欢迎来到这篇博客!今天我们将深入探讨PyTorch中的K最近邻(KNN)算法,这是一种简单但非常有用的机器学习算法。无论你是机器学习初学者还是有一些经验,我们将从头开始,逐步解释KNN算法的工作原理和如何在PyTorch中实现它。
什么是K最近邻(KNN)算法?
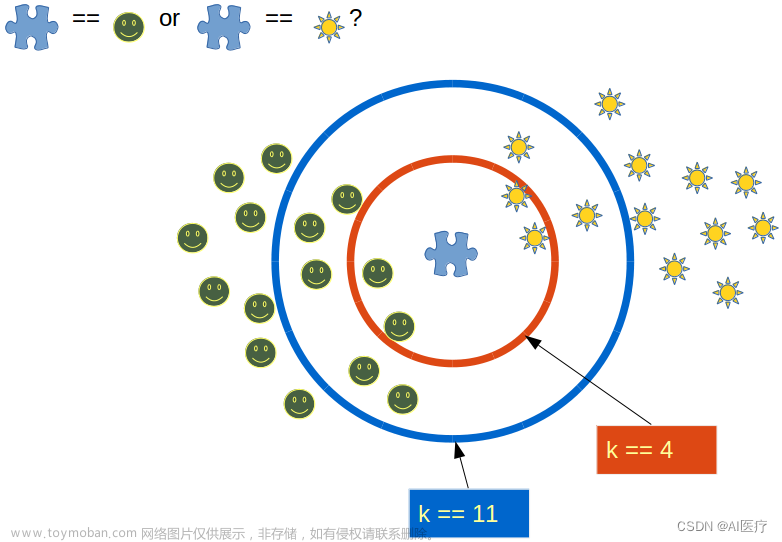
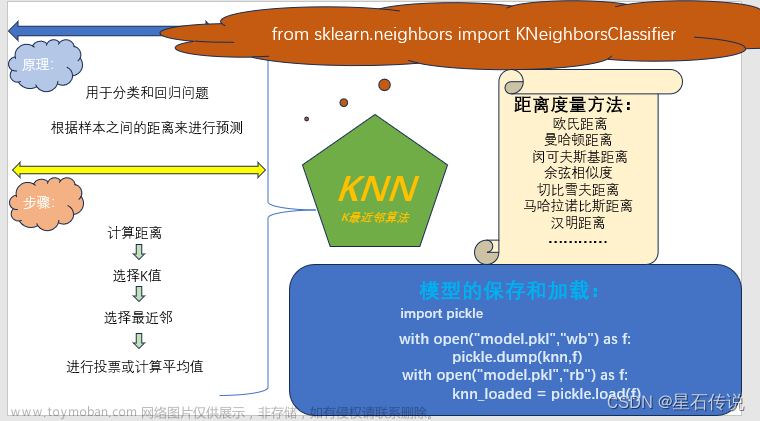
K最近邻算法是一种监督学习算法,用于分类和回归问题。KNN的核心思想是:如果一个样本在特征空间中的K个最近邻居中的大多数属于某个类别,那么这个样本也属于这个类别。KNN是一种基于实例的学习方法,它不需要显式的模型训练,而是根据已有的数据集进行预测。
让我们从KNN的基本原理开始:
-
距离度量: 在KNN中,我们首先需要选择一个距离度量方法,通常使用欧氏距离或曼哈顿距离。这个距离度量用于衡量样本之间的相似性。
-
选择K值: KNN算法中的K是一个超参数,需要我们自行选择。K表示我们要考虑多少个最近邻居。选择合适的K值对KNN的性能至关重要。
-
预测: 对于要预测的新样本,我们计算它与训练集中所有样本的距离,然后选择距离最近的K个样本。根据这K个最近邻居的类别,我们可以通过多数表决来预测新样本的类别。
现在让我们看看如何在PyTorch中实现KNN算法。
PyTorch中的KNN算法实现
在PyTorch中,我们可以使用张量操作和广播功能来实现KNN算法。首先,我们需要加载所需的库和数据集。
import torch
import torchvision
import torchvision.transforms as transforms
import torch.nn.functional as F
接下来,我们将使用CIFAR-10数据集来演示KNN算法。我们需要加载训练集和测试集,并进行适当的数据预处理。
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,
shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=4,
shuffle=False, num_workers=2)
现在我们已经准备好数据,让我们定义KNN算法的核心部分。
class KNN:
def __init__(self, k=3):
self.k = k
def fit(self, X, y):
self.X_train = X
self.y_train = y
def predict(self, X):
y_pred = [self._predict(x) for x in X]
return torch.tensor(y_pred)
def _predict(self, x):
# 计算x与所有训练样本的欧氏距离
distances = [torch.norm(x - x_train) for x_train in self.X_train]
# 找到K个最近邻居的索引
k_indices = torch.topk(torch.tensor(distances), self.k, largest=False).indices
# 获取K个最近邻居的标签
k_nearest_labels = [self.y_train[i] for i in k_indices]
# 多数表决法来预测标签
most_common = torch.bincount(torch.tensor(k_nearest_labels)).argmax()
