道生一,一生二,二生三,三生万物
我旁边的一位老哥跟我说,你知道分布式是是用来干什么的嘛?一句话给我干懵了,我能隐含知道,大概是用来做分压处理的,并增加系统稳定性的。但是具体如何,我却道不出个1,2,3。现在就将这些做一个详细的总结。至少以后碰到面试官可以说上个123。
那么就正式进入正题:
分布式概念
分布式是一种,将一个大问题拆分成多个小问题,并分别由多个节点协同完成的计算机解决方案。
既然是解决问题,那么是解决什么呢?
分布式的目的:是为了解决单个机器无法满足性能要求的问题
至于为什么单个机器无法满足,其实回头细想,现代的计算数据都是突出一个字,
大,这个大字就意味着处理数据的运算速度也得大,但是因为现代材料局限,一个主机的运算的能力有限,然而数据是成指数倍的增长,为了解决这个问题就是增加主机的数量,但是这就出现了另一个问题:->:如何将这些主机有机结合起来?分布式就是解决这个问题的。其实很多公司其实都不需要分布式,但是,时代进步的。不管现在是不是要用,但是未来的事情谁又说的清?
这个是网图,但是我认为这个是可以将现在大部分的分布式知识做一个较为全面的总结的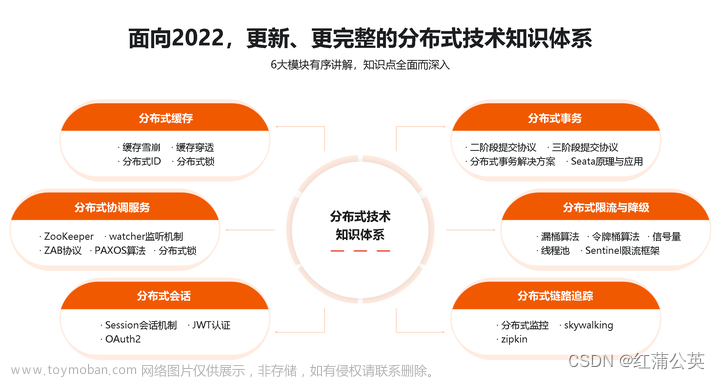
分布式这种框架的诞生,伴随着许多的问题,包括硬件,也包括软件,比如:
- 数据一致性
- 数据乱序
- 数据丢失
- 分库分表的扩容
- …
问题可以说是非常多。
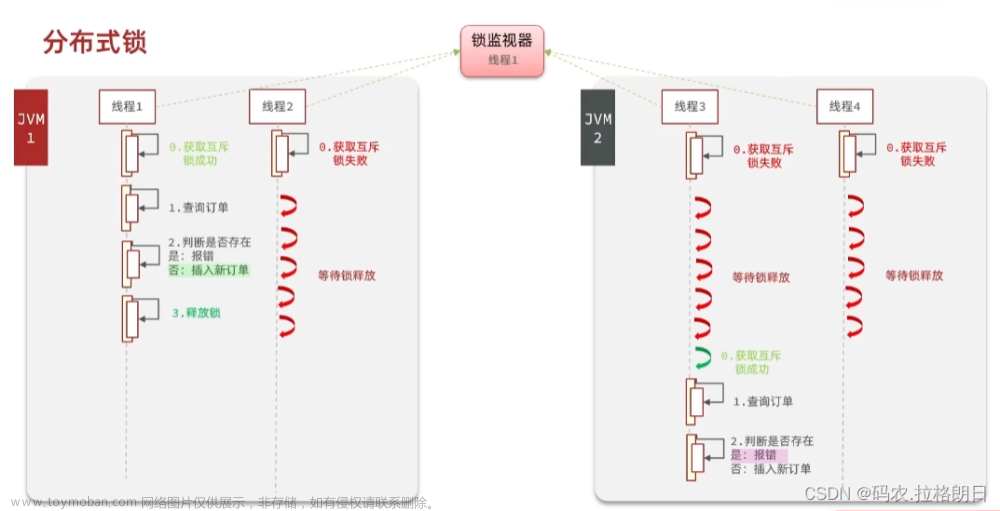
但是大部分是可以用技术手段去避免很多的问题。而分布式加锁就是一个较为有效的手段。不过就是牺牲了一部分的时效性,但是对于人类来说,这点时间的损耗,就是一个眨眼的功夫。希望日后会出现更多手段,去解决这方面的问题。
接下来就是对于分布式锁介绍
分布式锁
分布式锁的应用场景,这些既是应用场景也是问题所在:
- 处理缓存击穿
- 处理缓存雪崩
- 重试处理
- 幂等性
- 数据不一致的问题
- …
基本上很多分布式应用上的问题基本可以用分布式锁处理
那么什么算是一个合格的分布式锁呢?众多巨人的文章中无不透露以下这几点:
-
互斥性:这个是锁的基本功能,即:同一时刻只允许一个客户端持有锁 -
避免死锁:获取到锁的客户端出现问题了,没有办法解锁,所以要避免死锁。让系统继续运行下去(有些也叫安全性) -
容错:既然是服务器,那么提供锁的系统也是有可能崩溃的,所以要保证这一点。
这些属性,将会贯穿这篇文章。
分布式锁实现的方案
这些我会举出大体的实现思路,并不会全部去实现。
🌝每种实现类型中都有不同实现方式 ,比如mysql有悲观锁和乐观锁,读写锁这些方式的实现方式
常见的实现方案有:
- 数据库实现(我这里用的是mysql)
- redis实现
- zookeeper实现
- Redlock 算法实现
这里都会说到,但是对于实现来说,我目前就是只说MySQL的实现,redis的实现
语言对于程序员来说只是说某种工具而言,真正重要的是逻辑(算法)和数据结构,这个才是一个程序员安生立命的本钱。
所以这篇文章我会用go语言实现,其他语言的版本这里就不多说了。但是我会将常见的语言包说出,方便友友们能够快速查到相关的资料。
数据库实现(Mysql)
这里我用MySQL去实现:
技术:golang,gorm,数据结构
方式1:乐观锁
实现方式:通过对数据表添加一个字段 Version实现(数据版本(Version)记录机制实现)
主要逻辑:为数据库表增加一个数字类型的 version 字段来实现。当读取数据时,将version字段的值一同读出,数据每更新一次,对此version值加一
如果对于跟新操作,需要先判断当前version与数据库中的version版本号是否对应,对应的上就允许跟新,诺是不相同,就会导致冲突,此时就更新失败。
是不是很简单?是的确实很简单。画个图解释一下


那么悲观锁如何实现我相信大家肯定也就明白了。但是这里我就浅浅提一点:
在sql语句后添加for update
逻辑实现:
- 通过添加线程做轮询等待,然后抢锁
- 添加过期时间
- 更新版本号
接下来重点是读写锁的实现
方式2:读写锁的实现
而这两种锁的实现,需要满足一下几个特点:
- 执行操作的环境是分布式的(当然单机不是不能用)
- 读操作,不做限制,里面资源是共享的。可以支持多个线程或者协程对资源的读取的操作。
- 写操作,是互斥的,也就是说明一个时刻只允许一个协程或者进程对资源进行访问。
- 读操作,写操作两者是互斥的。不能同时存在
ps:相当于对于读写这两个操作来说,都有自己的申请锁和解锁的方法,读模式共享,写模式互斥
读写锁的有点在于:
- 分布式读写锁是比分布式锁粒度更小的锁
- 对于业务场景更加灵活
所以综上的出:读写锁的状态有:读加锁状态、写加锁状态、无锁状态
| 当前锁状态 | 读锁请求 | 写锁请求 |
|---|---|---|
| 无锁状态 | 可以 | 可以 |
| 读锁状态 | 可以 | 不可以 |
| 写锁状态 | 不可以 | 不可以 |
第一步:链接数据库
每个程序员的链接手法各不相同,所以这里就不献丑了。只要连上数据库就好。然后将客户端暴露出来。
第二部:建立数据库表
要包含一下这几个字段。
var (
statusUnLock = "Unlock"
statusReadLock = "ReadLock"
