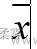前言
本篇将继续上篇文章进行介绍。
总体均值的检验
总体均值的检验(一个总体均值的检验)
小样本的检验
假定条件
小样本(n<30)
总体服从正太分布
检验统计量的选择与总体方差是否已知有关 已知样本,均值经标准化后服从标准正态分布:
已知样本,均值经标准化后服从标准正态分布:

单样本t检验的效应量通常使用 Cohen的d统计量来度量,计算公式为:
该效应量表示样本均值与假设的总体均值的差异是多少个标准差。根据 Cohen(1988)提出的标准,单样本t检验的小、中、大效应量对应的d值分别为0.20,0.50,0.80。即当d<0.20时,效应量非常小,几乎为0;当0.20≤d<0.50时,为小的效应量;当0.50≤d<0.80时,为中的效应量;当d≥0.80时,为大的效应量。0.20表示样本均值与假设的总体均值相差0.2个标准差,0.50表示相差0.5个标准差,0.80表示相差0.8个标准差。(Cohen提供的标准只是近似结果)
例题:
数据: example6_4.RData)一种建筑用砖的厚度要求为5cm,高于或低于该标准均被认为是不合格的。现对一家生产企业提供的20块样本进行检测,结果如表6-2所示:
假定砖的厚度服从正态分布,在0.05的显著性水平下,检验该企业生产的砖的厚度是否符合要求。
t.test(x,y=NULL,mu=0,)函数可以实现t检验。当不指定y时为单样本检验,mu为检验的均值,默认为0。
结论:在该项检验中,  =4.8,t=-5.6273,df=19,=1.998e-05,由于P<0.05,拒绝H0,有证据显示该企业生产的砖的厚度不符合要求。
=4.8,t=-5.6273,df=19,=1.998e-05,由于P<0.05,拒绝H0,有证据显示该企业生产的砖的厚度不符合要求。
检验结果表明,该企业生产的砖的厚度与5cm有显著差异,但要想知道差异的程度,则需要计算效应量。有
结果表示:样本砖的平均厚度与标准厚度相差1.258306个标准差。根据Cohen准则,该检验结果属于大的效应量。计算效应量的R代码和结果如下所示
计算效应量
load("C:/example/ch6/example6_4.RData")
library(lsr)
cohensD(example6_4$厚度,mu=5)

两个总体均值之差的检验
根据获得样本的方式不同,两个总体均值的检验分为独立样本和配对样本两种情形,而且也有大样本与小样本之分。检验的统计量是以两个样本均值之差( 
)的抽样分布为基础构造出来的。对于大样本和小样本两种情形,由于两个样本均值之差经标准化后的分布不同,检验统计量也有差异。
独立大样本的检验

例题:
(数据: example6_5. RData)为分析男女学生上网时间是否有差异,从男女学生中各随机抽取36人,得到每天的上网时间数据如下表所示。在显著性水平0.05下,检验男女学生上网的平均时间是否有显著差异
设μ1=男生上网的平均时间;μ2=女生上网的平均时间。由于关心上网的平均时间是否有显著差异,所以提出的假设为:
H0:μ1-μ2=0; H1:μ1-μ2≠0
检验的R代码和结果如下所示:
load("C:/example/ch6/example6_5.RData")
library(BSDA)
z.test(example6_5$男生上网时间,example6_5$女生上网时间,sigma.x=sd(example6_5$男生上网时间),sigma.y=sd(example6_5$女生上网时间),alternative="two.sided")

结论:在该项检验中,  =3.058333,
=3.058333,  =2.830556,z=1.1188,P=0.2632由于P>0.05,不拒绝H0,没有证据显示男女学生上网的平均时间有显著差异。
=2.830556,z=1.1188,P=0.2632由于P>0.05,不拒绝H0,没有证据显示男女学生上网的平均时间有显著差异。
独立小样本的检验

这时,两个样本均值之差经标准化后服从自由度为(n1+n2-2)的t分布,因而采用的检验统计量为:

例题:
(数据: example6_6. RData)为比较两家企业生产的灯泡平均使用寿命是否有显著差异,质检人员对两家供货商提供的各20个样品进行检测,得到的使用寿命数据如下表所示。检验两家企业灯泡的平均使用寿命是否有显著差异(  =0.05):
=0.05):
(1) 假设两个总体方差相等
(2) 将设两个总体方差不相等
t.test(x,y=null, alternative=c(“two. sided”,“less”,“greater”),mu=0,paired=FALSE
var. equal=FALSE,conf.level=0.95,)函数中,var. equal=true和var. equal=FALSE分别对应两总体方差相等和不相等的假设,默认var. equal=FALSE.默认 paired=FALSE,为独立样本检验, paired=TRUE为配对样本检验。
解:设μ1为甲企业灯泡的平均使用寿命,μ2为乙企业灯泡的平均使用寿命。依题意提出如下假设:
H0:μ1-μ2=0; H1:μ1-μ2≠0
检验的R代码和结果如下所示
(1) 假设两个总体方差相等
假设方差相等
load("C:/example/ch6/example6_6.RData")
t.test(example6_6$甲企业,example6_6$乙企业,var.equal=TRUE)

(2) 将设两个总体方差不相等
t.test(example6_6$甲企业,example6_6$乙企业,var.equal=FALSE)

结论在该项检验中,  =8487.5,
=8487.5,  =8166.0,假设总体方差相等时t=3.4943,df=38,P=0.00122:假设总体方差不等时,t=3.4943,=33.683,P=0.001353。两种假设条件下检验的P值均小于0.05,所以拒绝H0,表明两家企业生产的灯泡平均使用寿命有显著差异。
=8166.0,假设总体方差相等时t=3.4943,df=38,P=0.00122:假设总体方差不等时,t=3.4943,=33.683,P=0.001353。两种假设条件下检验的P值均小于0.05,所以拒绝H0,表明两家企业生产的灯泡平均使用寿命有显著差异。
检验结果显示两家企业生产的灯泡平均使用寿命差异显著,但要想知道差异的程度则需要计算效应量。独立样本t检验的效应量的估计通常由 Cohen的d统计量给出,计算公式为
该效应量表示总体1的均值( )与总体2的均值( )相差多少个标准差。根据 Cohen(1988)提出的标准,独立样本检验的小、中、大效应量对应的d值分别为0.20, 0.50, 0.80。
计算效应量的R代码和结果如下所示:
计算效应量
library(lsr)
cohensD(example6_6$甲企业,example6_6$乙企业)

结果显示,d=1.104985,表示甲企业和乙企业的灯泡平均使用寿命相差1.104985个标准差。根据 Cohen准则,该检验结果属于大的效应量。
配对样本的检验
例题:
(数据: example6_7. Rdata)某饮料公司研制出一款新产品,为比较消费者对新旧产品口感的满意程度,随机抽选一组消费者共10人,让每个消费者先品尝一款饮料,再品尝另一款饮料,两款饮料的品尝顺序是随机的,而后每个消费者要对两款饮料分别进行评分(0~10分),评分结果如下表所示。取显著性水平 =0.05,检验消费者对两款饮料的评分是否有显著差异。
解:设 u1 =消费者对旧款饮料的平均评分, u2=消费者对新款饮料的平均评分,依题意建立的原假设与备择假设为:
检验的R代码和结果如下所示:
load("C:/example/ch6/example6_7.RData")
t.test(example6_7$旧款饮料,example6_7$新款饮料,paired=TRUE)

结论:在该项检验中,  =-1.3,t=-2.7508,df=9,P=0.02245,由于P<0.05,拒绝H0,消费者对新旧饮料的评分有显著差异。
=-1.3,t=-2.7508,df=9,P=0.02245,由于P<0.05,拒绝H0,消费者对新旧饮料的评分有显著差异。
拒绝原假设后,可计算效应量来进一步分析配对样本差值的均值与假设的总体差值的均值之间的差异程度。配对样本t检验的效应量的估计由 Cohen的d统计量给出。计算公式为:
根据 Cohen提出的标准,配对样本检验的小、中、大效应量对应的d值分别为 0.20,0.50,0.80
计算效应量的R代码和结果如下所示
library(lsr)
cohensD(example6_7$旧款饮料,example6_7$新款饮料,method="paired")

总体比例的检验
总体比例的检验程序与总体均值的检验类似,本小节只介绍大样本情形下一个总体比例的检验方法和两个总体比例之差的检验方法。
一个总体比例的检验

例题:
一家电视台的影视频道制作人认为,某电视连续剧如果在黄金时段播出,收视率将会达到25%以上。经过一周的试播放后,该制作人随机抽取了由2000人组成的一个样本,发现有450个观众观看了该电视连续剧。取显著性水平a=0.05,检验收视率是否达到制作人的预期。
解:制作人想支持的观点是收视率达到25%以上,因此提出的假设为
H0: π ≤25%; H1: π>25%
检验的R代码和结果如下所示:
n<-2000
p<-450/2000
pi0<-0.25
z<-(p-pi0)/sqrt(pi0*(1-pi0)/n)
p_value<-1-pnorm(z)
data.frame(z,p_value)

