word2cev简单介绍
Word2Vec是一种用于学习词嵌入(word embeddings)的技术,旨在将单词映射到具有语义关联的连续向量空间。Word2Vec由Google的研究员Tomas Mikolov等人于2013年提出,它通过无监督学习从大规模文本语料库中学习词汇的分布式表示。目前Word2Vec有两种主要模型:Skip-gram和Continuous Bag of Words (CBOW)。前面已经讨论过它们的基本思想,简要总结如下:
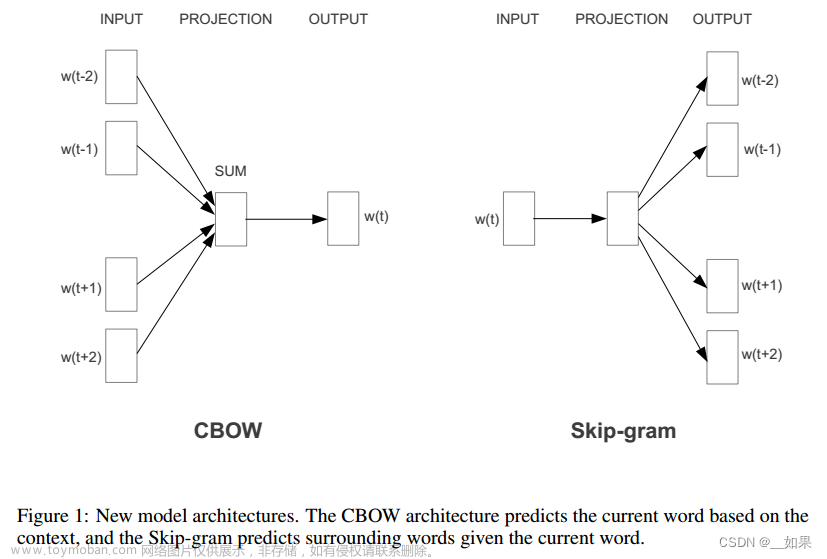
1.Skip-gram: 从一个词预测其周围的上下文词,引入了独立假设,认为上下文的每个词都可以独立预测。
2.CBOW: 从上下文的词预测中心词,通过对上下文词的平均进行预测。
无论是Skip-gram还是CBOW,它们都使用神经网络进行训练,其中词向量是模型学习的参数。这些词向量在向量空间中被设计成使得语义相似的词在空间中距离较近。Word2Vec的训练通常涉及大量的文本数据,以便能够学到通用的词汇表示。Word2Vec模型在自然语言处理领域的应用广泛,包括词义相似度计算、文档相似度、命名实体识别等任务。得到的词嵌入可以被用作其他自然语言处理任务的输入特征,或者通过进一步微调可以适应特定任务的语境。
一.CBOW
CBOW(Continuous Bag of Words)是一种用于自然语言处理中的词嵌入模型,它的思想是从周围的上下文词语预测中心词。具体来说,CBOW的目标是根据上下文中的词语来预测当前位置的目标词语。
1.1CBOW的训练步骤
CBOW的训练过程包括以下步骤:
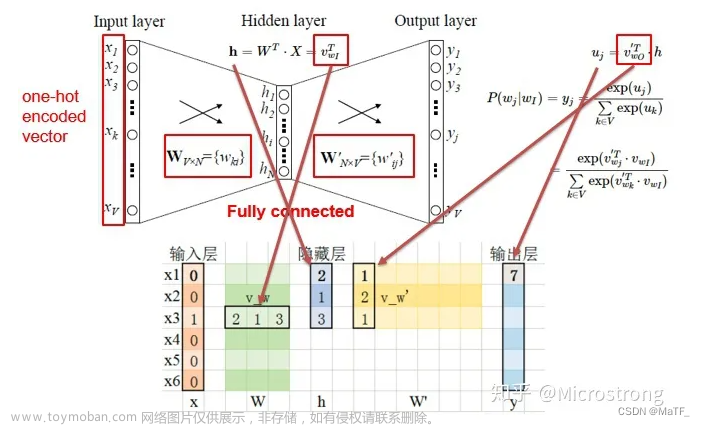
构建词嵌入表: 首先,为语料库中的每个词语构建一个词向量(词嵌入)。这些词向量可以随机初始化,然后在训练过程中不断调整。
上下文窗口: 对于每个训练样本,模型会选择一个中心词,然后从该中心词的上下文中选择周围的2n个词语作为输入。这个上下文窗口的大小由超参数n决定。
预测中心词: 使用选定的上下文词向量的平均值或拼接它们,作为输入,通过一个神经网络预测中心词。这个神经网络通常包含一个或多个隐藏层。
损失函数: 使用损失函数(通常是交叉熵损失函数)来度量预测的中心词和实际中心词之间的差异。
反向传播: 通过反向传播算法来调整词向量,使得损失函数最小化。这会更新词嵌入表中的每个词的向量表示。
1.2训练优化的策略
CBOW(Continuous Bag of Words)模型训练词向量时使用的优化策略通常是随机梯度下降(SGD)或其变体。以下是CBOW训练词向量时的一般优化策略:
梯度下降算法: CBOW通常使用随机梯度下降(SGD)或其变体来最小化损失函数。
SGD每次从训练数据中随机选择一个小批量样本,计算损失,并更新模型参数以减小损失。
这个过程不断迭代,直到达到预定的迭代次数或损失满足某个条件。
