写在开头
在探索数据管理的世界中,理解如何在数据库中使用事务处理,无疑是一项关键的能力。在处理复杂的数据库操作,尤其是在你试图在多个表或数据库中更新数据时,事务可以确保这些更改具有原子性、一致性、隔离性和持久性,即ACID。因此,掌握事务对任何数据库专业人员来说都是必不可少的。
1. 事务的基本概念
定义事务(Transaction)是数据库管理系统进行处理的一个程序执行单位。一般来说,一个事务从BEGIN TRANSACTION语句开始,经过一组DML(如INSERT、UPDATE、DELETE)或DDL(如CREATE、ALTER、DROP等)的SQL操作,然后以COMMIT或ROLLBACK语句结束。这是最简单、最典型的事务开始和结束的方式。
1.1 了解事务的ACID属性
事务的重要性在于它们满足了许多企业级应用所需的四大特性,即ACID:
-
原子性(Atomicity): 原子性确保操作要么全都进行,要么全都不进行。换句话说,如果一个事务涉及到多个步骤(比如向两个不同的表插入数据),那么要么所有步骤都成功,要么整个事务回滚,保持数据的一致性。
-
一致性(Consistency): 事务开始之前和结束之后,数据库的完整性必须得到维护。也就是说,事务必须使数据库从一个一致状态转移到另一个一致状态。例如,如果一个事务涉及到转账操作,无论事务是否成功,转出和转入账户的总金额都应保持一致。
-
隔离性(Isolation): 隔离性保证并发运行的事务的变更是隔离的,也就是发生在隔离级别下的并发事务,它们各自的修改对其他并发运行的事务是不可见的,除非事务提交。
-
持久性(Durability): 一旦事务提交,对数据库的更改就将被永久保持,即使系统有了故障,通过日志和数据库恢复机制仍能找回数据。
1.2 事务的起始与结束
事务开始是通过BEGIN TRANSACTION语句表示的。它告诉数据库管理系统(DBMS),我们即将开始一组作为单个工作单位进行的操作。一旦BEGIN TRANSACTION命令执行后,那么接下来的数据库操作将会在事务的保护下运行。
事务的结束可以有两种方式:
- COMMIT: 在所有的数据库操作都成功执行后,我们可以提交事务。这个操作实际告诉DBMS,操作是成功的,可以将数据持久化到磁盘上。一旦COMMIT命令被执行,事务结束,而且不能回滚。
- ROLLBACK: 如果在操作过程中出现了错误,或者用户执行了一个撤销操作,那么我们可以回滚事务。简单地说,ROLLBACK操作将数据库的状态恢复到BEGIN TRANSACTION之前。
2. 事务的隔离级别
2.1 不同的隔离级别比较
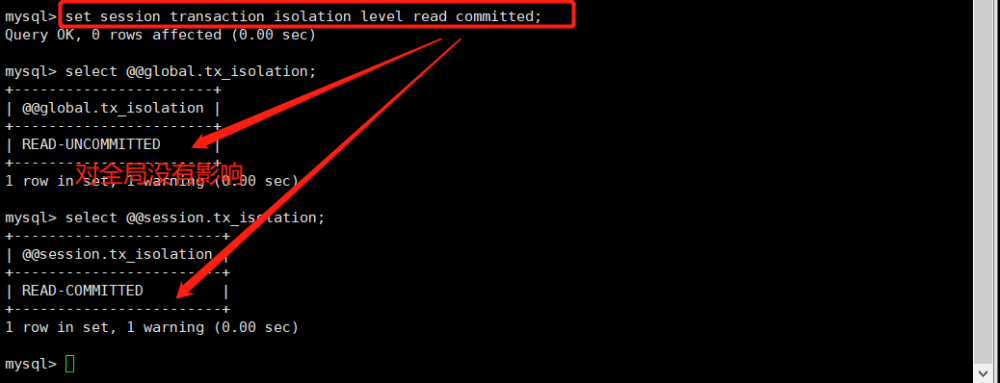
在MySQL中,事务隔离级别是一个核心概念,用来控制同时运行的交易如何“隔离”或与偶然影响彼此的问题。它可以定义为四个级别:
-
**读未提交(Read uncommitted):**这是最低的隔离级别,允许事务查看尚未提交的更改。在这个级别下,一个事务可以看到另一个事务未提交的结果,有可能导致“脏读”(Dirty Reads)问题。
-
**读提交(Read committed):**这是大多数数据库系统的默认隔离级别。MySQL官方文档建议的隔离级别。在这个级别下,一个事务只能看见已经提交的事务所做的更改,避免了“脏读”,但仍然可能发生“不可重复读”和“幻读”等问题。
-
**可重复读(Repeatable read):**这是MySQL的默认隔离级别。在一个事务内部,多次读取的结果是一致的,即使在此期间有其他事务进行了修改。它解决了“不可重复读”的问题,但可能导致“幻读”。
-
**串行化(Serializable):**所有并发事务都被转化为顺序运行。即,在同一时间内,只能有一个事务在运行,彻底杜绝了一切并发产生的问题,但是效率低下。
2.2 选择合适的隔离级别
在实际应用中,选择正确的隔离级别是至关重要的。如果需要确保数据库的绝对一致性,最好使用Serializable隔离级别,即使这可能牺牲了部分性能。但是在需要高并发、高吞吐率的应用场景下,比如高流量的Web应用,较低的隔离级别,如读提交,可能是更好的选择。
不仅如此,MySQL提供的InnoDB存储引擎通过实现多版本并发控制(MVCC)和Next-Key Lock等技术,可以在Repeatable read隔离级别下避免“脏读”、“不可重复读”和“幻读”问题,同时保持高并发性能。