statusWirteLock = "WirteLock"
)
type RWLock struct {
//表示某条数据加锁的状态,只能是读锁、写锁、无锁状态中的一种,默认状态为无锁状态
LockStatus string `gorm:"default:'Unlock'"`
//ReadLockCount 字段则记录当前并发访问的 goroutine(可以理解成线程) 数量
ReadLockCount uint32 `gorm:"default:0"`
LockReason string //记录当前加锁的原因
}
// Stock 存储锁
type Stock struct {
gorm.Model
RWLock
Count int64
}
func (Stock) TableName() string {
return "stock"
}
这三个是状态值,分别代表:无锁,读锁,写锁
statusUnLock = “Unlock”
statusReadLock = “ReadLock”
statusWirteLock = “WirteLock”
gorm.Model中包含了:一下字段:
//主键id
ID uint `gorm:"primarykey"`
//创建时间
CreatedAt time.Time
//更新时间
UpdatedAt time.Time
//删除时间,软删除
DeletedAt DeletedAt `gorm:"index"`
这里我们通过的方式是,建立一个锁表来管理整个锁。相应的字段的功能我这里就不做赘述,在代码中已经有了。
第三步:读方法(读操作)
读加锁操作
// ReadLock 读锁
func (s Stock) ReadLock(ctx context.Context, db *gormX.DataBD, lockReason string) error {
fields := map[string]interface{}{
"lock_status": statusReadLock,
"read_lock_count": gorm.Expr("read_lock_count + ?", 1),
"lock_reason": lockReason,
}
//将所属的id锁的写状态改为读状态
result := db.DB(ctx).Model(&Stock{}).Where("id=? AND lock_status=?", s.ID, statusWirteLock).Updates(fields)
if result.Error != nil {
return result.Error
}
if result.RowsAffected == 0 {
return errors.New("重入锁失败,受影响的行数为 0")
}
return nil
}
我将对这里的代码做一个解释:
context.Context:上下文,用来管理请求db *gormX.DataBD: 用来处理mysql连接的lockReason:对每个锁进行备注
这里的读锁就是做一个统计,统计有多少个线程,是读锁状态
result := db.DB(ctx).Model(&Stock{}).Where("id=? AND lock_status=?", s.ID, statusWirteLock).Updates(fields):
这个整个sql的翻译,{参数}
update
stock
set
lock_status={statusReadLock},
read_lock_count =read_lock_count +1 ,//这个不是参数
lock_reason={lockReason}
where
id={s.ID} and statusWirteLoc={statusWirteLock}
这里为什么是update呢?因为在这里gorm中,update没有的数据的话,会变成insert插入数据。其他语言在做的时候一定要注意。
读解锁操作
// UnReadLock 读解锁
func (s Stock) UnReadLock(ctx context.Context, db *gormX.DataBD, UnLockReason string) error {
fields := map[string]interface{}{
"read_lock_count": gorm.Expr("if(read_lock_count>0),read_lock_count-1,0"),
"lock_status": gorm.Expr("if(lock_status < 1),?,?", statusUnLock, statusReadLock),
"lock_reason": UnLockReason,
}
result := db.DB(ctx).Model(&Stock{}).Where("id=? and lock_status=?", s.ID, statusReadLock).UpdateColumns(fields)
if result.Error != nil {
return result.Error
}
if result.RowsAffected == 0 {
return errors.New("解读锁失败,受影响的行数为 0")