return most_common
现在,我们已经定义了KNN类,我们可以将数据传递给它并进行预测。
# 准备数据
X_train = torch.cat([x for x, _ in trainloader])
y_train = torch.tensor([y for _, y in trainloader])
X_test = torch.cat([x for x, _ in testloader])
y_test = torch.tensor([y for _, y in testloader])
# 创建KNN模型并拟合数据
knn = KNN(k=5)
knn.fit(X_train, y_train)
# 预测测试集
y_pred = knn.predict(X_test)
# 计算准确率
accuracy = torch.sum(y_pred == y_test).item() / len(y_test)
print(f"KNN accuracy: {accuracy * 100:.2f}%")
在这段代码中,我们首先准备了CIFAR-10数据集并创建了KNN模型。然后,我们用训练数据拟合了模型,并使用测试数据进行了预测。最后,我们计算了模型的准确率。
KNN算法非常适合用于图像分类等任务,尤其是在数据集相对较小且特征维度不太高的情况下。它的简单性和效果在某些情况下可能超过了复杂的深度学习模型。
超参数选择
在使用KNN算法时,有一些关键的超参数需要选择,包括K值和距离度量方法。这些选择会影响算法的性能。
-
K值选择: 选择K值通常是一个经验性的过程。较小的K值会使模型更容易受到噪声的影响,较大的K值会使模型更加平滑。通常使用交叉验证等技术来选择合适的K值。
-
距离度量选择: KNN算法的性能与距离度量方法密切相关。欧氏距离是一种常见的选择,但根据数据集的特性,曼哈顿距离、闵可夫斯基距离等也可以考虑。
KNN的优点和缺点
KNN算法有其独特的优点和缺点,我们来总结一下:
优点:
-
简单易懂: KNN是一种直观且易于理解的算法,适合初学者入门。
-
无需训练: 与许多其他机器学习算法不同,KNN不需要训练模型,因为它存储了所有的训练数据。
-
适用于多分类问题: KNN可以处理多分类问题,并且对于每个类别都有一个多数表决的过程。
缺点:
-
计算复杂度高: 在大型数据集上运行KNN算法可能会变得非常慢,因为它需要计算每个测试样本与所有训练样本的距离。
-
对异常值敏感: KNN对异常值非常敏感,因为它主要依赖于距离度量。
-
高维数据困难: 在高维空间中,KNN算法的性能通常会下降,因为距离度量在高维空间中失去了效力(维度灾难)。
结语
K最近邻算法是一种强大的机器学习算法,尤其适用于小型数据集和低维特征空间。在这篇博客中,我们学习了KNN算法的基本原理,并使用PyTorch实现了一个简单的KNN分类器。希望这篇文章能帮助你更好地理解KNN算法,并在实际问题中应用它。文章来源:https://www.toymoban.com/news/detail-812327.html
在深入学习机器学习和深度学习之前,掌握KNN算法是一个不错的起点。继续学习和实践,你将更深入地理解不同算法之间的区别和适用场景,为解决各种机器学习问题做好准备。祝你在机器学习的旅程中取得成功!文章来源地址https://www.toymoban.com/news/detail-812327.html
到了这里,关于PyTorch中的K最近邻(KNN)算法的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!