学习率调度: 为了稳定和加速训练过程,可以使用学习率调度策略。
学习率是梯度下降中用于控制参数更新幅度的超参数。
学习率调度允许在训练过程中逐渐降低学习率,以便在接近最优解时更加细致地调整模型参数。
负采样: 在CBOW的训练中,通常需要对负样本进行采样,以便更有效地训练模型。
负采样是指在计算损失时,不是对所有可能的词汇进行预测,而是从负样本中随机选择一小部分来计算损失。
这样可以减少计算复杂度,加速训练。
批量训练: 与在线学习相对,批量训练使用整个训练数据集的子集进行参数更新。
批量训练可以带来更加稳定的收敛和更高的训练效率。
参数初始化: 初始化词向量和神经网络参数对于训练的成功非常重要。
通常,可以使用小量的随机数来初始化参数,以确保在训练过程中网络能够学到有用的表示。
层次化softmax: 在CBOW模型中,层次化softmax是一种用于优化训练过程的策略,特别是在大规模词汇量的情况下。
层次化softmax通过构建一个二叉树结构,将词汇表中的词语划分为不同的类别,从而降低了计算复杂度。
这种策略可以有效地加速训练过程,尤其在训练大规模语料库时表现得更为明显。
层次化softmax的主要思想是将词汇表中的词语组织成一棵二叉树,其中每个叶子节点表示一个词语。
通过在树上进行二进制编码,可以用较少的比特数来表示较常见的词汇,从而减少了计算的复杂度。
训练时,模型通过遵循从树根到叶子节点的路径,来预测目标词语。
以下是使用层次化softmax进行CBOW训练的步骤:
构建二叉树: 将词汇表中的词语组织成一个二叉树结构。频率较高的词语通常位于树的较底层,而频率较低的词语位于较高层。
路径编码: 为了在树上表示每个词语,对每个内部节点和叶子节点分配一个二进制编码。通常,可以使用哈夫曼编码等方法。
训练过程: 在CBOW的训练过程中,通过预测目标词语的路径,使用层次化softmax计算损失。这样可以避免对整个词汇表进行全面的计算,提高了训练的效率。
层次化softmax的主要优势在于,它可以在保持模型性能的同时,显著减少计算开销。
然而,它的构建和实现可能相对复杂,需要一些额外的工作来准备树结构和路径编码。
CBOW的优点之一是它相对较快地训练,因为它对上下文中的词语进行平均处理,减少了模型参数的数量。然而,它可能在处理稀有词汇或短语的能力上略逊于Skip-gram模型。
二.Skip-gram
Skip-gram是一种用于自然语言处理中的词嵌入模型,与CBOW(Continuous Bag of Words)相反,它的思想是从当前词预测上下文的词语。具体来说,Skip-gram的目标是在给定中心词的情况下预测其周围的上下文词语。
Skip-gram与CBOW之间的核心差异在于其独立假设性。在Skip-gram中,每个上下文词都被认为是独立的,模型的目标是独立地预测每个上下文词,而不是像CBOW那样对上下文词的平均进行预测。这使得Skip-gram更适合处理包含复杂语法和语义关系的语料库。
2.1训练步骤