}
return nil
}
这里将读操作做完的业务进行释放后,在表中做统计减少的操作。
我将对这里的代码做一个解释:result := db.DB(ctx).Model(&Stock{}).Where("id=? and lock_status=?", s.ID, statusReadLock).UpdateColumns(fields)
update
stock
set
lock_status=(if(read_lock_count>0),read_lock_count-1,0),
read_lock_count =(if(lock_status < 1),{statusUnLock},{statusReadLock}),
lock_reason={lockReason}
where
id={s.ID} and statusWirteLoc={statusReadLock}
第四步:写方法(写操作)
写加锁
// WriteLock 写锁
func (s Stock) WriteLock(ctx context.Context, db *gormX.DataBD, lockReason string) error {
fields := map[string]interface{}{
"read_lock_count": 0,
"lock_status": statusWirteLock,
"lock_reason": lockReason,
}
result := db.DB(ctx).Model(&Stock{}).Where("id=? and lock_status=?", s.ID, statusUnLock).Updates(fields)
if result.Error != nil {
return result.Error
}
if result.RowsAffected == 0 {
return errors.New("写入锁失败,受影响的行数为 0")
}
return nil
}
这里不对线程进行统计,因为这是互斥的。并将锁写入状态
我将对这里的代码做一个解释:result := db.DB(ctx).Model(&Stock{}).Where("id=? and lock_status=?", s.ID, statusUnLock).Updates(fields)
update
stock
set
lock_status={statusWirteLock},
read_lock_count =0 ,//这个不是参数
lock_reason={lockReason}
where
id={s.ID} and statusWirteLoc={statusWirteLock}
这里为什么是update呢?因为在这里gorm中,update没有的数据的话,会变成insert插入数据。其他语言在做的时候一定要注意。
写解锁
// UnWriteLock 写解锁
func (s Stock) UnWriteLock(ctx context.Context, db gormX.DataBD, UnLockReason string) error {
fields := map[string]interface{}{
"read_lock_count": 0,
"lock_status": statusUnLock,
"lock_reason": UnLockReason,
}
result := db.DB(ctx).Model(&Stock{}).Where("id=? and lock_status=?", s.ID, statusWirteLock).Updates(fields)
if result.Error != nil {
return result.Error
}
if result.RowsAffected == 0 {
return errors.New("解写锁失败,受影响的行数为 0")
}
return nil
}
这里不对线程进行统计,因为这是互斥的。并修改其状态
我将对这里的代码做一个解释:result := db.DB(ctx).Model(&Stock{}).Where("id=? and lock_status=?", s.ID, statusWirteLock).Updates(fields)
update
stock
set
lock_status={statusUnLock},
read_lock_count =0 ,//这个不是参数
lock_reason={lockReason}
where
id={s.ID} and statusWirteLoc={statusWirteLock}
redis实现
今天太晚了,先不写,明天补上:连接文章来源:https://www.toymoban.com/news/detail-811651.html
续:今天补上了:请看这篇文章文章来源地址https://www.toymoban.com/news/detail-811651.html
到了这里,关于分布式锁实现(mysql,以及redis)以及分布式的概念的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!