常见日志收集方案
1.1、EFK
在Kubernetes集群上运行多个服务和应用程序时,日志收集系统可以帮助你快速分类和分析由Pod生成的大量日志数据。
Kubernetes中比较流行的日志收集解决方案是Elasticsearch、Fluentd和Kibana(EFK)技术栈,也是官方推荐的一种方案。
1)Elasticsearch:是一个实时的,分布式的,可扩展的搜索引擎,它允许进行全文本和结构化搜索以及对日志进行分析。它通常用于索引和搜索大量日志数据,也可以用于搜索许多不同种类的文档。
2)Kibana:Elasticsearch通常与Kibana一起部署,kibana可以把Elasticsearch采集到的数据通过dashboard(仪表板)可视化展示出来。Kibana允许你通过Web界面浏览Elasticsearch日志数据,也可自定义查询条件快速检索出elasticccsearch中的日志数据。
3)Fluentd:是一个流行的开源数据收集器,我们在 Kubernetes 集群节点上安装 Fluentd,通过获取容器日志文件、过滤和转换日志数据,然后将数据传递到 Elasticsearch 集群,在该集群中对其进行索引和存储。
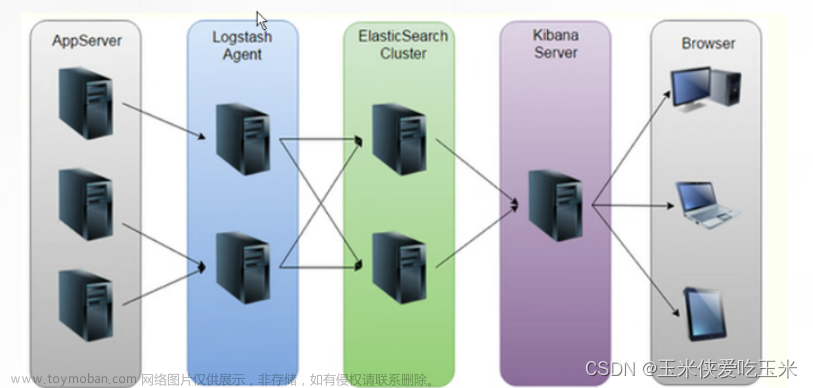
1.2、ELK Stack
1)Elasticsearch:日志存储和搜索引擎,它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。
2)Logstash:是一个完全开源的工具,他可以对你的日志进行收集、过滤,并将其存储供以后使用(支持动态的从各种数据源搜集数据,并对数据进行过滤、分析、丰富、统一格式等操作。)。
3)Kibana :是一个开源和免费的工具,Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助您汇总、分析和搜索重要数据日志。
ELK
考虑到聚合端(日志处理、清洗等)负载问题和采集端传输效率,一般在日志量比较大的时候在采集端和聚合端增加队列,以用来实现日志消峰。
1.3、ELK+filebeat
ELK+filebeat
Filebeat(采集)—> Logstash(聚合、处理)—> ElasticSearch (存储+检索)—>Kibana (展示)
1.4、其他方案
ELK日志流程可以有多种方案(不同组件可自由组合,根据自身业务配置),常见有以下:文章来源:https://www.toymoban.com/news/detail-812453.html
1)Logstash(采集、处理)—> ElasticSearch (存储)—>Kibana (展示) 2)Logstash(采集)—> Logstash(聚合、处理)—> ElasticSearch (存储)—>Kibana (展示) 3)Filebeat(采集、处理)—> ElasticSearch (存储)—>Kibana (展示) 4)Filebeat(采集)—> Logstash(聚合、处理)—> ElasticSearch (存储)—>Kibana (展示) 5)Filebeat(采集)—> Kafka/Redis(消峰) —> Logstash(聚合、处理)—> ElasticSearch (存储)—>Kibana (展示)文章来源地址https://www.toymoban.com/news/detail-812453.html
到了这里,关于logstack 日志技术栈-01-ELK/EFK 入门介绍 ELK+filebeta的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!