以(密码输入后是不可见的)

接着使用如下命令设置Hadoop用户的密码,简单设置就好,按提示输入两次密码:
sudo passwd hadoop可为 hadoop 用户增加管理员权限,方便部署,避免一些对新手来说比较棘手的权限问题:
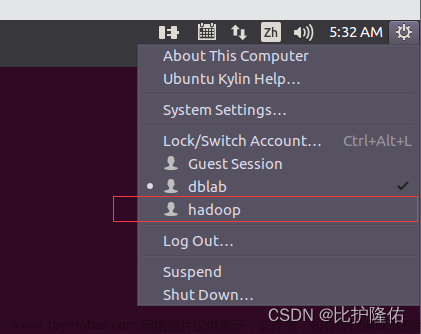
sudo adduser hadoop sudo完成后我们可以在右上角点击小齿轮,切换到hadoop用户
三、SSH登录权限设置
安装ssh的服务端:
sudo apt-get install openssh-server根据提示,输入y进行安装

四、安装Java环境
4.1安装并解压Java jdk
首先下载Java jdk,链接:https://pan.baidu.com/s/1JKwJEAnYpNDN2hZ5JpPMVw?pwd=9999
为了方便传输文件,我们需要用到FileZilla,FileZilla下载链接:https://pan.baidu.com/s/1DFFt-PWFBBY9Obm_Zv_24g?pwd=9999
下载后双击运行安装,安装完成后运行FileZilla
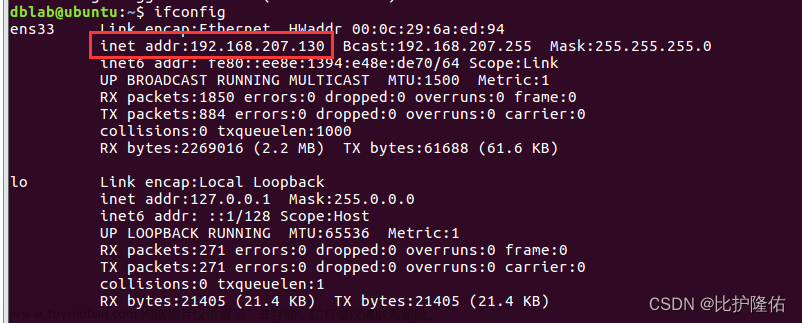
先回到虚拟机,输入ifconfig查看本机虚拟机的ip
红色圈出来的就是ip地址了,记一下方便后续使用
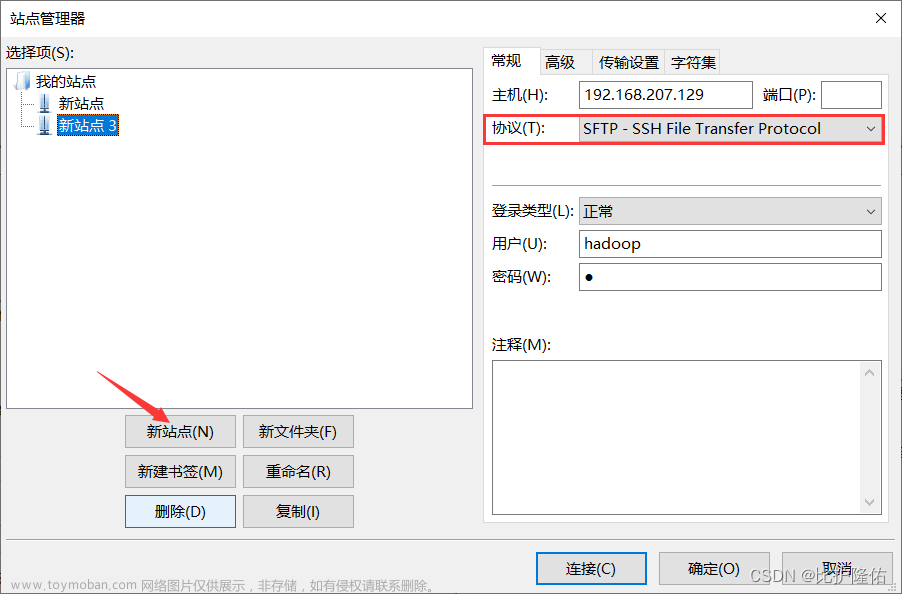
接下来回到FileZilla,点击左上角【文件】——【站点管理器】
点击下方【新站点】,右侧主机输入刚刚查询到的虚拟机ip,协议选择SFTP,登录类型正常。
用户名hadoop,密码是虚拟机用户hadoop的密码
检查输入无误后,点击右下方【连接】
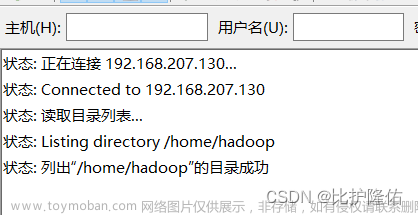
勾选信任,点确认