Skip-gram的训练过程包括以下步骤:
构建词嵌入表: 与CBOW类似,首先为语料库中的每个词语构建一个词向量,这些词向量可以随机初始化。
上下文窗口: 对于每个训练样本,模型会选择一个中心词,并从该中心词的上下文中选择周围的词语作为目标预测。
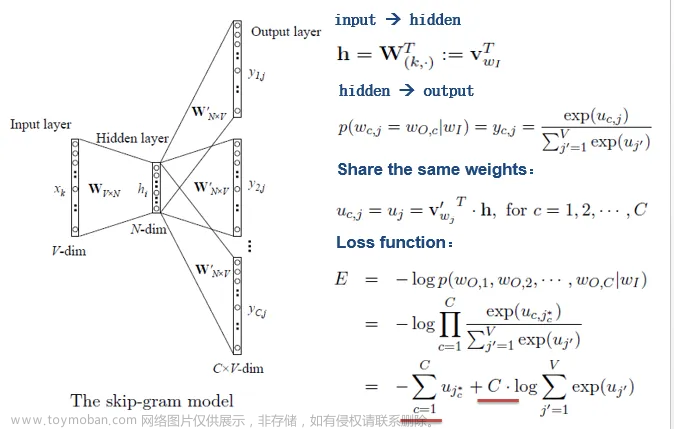
预测上下文词: 使用选定的中心词的词向量,通过一个神经网络预测上下文词。这个神经网络通常包含一个或多个隐藏层。
损失函数: 使用损失函数(通常是交叉熵损失函数)来度量预测的上下文词和实际上下文词之间的差异。
反向传播: 通过反向传播算法来调整词向量,使得损失函数最小化。这会更新词嵌入表中的每个词的向量表示。
Skip-gram的优势之一是它在处理罕见词汇和捕捉词汇之间的复杂关系方面表现较好。然而,由于每个上下文词都被独立预测,训练过程可能会更慢,特别是在大规模语料库中。
2.2优势
1.处理罕见词汇: Skip-gram相对于CBOW在处理罕见词汇方面表现更好。这是因为Skip-gram的目标是从一个词语预测其上下文,因此对于罕见词汇,通过训练模型学到的词向量可能更具有泛化性,能够更好地捕捉它们的语义信息。
2.捕捉复杂关系: Skip-gram的独立假设性使其更能够捕捉词汇之间的复杂关系。每个上下文词都被独立预测,这允许模型在学习过程中更灵活地调整每个词的向量表示,从而更好地捕捉词汇的细粒度语义信息。
2.3挑战
训练速度慢: 由于每个上下文词都被独立预测,Skip-gram的训练过程相对较慢,尤其是在大规模语料库中。这是因为对于每个训练样本,需要更新多个参数,导致计算复杂度较高。
存储需求高: 由于Skip-gram需要学习每个词语的词向量,对于大规模的词汇表,存储这些词向量可能需要大量的内存。这可能成为在资源受限环境中应用Skip-gram时的一个挑战。
参数数量多: Skip-gram的模型参数数量与词汇表的大小相关。当词汇表很大时,模型的参数数量也会增加,可能导致模型的训练和存储变得更为复杂。
总体而言,Skip-gram模型在某些任务和语境下表现得很好,但在实际应用中需要权衡其优势和挑战。在资源受限或对训练时间要求较高的情况下,研究人员可能会选择其他词嵌入模型或采用一些技术来加速训练过程。文章来源:https://www.toymoban.com/news/detail-812431.html
word2vec中的CBOW和Skip-gram和传统语言模型的优化目标采用了相同的方式,但是最终的目标不同。语言模型的最终目标是为了通过一个参数化模型条件概率以便更好的预测下一个词,但是词向量是通过条件概率获得词向量矩阵。文章来源地址https://www.toymoban.com/news/detail-812431.html
到了这里,关于word2vec中的CBOW和Skip-gram的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!