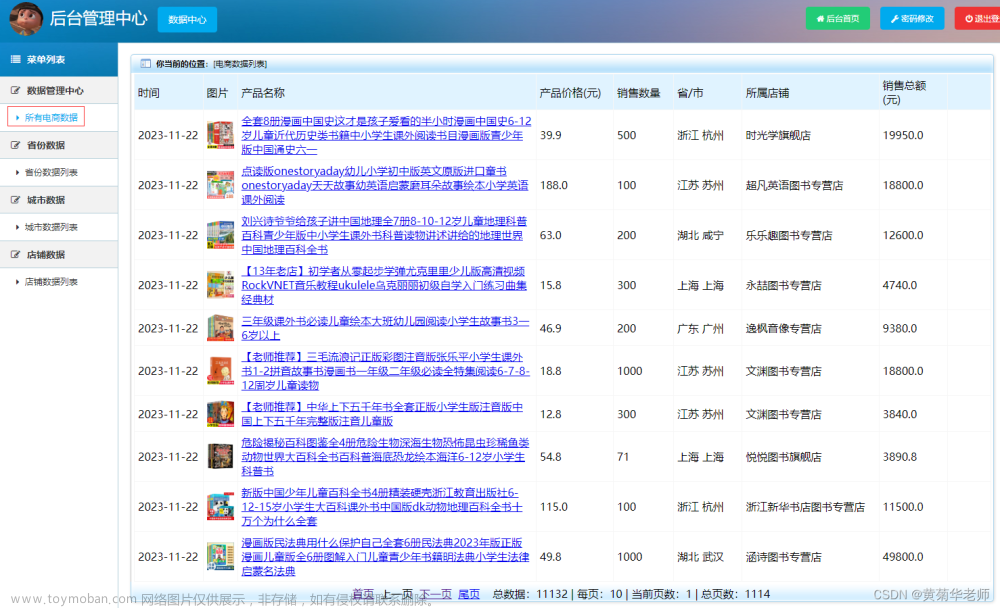
最近需要查阅一些资料,只给到相关项目名称以及关键词,想通过图书文库找到对应书籍,那么怎么才能在百万数据库中找到自己需要的文献呢?
今天我依然用C语言写个爬虫程序,从百万数据库中查找到适合的文章,能节省很多事情。

下面是一个简单的C#爬虫程序,它使用了HttpWebRequest和HttpWebResponse来发送和接收HTTP请求。这个程序爬取的是一个图书网站的信息,但是因为没有提供具体的网址和需要爬取的信息,所以我只能给出一个通用的爬虫结构。你需要根据你的实际需求来修改这个程序。
using System;
using System.Net;
using System.IO;
using System.Text;
class Program
{
static void Main(string[] args)
{
// 设置代理
WebRequest proxy = WebRequest.Create("duoip:8000");
WebRequest proxy = jshk.com.cn/mb/reg.asp?kefu=xjy&csdn
proxy.Proxy = new WebProxy();
proxy.Proxy.Credentials = null;
// 发送请求
WebRequest request = WebRequest.Create("http://www.example.com");
request.UseDefaultCredentials = true;
request.Proxy = proxy;
WebResponse response = request.GetResponse();
// 读取响应内容
Stream responseStream = response.GetResponseStream();
StreamReader reader = new StreamReader(responseStream, Encoding.UTF8);
string html = reader.ReadToEnd();
// 输出爬取到的内容
Console.WriteLine(html);
// 关闭流
reader.Close();
responseStream.Close();
response.Close();
// 程序结束
Console.ReadLine();
}
}
代码解释:
1、首先,我们需要设置代理。在这个例子中,我们使用的是duoip.cn的代理服务器,端口是8000。我们创建一个WebRequest对象,然后设置它的Proxy属性为一个WebProxy对象。WebProxy对象的Credentials属性是null,表示我们不使用任何用户名和密码进行认证。
2、接下来,我们发送请求。我们创建一个WebRequest对象,然后设置它的UseDefaultCredentials属性为true,表示我们使用的是默认的用户名和密码。然后我们设置它的Proxy属性为上面设置的Proxy对象。
3、然后,我们获取响应。我们调用WebRequest对象的GetResponse方法,它会返回一个WebResponse对象。
4、接下来,我们读取响应内容。我们首先获取ResponseStream,然后创建一个StreamReader对象,使用UTF8编码读取ResponseStream的内容,然后将内容保存到一个字符串变量中。
5、最后,我们输出爬取到的内容,然后关闭流,最后等待用户输入,结束程序。
注意:这个程序只是一个基本的爬虫框架,你需要根据你的实际需求来修改它。例如,你可能需要处理更复杂的HTTP请求,或者需要处理更复杂的响应内容。你也需要注意代理服务器的使用限制,不要滥用代理服务器,否则可能会被封禁。文章来源:https://www.toymoban.com/news/detail-811154.html
上面就是我编写的全部爬虫内容,只要了解网站规则,防止触发反爬虫机制,基本就是坐等数据归类。如果大家有更多的爬虫相关的问题,可以这里留言一起讨论。文章来源地址https://www.toymoban.com/news/detail-811154.html
到了这里,关于C语言爬虫采集图书网站百万数据的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!