羊驼系列大模型:大模型的安卓系统
GPT系列:类比ios系统,不开源
LLaMa让大模型平民化
LLaMa优势
用到的数据:大部分英语、西班牙语,少中文

模型下载地址
https://huggingface.co/meta-llama

Alpaca模型
Alpaca是斯坦福从Meta的LLaMA 7B微调而来的全新模型 (套壳)仅用了52k数据,性能约等于GPT-3.5。
训练成本奇低,总成本不到600美元
- 在8个80GB A100上训练了3个小时,不到100美元;
- 生成数据使用OpenAl的AP1,500美元。(数据标注: 问题问chatgpt,用它的回答作为标注数据)
Alpaca模型的训练

Vicuna模型
Vicuna简介

具体工作流程
用GPT4做评估,用更厉害的大模型做大模型

ChatGPT没找到合适的盈利模式
诸驼对比

华驼模型

百川大模型
LLaMa+中文数据
LLaMa2.0


具备人的情商

国内大模型清华6B(中英文数据各一半)、百度文心一言是原创,其它的套壳。
找大模型工作不要找研究型工作,而要找将大模型落地的工作。文章来源:https://www.toymoban.com/news/detail-811467.html
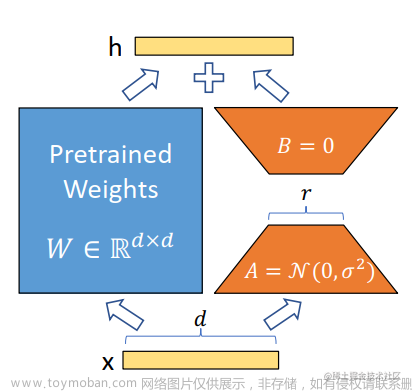
微调的本质
- 原生llama用的通用语料
- 在自己的数据上进行微调,让模型能够满足自己的需求
羊驼系列的共性
 文章来源地址https://www.toymoban.com/news/detail-811467.html
文章来源地址https://www.toymoban.com/news/detail-811467.html
到了这里,关于羊驼系列大模型LLaMa、Alpaca、Vicuna的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!


![[大模型] LLaMA系列大模型调研与整理-llama/alpaca/lora(部分)](https://imgs.yssmx.com/Uploads/2024/02/473799-1.png)