设置隔离级别的语句很简单,如设置为 Serializable,只需执行以下语句:
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
3. 事务的异常处理
当我们在数据库中进行事务处理时,需要考虑可能出现的一切异常并准备好相应的解决方案。在MySQL中,我们有以下几种方式可以处理事务的异常。
3.1 事务中的异常处理机制
在MySQL中,处理事务中异常的基本策略是:如果发生了一个错误,那么当前正在进行的事务将会被终止并回滚。
假设你试图在一个事务中插入一个违反数据库完整性规则的数据,例如,试图插入一个已经存在的唯一键。在这种情况下,MySQL将会引发一个错误,并停止当前的事务。这种情况下,你可以选择让MySQL引发的错误传播到客户端,或者在应用程序中捕捉这个错误并进行恢复。
对于MySQL来说,一种有效的异常处理方法是使用声明式条件处理程序。你可以设置一个处理程序,让数据库捕捉特定的错误并执行一段代码。这可以用来记录错误,或者让事务回滚到一个安全的状态。
3.2 使用SAVEPOINT实现更灵活的事务控制
除了基本的COMMIT和ROLLBACK之外,MySQL还提供了一个用于更复杂事务控制的功能:SAVEPOINT。SAVEPOINT允许你在事务中标记一个点,你可以随时回滚到这个点,而不是必须回滚整个事务。
例如,假设你有一个用户注册过程,需要在几个表中插入数据。在这个过程中,你可以在每次插入数据之前设置一个SAVEPOINT。如果一次插入失败,你可以回滚到最近的SAVEPOINT,而不是取消整个注册过程。
使用SAVEPOINT的语法如下:
SAVEPOINT savepoint_name;
你可以通过ROLLBACK命令回滚到一个SAVEPOINT,语法如下:
ROLLBACK TO SAVEPOINT savepoint_name;
在多步骤的事务中,使用SAVEPOINT可以为你的错误处理机制提供更灵活的控制。当然,它也会增加一些复杂性,因此使用时需要小心。
3.3 处理事务异常的主要方式
3.3.1 错误处理
当事务过程中遇到错误,例如违反了数据的完整性约束(例如,重复的主键值),MySQL会停止事务并抛出一个错误。这个错误可以被应用程序捕获并处理,例如,提醒用户输入了无效的数据或一些别的处理方式。MySQL也提供了一种错误处理机制,称为声明式条件处理器(DECLARE CONDITION)。这是一种存储在数据库中的的错误处理程序,可以捕获和处理SQL错误。程序员可以定义一段处理异常事务的代码并存储在数据库中,当发生异常时自动调用并处理。
例如,你可以将特殊的错误代码关联到MySQL预定义的一个错误条件,然后为这个条件定义一个特定的处理程序,用于捕获异常并进行处理。
DECLARE CONTINUE HANDLER FOR SQLEXCEPTION
BEGIN
-- 当异常出现时,执行的代码
END;
重试事务:
在MySQL中,你可以在存储过程中包装事务处理代码,然后在发生错误时再次调用这个存储过程。以下是一个简单例子。
DELIMITER $$
CREATE PROCEDURE retryTransaction()
BEGIN
DECLARE retry INT DEFAULT 3;
DECLARE CONTINUE HANDLER FOR SQLEXCEPTION
BEGIN
SET retry= retry - 1;
IF retry > 0 THEN retryTransaction; END IF;
END;
START TRANSACTION;
-- Your SQL operations
COMMIT;
END$$
DELIMITER ;
CALL retryTransaction();
降级锁定:
降级锁定在MySQL的行级锁定中实现。可以通过锁定和解锁某些行来实现。
START TRANSACTION;
SELECT column FROM table FOR UPDATE; -- 获取写锁
-- 进行一些修改
SELECT column FROM table LOCK IN SHARE MODE; -- 降级为读锁
COMMIT;
使用容错系统:
这不是MySQL语句,而是在系统或硬件级别进行的。一种常见的容错技术是设置数据的RAID阵列。