左上角显示如下就代表连接成功了
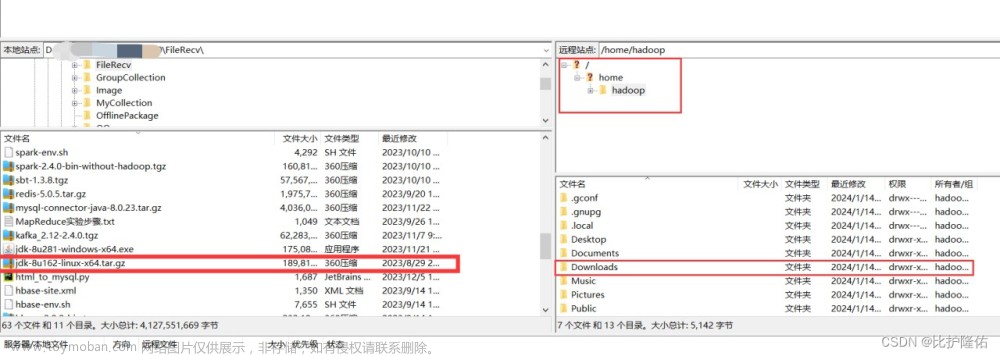
接下来把我们刚刚下载的Java jdk-8u162-linux-x64.tar.gz通过FileZilla传输到虚拟机 /home/hadoop/Downlods/ 路径下面
简单来说FileZilla的用法就是左侧是你自己的电脑,在左侧找到存放你下载的Java jdk位置,然后在右侧找到/home/hadoop/Downlods/(没找到的话把FileZilla关了重新再连接试试)
鼠标点住左侧的jdk文件不要动,拖动到右侧Downlods里,即可完成文件的传输。
传输完成后回到虚拟机中,输入命令如下:
cd /usr/lib
sudo mkdir jvm #创建/usr/lib/jvm目录用来存放JDK文件
cd ~ #进入hadoop用户的主目录
cd Downloads #注意区分大小写字母,刚才已经通过FTP软件把JDK安装包jdk-8u162-linux-x64.tar.gz上传到该目录下
sudo tar -zxvf ./jdk-8u162-linux-x64.tar.gz -C /usr/lib/jvm #把JDK文件解压到/usr/lib/jvm目录下
如下图代表解压完毕

4.2配置环境变量
配置环境变量为了方便也用到了FileZilla(也可以用vim编辑器),这里我用的FileZilla。
首先依然是打开FileZilla,然后像刚刚一样,与站点建立连接,确保连接正常。
接下来在右侧文件目录中找到.bashrc文件
找到后像刚刚一样,鼠标单击选中,拖拽到左侧(左侧路径最好是桌面,方便找到)

拖到桌面上我们双击就可以对.bashrc文件进行编辑,复制下方代码粘贴到.bashrc文件中(粘贴到任意空白位置都可以,注意别误删了其他代码)
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_162
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH

改好后记得保存,点击左上角【文件】——【保存】
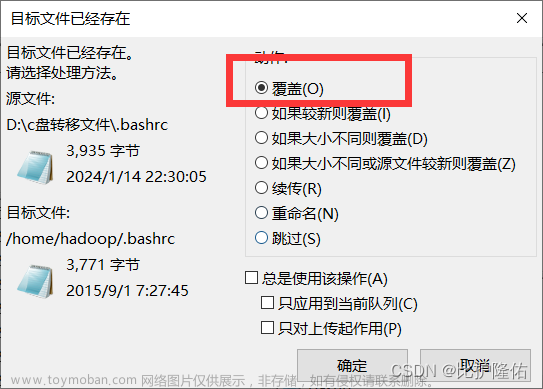
保存完毕后,打开FileZilla,我们需要用新修改完的.bashrc替换虚拟机中原有的.bashrc文件
在左侧单击选择刚刚修改好的.bashrc,将它移动到右侧刚刚的路径(/home/hadoop下面),此时会出现弹窗,我们选择【覆盖】,点击确定,这样环境变量就配置好了
回到虚拟机中,输入命令如下
source ~/.bashrc #让.bashrc文件的配置立即生效
五、单机安装配置
首先需要下载hadoop 3,链接:https://pan.baidu.com/s/1b36jbPa4-S3aFMjd7V1zpw?pwd=9999
打开FileZilla,将下载好的hadoop上传到虚拟机。(路径跟刚刚Java jdk的一样)