在该项检验中,z=-2.581989,P=0.9950884,由于P>0.05,不拒绝H0,没有证据表明收视率达到了制作人的预期。
例题:
一所大学准备采取一项新的上网收费措施,为了解男女学生对这一措施的看法是否有差异,分别抽取200名男生和200名女生进行调查。其中的一个问题是:“你是否赞成采取新的上网收费的措施?”其中男生表示赞成的比例为27%,女生表示赞成的比例为35%。调查者认为,男生中表示赞成的比例显著低于女生。取显著性水平 =0.05,样本提供的证据是否支持调查者的看法?
解:设π1=男生中表示赞成的比例,π2=女生中表示赞成的比例。依题意提出如下假设解:
H0: π1-π2 ≥0; H1: π1-π2<0
检验的R代码和结果如下所示:
n1<-200;n2<-200
p1<-0.27;p2<-0.35
p<-(p1*n1+p2*n2)/(n1+n2)
z<-(p1-p2)/sqrt(p*(1-p)*(1/n1+1/n2))
p_value<-pnorm(z)
data.frame(z,p_value)
结论:在该项检验中,z=-1.729755,P=0.04183703由于P<0.05,拒绝H0。样本提供的证据支持调査者的看法,即男生中表示赞成的比例显著低于女生。
例题:
有两种方法生产同一种产品,方法1的生产成本较高而次品率较低,方法2的生产成本较低而次品率则较高。管理人员在选择生产方法时决定对两种方法的次品率进行比较。如果方法1比方法2的次品率低8%以上,则采用方法1,否则就采用方法2。管理人员从采用方法1生产的产品中随机抽取300个,发现有33个次品;从采用方法2生产的产品中也随机抽取300个,发现有84个次品。用显著性水平a=0.01进行检验,管理人员应决定采用哪种方法进行生产?
解:设π1=方法1的次品率,π2=方法2的次品率。因为是要检验“方法1的次品率是否比方法2低8%”(不是检验二者的差值是否等于0),所以选择下式作为检验统计量
H0: π1-π2 ≥8%; H1: π1-π2< 8%
检验的R代码和结果如下所示:
n1<-300;n2<-300
p1<-33/300;p2<-84/300
d0<-0.08
z<-((p1-p2)-0.08)/sqrt(p1*(1-p1)/n1+p2*(1-p2)/n2)
p_value<-pnorm(z)
data.frame(z,p_value)
结论:在该项检验中,z=-7.91229,P=1.26348e-15由于P<0.01,拒绝H0。表示方法1的次品率显著地低于方法2达8%以上,所以应采用方法1进行生产。
练习
1、(数据:exercise6_1.RData)一种机床加工的零件尺寸绝对平均误差为1.35mm。生产厂家准备采用一种新的机床进行加工以期进一步降低误差。为检验新机床加工的零件平均误差与旧机床相比是否有显著降低,从新机床生产的零件中随机抽取50个进行检验。50个零件尺寸的绝对误差数据(单位:mm)如下:
(1)检验新机床加工的零件尺寸的平均误差与旧机床相比是否有显著降低( =0.01)
=0.01)
解:假定零件尺寸的绝对误差服从正态分布
这里关心的是零件尺寸的绝对误差的均值是否显著低于过去的误差均值,也就是μ是否小于1.35mm,因此提出如下假设: 文章来源:https://www.toymoban.com/news/detail-811502.html
文章来源:https://www.toymoban.com/news/detail-811502.html
load("C:/exercise/ch6/exercise6_1.RData")
library(BSDA)
z.test(exercise6_1$零件误差,mu=1.35,sigma.x=sd(exercise6_1$零件误差),alternative="less",conf.level=0.99)
结论:在该检验中,z=-2.6061,P=0.004579,由于P<0.01,拒绝H0,新机床加工的零件尺寸的平均误差与旧机床相比显著降低 文章来源地址https://www.toymoban.com/news/detail-811502.html
文章来源地址https://www.toymoban.com/news/detail-811502.html
到了这里,关于统计学-R语言-7.2的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!