VG:输入点云(包含3D坐标、RGB、法向量等信息)通过W个label得到的文本描述D,基于与物体相关的语言描述来完成目标的定位。
习惯上先看abstract和conclusion还有图表,看下来主要针对于两个模块:
首先先提取它的点云特征(用backbone得到点云种子)-->DKS粗略找到描述的物体的点 -->
TPM精细选择目标keypoint --> 选取置信度最高的keypoint来回归检测框。
在进入该篇论文解读之前,作者先引出现阶段研究很多基于two stage[更多集中工作于二阶段]:
1.detection:传统的3D目标检测器去生成一堆的proposal。
2.matching:将描述的物体与proposal相匹配。
一、motivation
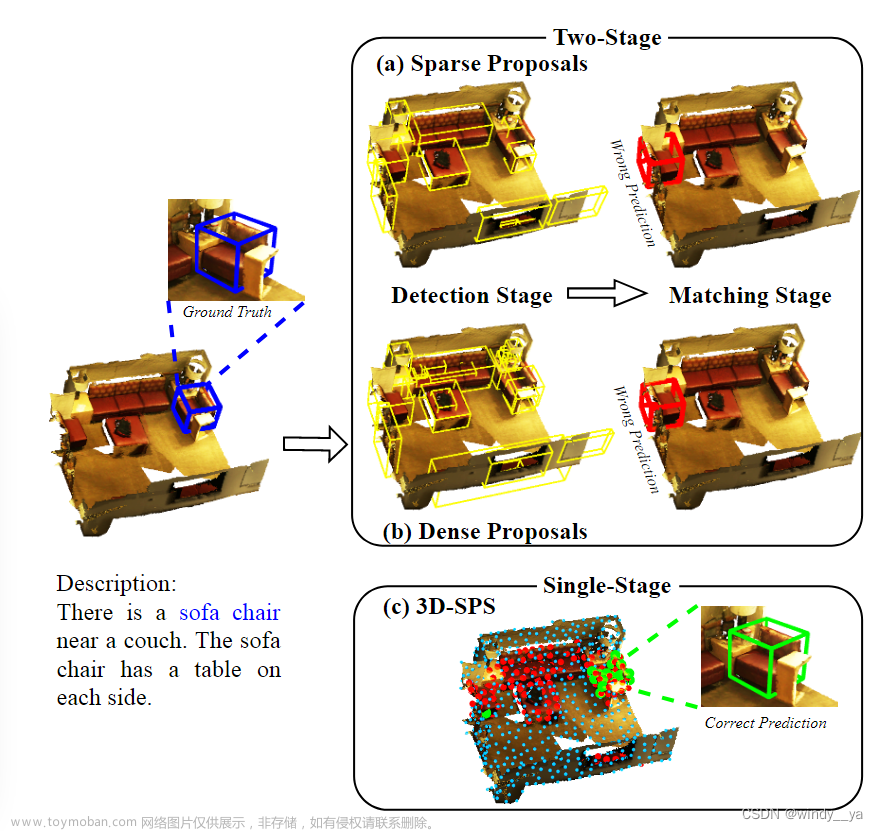
1.twosatge在选择proposal上不好,如图所示,(a)sparse容易漏检,(b)dense会造成proposal太多太复杂而难以区分优化。(其实这个说法在二维的目标检测中也很常见)
2.two stage的一阶段常使用的FPS的采样是和语言无关的,而是覆盖整个场景中较多的物体,从而目标采样点所占比例也相对较小了,不利于预测。但VG本身只是关注于想要的目标,两个任务是分离的所以不明智。
总的来说就是以往用的two stage是先检测后匹配,而在匹配阶段中没有利用语言上下文来专注特定关键点--> 单阶段并且用文本来指导筛选关键点
二、innovation:
single stage 3D VG:弥补检测和匹配的gap,简单来说就是把问题变成找到关键点,根据置信度直接回归得到预测框的单阶段问题,任务中心在于关键点的选择。
1.DKS:基于文本对关键点进行粗略采样
2.TPM:精细挖掘跨模态信息,找到检测目标
【跟人识别物体一样,根据文本粗略的选择一些候选集,然后再精细判断所需目标对象】
三、architecture

(1)backbone抽出点云特征得到Pseed; 上面用language encoder得到文本描述的的特征L0
(2)Pseed和L0输入DKS中得到跟描述有关的所有关键点P0
(3)文本特征L0和关键点P0输入TPM(多层跨模态的transformer)中??
(4)得到Pt和Lt后放入MLP中算置信度S
(5)最后根据置信度再对应关键点进行回归得到目标物体的预测框。
接下来详细介绍一下DKS、TPM
1.DKS(Description-aware Keypoint Sampling):
innovation:就是前面提到的二阶段中的检测是检测全局物体,因此两阶段任务其实是分离的。作者提出直接利用词特征粗略筛选文本相关的关键点。
(1)将seed输入MLP得到S0来筛选topK0个有物体的关键点Pobj,可以看到图去掉了灰色的no-object的点。