回到虚拟机中执行如下命令:
cd /home/hadoop/Downloads
sudo tar -zxf ./hadoop-3.1.3.tar.gz -C /usr/local # 解压到/usr/local中
cd /usr/local/
sudo mv ./hadoop-3.1.3/ ./hadoop # 将文件夹名改为hadoop
sudo chown -R hadoop:hadoop ./hadoop # 修改文件权限
安装完成
六、伪分布式安装配置
伪分布式安装需要修改配置文件,仍然是用filezilla把下面2个文件下载到本地进行修改,经过上面的操作相信大家对于使用FileZilla传文件都很熟练了。
分别需要修改/usr/local/hadoop/etc/hadoop/core-site.xml文件和
/usr/local/hadoop/etc/hadoop/hdfs-site.xml文件
注意我们的文件路径/usr/local/hadoop/etc/hadoop(实在找不到文件的位置可以复制路径到远程站点那个输入框按回车)
把这两个文件都拖拽到桌面上来,方便修改

这两个文件的打开方式都选择【用记事本打开】
将core-site.xml在<configuration>和</configuration>中增加以下内容:
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>

改完别忘点击保存。
将hdfs-site.xml在<configuration>和</configuration>中增加以下内容:
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>改完别忘点击保存。
然后用FileZilla将这两个改好后的文件传回到虚拟机中(注意路径),同样是选择覆盖之前的。
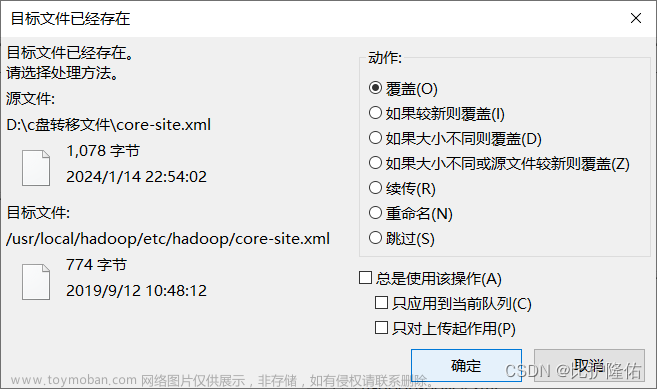
接下来配置ssh无密码登录,在虚拟机中输入以下命令:
ssh localhost #输入yes
exit
cd ~/.ssh/
ssh-keygen -t rsa #敲3次回车
cat ./id_rsa.pub >>./authorized_keys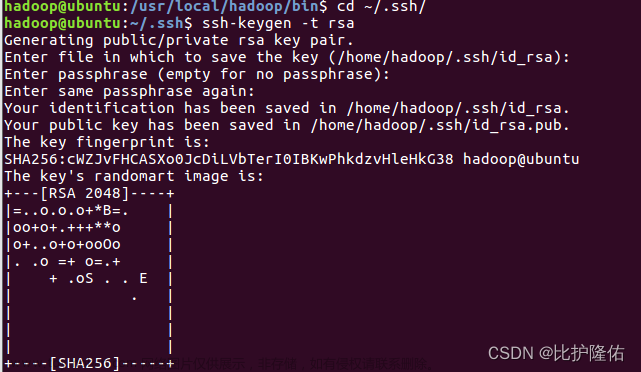
修改hadoop的配置文件 /usr/local/hadoop/etc/hadoop/hadoop_env.sh
用FileZilla把hadoop_env.sh文件传到桌面上,用记事本方式打开,找到下面这行
# JAVA_HOME=/usr/java/testing hdfs dfs -ls
把# JAVA_HOME=后面的内容修改为/usr/lib/jvm/jdk1.8.0_162
保存

修改完后用FileZilla传回虚拟机,仍然是选择覆盖。

传输完毕之后,执行命令初始化文件系统
cd /usr/local/hadoop/bin
./bin/hdfs namenode -format然后启动所有进程
cd /usr/local/hadoop/sbin
start-all.sh
start-dfs.sh #启动文件系统
此时,可以在虚拟机中访问 Web 页面(http://localhost:9870)来查看 Hadoop 的信息文章来源:https://www.toymoban.com/news/detail-811150.html
若想停止hdfs可输入以下命令:文章来源地址https://www.toymoban.com/news/detail-811150.html
cd /usr/local/hadoop
./sbin/stop-dfs.sh到了这里,关于超详细版Hadoop的安装与使用(单机/伪分布式)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!