使用更低的事务隔离级别:
在MySQL中,你可以使用SET TRANSACTION语句来设置事务的隔离级别。
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
START TRANSACTION;
-- Your SQL operations
COMMIT;
使用编译时和运行时检查:
-- 编译时检查
CREATE TABLE table1 (
id INT NOT NULL,
column1 VARCHAR(50) NOT NULL CHECK (LENGTH(column1) > 0)
);
-- 运行时检查
START TRANSACTION;
INSERT INTO table1 (id, column1) VALUES(NULL, ""); -- 这将引发一个错误
COMMIT;
3.3.2 错误恢复
当一个错误发生并被捕获后,MySQL事务可以选择回滚(ROLLBACK)。回滚操作会撤销事务中的全部或部分修改,将数据库返回到一致的、错误未发生之前的状态。如果在事务中定义了一个或多个保存点(SAVEPOINT),可以选择回滚到某个特定的保存点。
例如:
START TRANSACTION;
SAVEPOINT sp1;
-- 一些 SQL 语句
SAVEPOINT sp2;
-- 一些 SQL 语句
-- 发生错误,回滚到保存点 sp1
ROLLBACK TO SAVEPOINT sp1;
COMMIT; -- 提交事务
在这个例子中,如果发生错误,事务不会完全回滚,而是回滚到保存点sp1。这给了开发者在复杂事务中处理错误更多的灵活性。
3.4 触发器异常处理
在MySQL中,触发器作为数据库的存储程序,同样能使用声明式条件处理器(DECLARE CONDITION) 来处理发生的异常。而MySQL中的触发器错误处理主要有四个步骤:
声明错误:
使用 DECLARE CONDITION 语句声明一个特定的错误。例如,你可能希望捕捉主键冲突的错误,你可以声明一个错误 CONDITION。
DECLARE duplicate_key CONDITION FOR SQLSTATE '23000';
其中,“duplicate_key”是我们给这个错误条件自定义的名字,'23000’是SQL标准的状态代码,代表一个唯一性约束被违反。
声明处理器:
在确定了错误类型后,需要声明一个处理器来决定发生预期错误时采取的行动。可以使用 DECLARE HANDLER 语句来声明错误处理程序。
DECLARE CONTINUE HANDLER FOR duplicate_key
BEGIN
--错误处理代码
END;
在抛出“duplicate_key”错误条件时,这段代码块就会被执行。
SQL语句:
在声明了错误和处理器后,就可以编写可能会引发错误的SQL语句。
触发错误处理:
当SQL语句中抛出的错误与你声明的错误 CONDITION 匹配时,MySQL就会调用你声明的处理代码。文章来源:https://www.toymoban.com/news/detail-811469.html
CREATE TRIGGER sample_trigger BEFORE INSERT ON sample_table
FOR EACH ROW
BEGIN
DECLARE duplicate_key CONDITION FOR SQLSTATE '23000';
DECLARE CONTINUE HANDLER FOR duplicate_key
BEGIN
-- 错误处理代码
END;
-- 常规SQL语句
END;
写在最后
事务处理是数据库管理的重要组成部分,理解事务和掌握事务处理技术,对于确保数据的完整性和一致性至关重要。只有掌握事务处理,我们才能编写出可以优雅地处理错误和异常,以及有效地管理并发操作的应用。希望通过本篇博文,对MySQL事务处理有了进一步的认识和理解。在接下来的学习中,希望你们可以通过实践,逐渐熟练这个重要的技术。文章来源地址https://www.toymoban.com/news/detail-811469.html
到了这里,关于MySQL修炼手册11:事务处理:确保数据的一致性与完整性的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!