FID ↓ \downarrow ↓
Fréchet Inception Distance
基本思想:直接考虑生成数据和真实数据在feature层次的距离。
预训练好的神经网络可以在在高层提取图片的抽象特征。FID通常使用Inception Net-V3全连接前的2048维向量作为图片的feature。
直观感受,FID是反应生成图片和真实图片的距离,数据越小越好。
具体而言,FID是衡量两个多元正态分布的距离,其公式如下
F
I
D
=
∣
∣
μ
r
−
μ
g
∣
∣
2
+
T
r
(
∑
r
+
∑
g
−
2
∑
r
∑
g
1
/
2
)
FID = ||\mu_r-\mu_g||^2+Tr(\begin{matrix} \sum_r \end{matrix}+\begin{matrix} \sum_g\end{matrix}-2\begin{matrix} \sum_r\sum_g\end{matrix}^{1/2})
FID=∣∣μr−μg∣∣2+Tr(∑r+∑g−2∑r∑g1/2)
特点:
- 刷分不会导致生成图片质量变差
- 生成模型的训练集可以和Inception Net-V3不同
- FID是衡量多元正态分布直接按的距离,但提取的图片特征不一定是符合多元正态分布的
- 无法解决过拟合问题,如果生成模型只能生成和训练集一模一样的数据无法检测
代码:
计算FID的代码上传到这里了–>pytorch_fid
FVD ↓ \downarrow ↓
基本思想: 相当于把FID的图像特征提取网络换成视频特征提取网络,其他都差不多。
几种叫法:
- FID2vid(BoGAN)
来源论文:video-to-video synthesis
特征提取器:I3D, ResNeXt

- FID-vid(NvWA、TFGAN)
特征提取器:3D Resnet-50 model
Cited from TFGAN:
(3) Video-level FID: Features of the penultimate layer are extracted from 3D Resnet-50 model trained on the entire Kinetics dataset [Kay et al., 2017], and the FID score is computed between the real and generated videos. Note that lower the FID scores, better are the models.
Kay et al., 2017. The kinetics human action video dataset.
- Fréchet Video Distance(FVD) (Cogvide, make-a-video…)
特征提取器:3D Resnet-50 model
来源论文:Latent Video Transformer

3D特征提取器分析:
- 参考FID,已知生成模型的训练集可以和特征提取器不同。但是根据《video-to-video synthesis》论文里的结果,使用不同特征提取器的结果会不一样,目前github和谷歌上都搜不到FVD比较官方的实现,不能确定用哪个特征提取器;
- BoGAN中没有明确指出用的哪个3D特征提取器,其他几篇指出用的kinetic-400中训练的3D ConvNet(C3D)。
- 但是目前同样没有找到kinetics提供的这个预训练3D ConvNet,不过《video-to-video synthesis》中用到的I3D可以找到kinetics-400上预训练的checkpoint,故我的工作里目前使用I3D。
代码: 把特征提取器换掉参考FID的小修改就可以了。
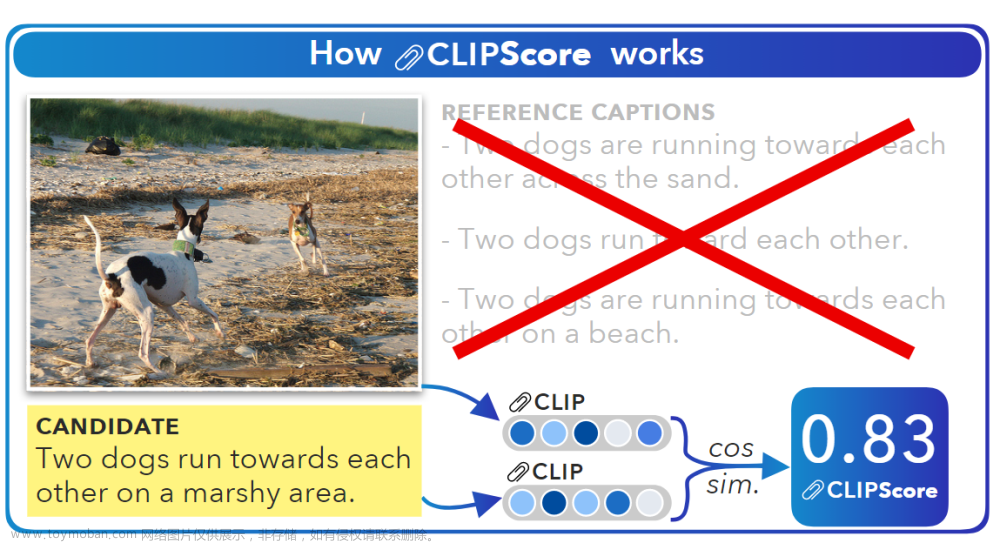
CLIPSIM ↑ \uparrow ↑
来源论文:GODIVA
使用论文:GODIVA、NVWA、make-a-video

