第五部分、数组和广义表详解

数组和广义表,都用于存储逻辑关系为“一对一”的数据。
数组存储结构,99% 的编程语言都包含的存储结构,用于存储不可再分的单一数据;而广义表不同,它还可以存储子广义表。
本章重点从矩阵的角度讨论二维数组的存储,同时讲解广义表的存储结构以及有关其广度和深度的算法实现。
五、行逻辑链接的顺序表(压缩存储稀疏矩阵)详解
前面学习了如何使用三元组顺序表存储稀疏矩阵,其实现过程就是将矩阵中各个非 0 元素的行标、列标和元素值以三元组的形式存储到一维数组中。通过研究实现代码你会发现,三元组顺序表每次提取指定元素都需要遍历整个数组,运行效率很低。
本节将学习另一种存储矩阵的方法——行逻辑链接的顺序表。它可以看作是三元组顺序表的升级版,即在三元组顺序表的基础上改善了提取数据的效率。
行逻辑链接的顺序表和三元组顺序表的实现过程类似,它们存储矩阵的过程完全相同,都是将矩阵中非 0 元素的三元组(行标、列标和元素值)存储在一维数组中。但为了提高提取数据的效率,前者在存储矩阵时比后者多使用了一个数组,专门记录矩阵中每行第一个非 0 元素在一维数组中的位置。

图 1 稀疏矩阵示意图
图 1 是一个稀疏矩阵,当使用行逻辑链接的顺序表对其进行压缩存储时,需要做以下两个工作:
- 将矩阵中的非 0 元素采用三元组的形式存储到一维数组 data 中,如图 2 所示(和三元组顺序表一样):

图 2 三元组存储稀疏矩阵
-
使用数组 rpos 记录矩阵中每行第一个非 0 元素在一维数组中的存储位置。如图 3 所示:

图 3 存储各行首个非 0 元素在数组中的位置
通过以上两步操作,即实现了使用行逻辑链接的顺序表存储稀疏矩阵。
此时,如果想从行逻辑链接的顺序表中提取元素,则可以借助 rpos 数组提高遍历数组的效率。
例如,提取图 1 稀疏矩阵中的元素 2 的过程如下:
- 由 rpos 数组可知,第一行首个非 0 元素位于data[1],因此在遍历此行时,可以直接从第 data[1] 的位置开始,一直遍历到下一行首个非 0 元素所在的位置(data[3])之前;
- 同样遍历第二行时,由 rpos 数组可知,此行首个非 0 元素位于 data[3],因此可以直接从第 data[3] 开始,一直遍历到下一行首个非 0 元素所在的位置(data[4])之前;
- 遍历第三行时,由 rpos 数组可知,此行首个非 0 元素位于 data[4],由于这是矩阵的最后一行,因此一直遍历到 rpos 数组结束即可(也就是 data[tu],tu 指的是矩阵非 0 元素的总个数)。
以上操作的完整 C 语言实现代码如下:
#include <stdio.h>
#define MAXSIZE 12500
#define MAXRC 100
#define ElemType int
typedef struct
{
int i,j;//行,列
ElemType e;//元素值
}Triple;
typedef struct
{
Triple data[MAXSIZE+1];
int rpos[MAXRC+1];//每行第一个非零元素在data数组中的位置
int mu,nu,tu;//行数,列数,元素个数
}RLSMatrix; /
/矩阵的输出函数
void display(RLSMatrix M){
for(int i=1;i<=M.mu;i++){
for(int j=1;j<=M.nu;j++){
int value=0;
if(i+1 <=M.mu){
for(int k=M.rpos[i];k<M.rpos[i+1];k++){
if(i == M.data[k].i && j == M.data[k].j){
printf("%d ",M.data[k].e);
value=1;
break;
}
}
if(value==0){
printf("0 ");
}
}else{
for(int k=M.rpos[i];k<=M.tu;k++){
if(i == M.data[k].i && j == M.data[k].j){
printf("%d ",M.data[k].e);
value=1;
break;
}
}
if(value==0){
printf("0 ");
}
}
}
printf("\n");
}
}
int main(int argc, char* argv[])
{
RLSMatrix M;
M.tu = 4;
M.mu = 3;
M.nu = 4;
M.rpos[1] = 1;
M.rpos[2] = 3;
M.rpos[3] = 4;
M.data[1].e = 3;
M.data[1].i = 1;
M.data[1].j = 2;
M.data[2].e = 5;
M.data[2].i = 1;
M.data[2].j = 4;
M.data[3].e = 1;
M.data[3].i = 2;
M.data[3].j = 3;
M.data[4].e = 2;
M.data[4].i = 3;
M.data[4].j = 1;
//输出矩阵
display(M);
return 0;
}
运行结果:文章来源:https://www.toymoban.com/news/detail-811253.html
0 3 0 5
0 0 1 0
2 0 0 0
总结
通过系统地学习使用行逻辑链接的顺序表压缩存储稀疏矩阵,可以发现,它仅比三元组顺序表多使用了一个 rpos 数组,从而提高了提取数据时遍历数组的效率。
六、十字链表法,十字链表压缩存储稀疏矩阵详解
对于压缩存储稀疏矩阵,无论是使用三元组顺序表,还是使用行逻辑链接的顺序表,归根结底是使用数组存储稀疏矩阵。介于数组 "不利于插入和删除数据" 的特点,以上两种压缩存储方式都不适合解决类似 "向矩阵中添加或删除非 0 元素" 的问题。
例如,A 和 B 分别为两个矩阵,在实现 "将矩阵 B 加到矩阵 A 上" 的操作时,矩阵 A 中的元素会发生很大的变化,之前的非 0 元素可能变为 0,而 0 元素也可能变为非 0 元素。对于此操作的实现,之前所学的压缩存储方法就显得力不从心。
本节将学习用十字链表存储稀疏矩阵,该存储方式采用的是 "链表+数组" 结构,如图 1 所示。
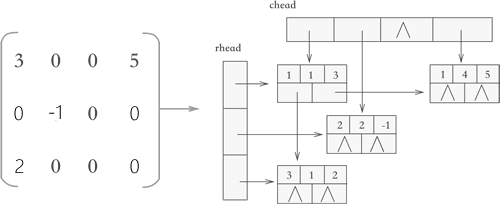
图 1 十字链表示意图
可以看到,使用十字链表压缩存储稀疏矩阵时,矩阵中的各行各列都各用一各链表存储,与此同时,所有行链表的表头存储到一个数组(rhead),所有列链表的表头存储到另一个数组(chead)中。
因此,各个链表中节点的结构应如图 2 所示:

图 2 十字链表的节点结构
两个指针域分别用于链接所在行的下一个元素以及所在列的下一个元素。
链表中节点的 C 语言代码表示应为:
typedef struct OLNode{
int i,j;//元素的行标和列标
int data;//元素的值
struct OLNode * right,*down;//两个指针域
}OLNode;
同时,表示十字链表结构的 C 语言代码应为:
#include<stdio.h>
#include<stdlib.h>
typedef struct OLNode
{
int i, j, e; //矩阵三元组i代表行 j代表列 e代表当前位置的数据
struct OLNode *right, *down; //指针域 右指针 下指针
}OLNode, *OLink;
typedef struct {
OLink *rhead, *chead; //行和列链表头指针
int mu, nu, tu; //矩阵的行数,列数和非零元的个数
}CrossList;
CrossList CreateMatrix_OL(CrossList M);
void display(CrossList M);
int main() {
CrossList M;
M.rhead = NULL;
M.chead = NULL;
M = CreateMatrix_OL(M);
printf("输出矩阵M:\n");
display(M);
return 0;
}
CrossList CreateMatrix_OL(CrossList M)
{
int m, n, t;
int i, j, e;
OLNode *p, *q;
printf("输入矩阵的行数、列数和非0元素个数:");
scanf("%d%d%d", &m, &n, &t);
M.mu = m;
M.nu = n;
M.tu = t;
if (!(M.rhead = (OLink*)malloc((m + 1) * sizeof(OLink))) || !(M.chead = (OLink*)malloc((n + 1) * sizeof(OLink))))
{
printf("初始化矩阵失败");
exit(0);
}
for (i = 1; i <= m; i++)
{
M.rhead[i] = NULL;
}
for (j = 1; j <= n; j++)
{
M.chead[j] = NULL;
}
for (scanf("%d%d%d", &i, &j, &e); 0 != i; scanf("%d%d%d", &i, &j, &e)) {
if (!(p = (OLNode*)malloc(sizeof(OLNode))))
{
printf("初始化三元组失败");
exit(0);
}
p->i = i;
p->j = j;
p->e = e;
//链接到行的指定位置
if (NULL == M.rhead[i] || M.rhead[i]->j > j)
{
p->right = M.rhead[i];
M.rhead[i] = p;
}
else
{
for (q = M.rhead[i]; (q->right) && q->right->j < j; q = q->right);
p->right = q->right;
q->right = p;
}
//链接到列的指定位置
if (NULL == M.chead[j] || M.chead[j]->i > i)
{
p->down = M.chead[j];
M.chead[j] = p;
}
else
{
for (q = M.chead[j]; (q->down) && q->down->i < i; q = q->down);
p->down = q->down;
q->down = p;
}
}
return M;
}
void display(CrossList M) {
for (int i = 1; i <= M.nu; i++)
{
if (NULL != M.chead[i])
{
OLink p = M.chead[i];
while (NULL != p)
{
printf("%d\t%d\t%d\n", p->i, p->j, p->e);
p = p->down;
}
}
}
}
运行结果:
输入矩阵的行数、列数和非0元素个数:3 3 3
2 2 3
2 3 4
3 2 5
0 0 0
输出矩阵M:
2 2 3
3 2 5
2 3 4文章来源地址https://www.toymoban.com/news/detail-811253.html
到了这里,关于数据结构与算法教程,数据结构C语言版教程!(第五部分、数组和广义表详解)三的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!