(2)[蓝色部分]word feature经过Maxpooling后进入MLP得到置信度Sd,筛选TopK个得到下标,通过下标在Pobj去选取,可以看到删去了橘色的表示与词无关的点,只得到和词特征相关的关键点。

经过以上两步后得到的P0的信息就不仅仅是目标对象,还包含与目标对象有关的信息(可以用来指导选出最终的target)。

2.TPM(Target-oriented Progressive Mining)
逐层丢掉和目标无关的关键点
1.
(1)keypoint自注意力[深蓝色框],可以改善point的feature并且利用其空间特征。
(2)keypoint的cross-attention[紫红色框],这一步还蛮巧妙的,将之前与文本无关的点也放进来作为K/V(就是在DKS之前的Pseed),这样就有了全局特征【如果只有与文本有关的关键点,那么"in the center/corner of room"这种方位信息很难定位,因为没有全局特征】
2.language的self-attention[浅蓝色框],结合上下文信息。
3.language和keypoint跨模态的cross-attention:language分支帮助keypoint找到target;keyponit分支帮助language更好的去理解融合场景信息。
4.交叉注意力图:表示关键点对目标a的重要性,做平均池化?后选择topk个关键点


四、LOSS
1.LVG:最主要的损失,训练阶段用target来监督Pt中的Sr,推理阶段用Pt中SR最高的来回归检测框,置为1
2.LDKS:
3.Det:算是辅助损失,由cls、obj、center、box的损失构成(就是目标检测用到的常规损失),当然这里训练时时TMP的multi,推理时是Sr中的top。
4.Llang:也是辅助损失,每一层TMP得到的language feature中多类别和target做loss。
Global Loss:
L = α1LVG + α2LDKS +α3LDet + α4Llang
五、实验
1、experience
(1)Scanrefer
可以看到不管是在3D还是2D+3Dacc都提点,但是其中TGNN和instanceRefer用的是分割,所以在acc@0.5中instanceRefer更高。

(2)Nur3D& Sur3D
+2.3 +4.7
查一下这个languageRefer

(3)analysis
另外作者也给了以twostage为baseline的对比,感觉可以用来解释为什么3D-SPS效果更好:如图(a),twosatge随keypoint的增加acc先增加后下降,而3D-SPS随keypoint增加而增加;由(b)也知,是因为3D-SPS的target在采样点中的比例随keypoint增加而增加,有利于更好的检测target,accjiu增加了。

2、Ablation
(1)探究DKS采样策略

(2)探究TMP的layer
文章中解释K>4可能会丢掉一些target的keypoint,导致漏掉了最好的box??

(3)探究TMP渐进关键点的选择
【分析】w/o就是只有跨模态的self/cross attention,没有keypoint的进一步选择(即下面的红框部分),所以keypoint的数量是没有减少的;由table5可以看出,在没有TPM渐进选择下随keypoint增多acc先升高后下降[这个是因为target的点比例降低];有TMP渐进选择可以让acc升高。

3、可视化效果
(1)3D-SPS先关注文本相关点,后选择target点;而Two-stage采样点覆盖整个场景,检测和匹配分离,导致最后框错目标。

(2)第二个可视化算是对上一个可视化的进一步解释,即3D-SPS在筛选描述相关的keypoint的表现,可以看上面,左边有提到windows于是Po关注在tavble和windows,右边没有提window,就没有关注windows了;下面的shelf也是同理。

BASIC
一、数据集
1、Nr3D&Ns3D【基于Scannet,一个真实世界的3D场景数据集,有语义标注】:将语言和几何信息(以3D点云的形式)结合起来,即描述以object的语言文本,在3D场景中识别target。
参考Sr3D & Nr3D

二、FPS最远点采样:
有一篇解释的很好的博客链接,指路:通俗易懂地解释FPS
让采样点尽可能地覆盖整个场景。
通俗来讲就是先随机选一个点P0 --> 算P0和其他点的欧氏距离,选择距离最远的点为P1 --> 分别算剩下的点和P0、P1的距离,选小的值来代表该点到P1、P2的距离 --> 然后选择距离最大的... 重复后两步以此类推,得到的就是较离散、覆盖较全面的点集。文章来源:https://www.toymoban.com/news/detail-811818.html
 文章来源地址https://www.toymoban.com/news/detail-811818.html
文章来源地址https://www.toymoban.com/news/detail-811818.html
到了这里,关于3D-SPS论文阅读的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
![[论文阅读]Multimodal Virtual Point 3D Detection](https://imgs.yssmx.com/Uploads/2024/02/778145-1.png)

![[论文阅读]MV3D——用于自动驾驶的多视角3D目标检测网络](https://imgs.yssmx.com/Uploads/2024/02/721503-1.png)

![[论文阅读]PillarNeXt——基于LiDAR点云的3D目标检测网络设计](https://imgs.yssmx.com/Uploads/2024/02/715798-1.png)