基本思想:
利用具有zero-shot能力的多模态模型CLIP输出文本和图像相似度,在视频任务中使用时采取每一帧相似度的平均值。
使用:
参考这个工具和CLIP代码自己改编一下就好,我代码写太烂就不放了
CLIP-as-sevice
CLIP代码参考1
CLIP代码参考2
大致思路是用这个工具获得valid set的帧编码&文本编码,然后可以获得对应文本图像对的相似度,对每一帧都算,然后取均值。
(用这个思路写的代码测试过make-a-video结果,跑出来的数差不多,但不知道对不对,也没找到官方代码,如果有不对欢迎交流)
Acc ↑ \uparrow ↑
来源论文:T2V&TFGAN,用于Kinetic数据集
使用论文:T2V、TFGAN、NVWA
基本思想:相当于IS指标的变种
GFLOPs
参考链接:轻量级神经网络
区分:
-
FLOPS (全部大写)是floating-point operations per second的缩写,意指每秒浮点运算次数。用来衡量硬件的性能。
常用当然还有GFLOPs和TFLOPs
GFLOPS 就是 Giga Floating-point Operations Per Second,即每秒10亿次的浮点运算数,常作为GPU性能参数但不一定代表GPU的实际表现,因为还要考虑具体如何拆分多边形和像素、以及纹理填充,理论上该数值越高越好。1GFlops = 1,000MFlops。 - FLOPs 是floating point of operations的缩写,是浮点运算次数,可以用来衡量算法/模型复杂度。
如何计算FLOPs
对于卷积层而言,FLOPs的计算公式如下:
F
L
O
P
s
=
2
H
W
(
C
i
n
K
2
+
1
)
C
o
u
t
FLOPs = 2HW( C_{in}K^2+ 1 )Cout
FLOPs=2HW(CinK2+1)Cout
其中的Cin是指卷积层输入tensor的通道数,Cout指的是卷积层输出tensor的通道数。K指的是卷积核大小。
而后把常数项去掉,简化小操作:
F L O P s = H W ( C i n K 2 ) C o u t FLOPs = HW( C_{in}K^2 )Cout FLOPs=HW(CinK2)Cout
而在实际中,我们不可能自己计算FLOPs,所以,本着能找库就找库的聪明才能,查了一下,还真有相关计算FLOPs的库,现查到的有两个库,一个是torchstat以及thop。经过测试,基本上两个可以对齐的,所以说,任意选择一个就好。具体用法写两个小demo吧。
而在实际中,我们不可能自己计算FLOPs,所以,本着能找库就找库的聪明才能,查了一下,还真有相关计算FLOPs的库,现查到的有两个库,一个是torchstat以及thop。经过测试,基本上两个可以对齐的,所以说,任意选择一个就好。具体用法写两个小demo吧。
对于torchstat:
from torchstat import stat
import torchvision.models as models
model = model.densenet121()
stat(model, (3, 224, 224))
对于thop:
from torchvision.models import densenet121
from thop import profile
model = densenet121()
input = torch.randn(1, 3, 224, 224)
macs, params = profile(model, inputs=(input, ))
例2文章来源:https://www.toymoban.com/news/detail-811749.html
pip install thop # 安装thop库
import torch
from thop import profile
net = model() # 定义好的网络模型
img1 = torch.randn(1, 3, 512, 512)
img2 = torch.randn(1, 3, 512, 512)
img3 = torch.randn(1, 3, 512, 512)
macs, params = profile(net, (img1,img2,img3))
print('flops: ', 2*macs, 'params: ', params)
为什么不能只用FLOPs作为指标呢?
作者认为有如下几个原因:
1)FLOPs没有考虑几个对速度有相当大影响的重要因素。
2)计算平台的不同。
3) FLOPs没有考虑几个对速度有相当大影响的重要因素:MAC和并行度
Params
参考链接

获取该值:
例1
net = model() # 定义好的网络模型
total = sum([param.nelement() for param in net.parameters()])
print("Number of parameter: %.2fM" % total)
这是网上很常见的直接用自带方法计算params,基本不会出错。胜在简洁。
例2
#model = 你自己的模型,eg:CNN() ResNet() SegNet()....
params = list(model.parameters())
k = 0
for i in params:
l = 1
print("该层的结构:" + str(list(i.size())))
for j in i.size():
l *= j
print("该层参数和:" + str(l))
k = k + l
print("总参数数量和:" + str(k))
Runtime
对比inference speeds
这个值怎么获取没弄懂
相关论文里也没有讲解,待更新…文章来源地址https://www.toymoban.com/news/detail-811749.html
到了这里,关于文本生成视频相关指标整理的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!