MySQL调优分析
explain;show status查看服务器状态信息
优化
减少子任务,减少子任务执行次数,减少子任务执行时间(优,少,快)
查询优化分析方法
1.访问了太多的行和列:确认应用程序是否在检索大量超过需要的数据。这通常意味着访问了太多的行,但有时候也可能是访问了太多的列。
2.分析了太多的数据行:确认 MySQL服务器层是否在分析大量超过需要的数据行。
sql优化
1.减少查询的记录:使用select语句查询大量结果,然后再获取前N行(如新闻网站,取100条记录,只显示前面的10条;取最值),这时可以使用limit(limit 1,10;从1开始10行)
2.减少查询的列:不要总是SELECT *取出全部列,会额外消耗I/O、内存,CPU。
3.重复查询相同的数据:可以将数据缓存起来需要再取出
4.切分查询:有时需要将大查询切分为多个小查询。
删除旧数据:
定期地清除大量数据时,如果用一个大的语句一次性完成的话,则可能需要一次锁住很多数据、占满整个事务日志、耗尽系统资源、阻塞很多小的但重要的查询。将一个大的 DELETE语句切分成多个较小的查询可以尽可能小地影响MySQL性能,同时还可以减少MySQL复制的延迟。
分解关联查询:


查询执行的基础
5.尽量用外连接代替子查询:通过测试来验证
6.尽量不要排序,文件排序很损耗性能,尽量使用索引排序。
7.尽量不要使用in,会导致全表扫描,可以用between
确定了查询只返回需要的数据后,看是否扫描了额外的数据
查询开销
对于MySQL,最简单的衡量查询开销的三个指标如下:
1.响应时间
2.扫描的行数
3.返回的行数


如果发现查询需要扫描大量的数据但只返回少数的行,那么通常可以尝试下面的技巧去优化它:
1.使用索引覆盖扫描,把所有需要用的列都放到索引中,这样存储引擎无须回表获取对应行就可以返回结果了。
2.改变库表结构。例如使用单独的汇总表。
3.重写这个复杂的查询,让 MySQL优化器能够以更优化的方式执行这个查询。
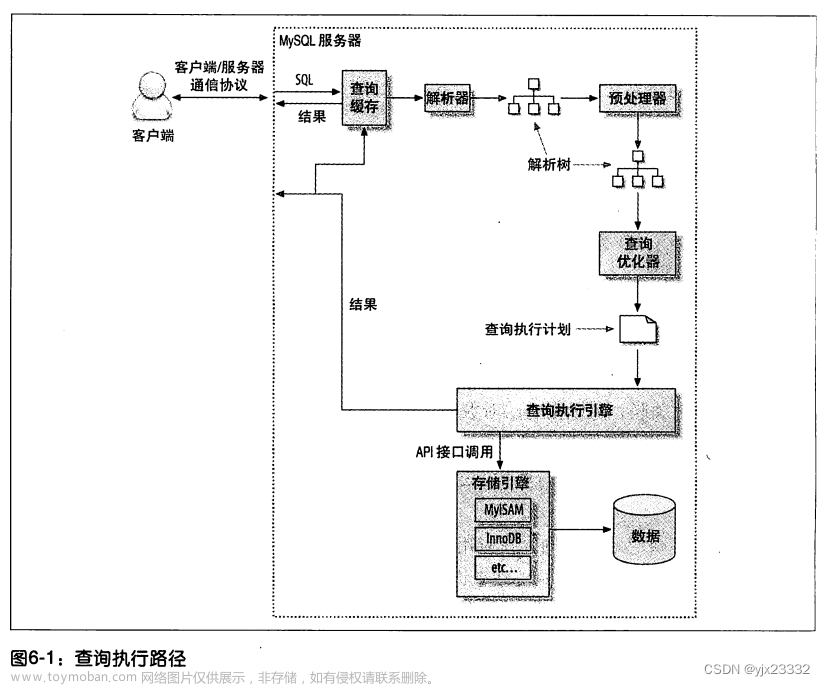
查询执行的过程

查询过程
1.客户端发送一条查询给服务器。
2.服务器先检查查询缓存,如果命中了缓存,则立刻返回存储在缓存中的结果。否则
进入下一阶段。
3.服务器端进行SQL解析、预处理,再由优化器生成对应的执行计划。
4. MySQL根据优化器生成的执行计划,调用存储引擎的API来执行查询。
5.将结果返回给客户端。
Mysql客服端/服务端通信协议:
“半双工”的,同一时刻只能一方发送数据


查询状态
Show full processlist(返回结果的command列为当前状态)


查询缓存
在解析一个查询语句之前,如果查询缓存是打开的,那么MySQL会优先检查这个查询是否命中查询缓存中的数据。这个检查是通过一个对大小写敏感的哈希查找实现的。查询和缓存中的查询即使只有一个字节不同,那也不会匹配缓存结果#",这种情况下查询就会进入下--阶段的处理。
如果当前的查询恰好命中了查询缓存,那么在返回查询结果之前MySQL会检查一次用户权限。这仍然是无须解析查询SQL语句的,因为在查询缓存中已经存放了当前查询需要访问的表信息。如果权限没有问题,MySQL会跳过所有其他阶段,直接从缓存中拿到结果并返回给客户端。这种情况下,查询不会被解析,不用生成执行计划,不会被执行。
查询优化处理
查询的生命周期的下一步是将一个SQL转推成一个执行计划,MySQL再依照这个执行计划和存储引擎进行交互。这包括多个子阶段:解析SQL、预处理、优化SQL执行计划。这个过程中任何错误(例如语法错误)都可能终止查询。
语法解析器和预处理
首先,MySQL通过关键字将SQL语句进行解析,并生成一棵对应的“解析树”。MySQL解析器将使用MySQL语法规则验证和解析查询。例如,它将验证是否使用错误的关键字,或者使用关键字的顺序是否正确等,再或者它还会验证引号是否能前后正确匹配。
预处理器则根据一些MySQL规则进一步检查解析树是否合法,例如,这里将检查数据表和数据列是否存在,还会解析名字和别名,看看它们是否有歧义。
下一步预处理器会验证权限。这通常很快,除非服务器上有非常多的权限配置。
查询优化器
现在语法树被认为是合法的了,并且由优化器将其转化成执行计划。一条查询可以有很多种执行方式,最后都返回相同的结果。优化器的作用就是找到这其中最好的执行计划。MySQL使用基于成本的优化器,它将尝试预测一个查询使用某种执行计划时的成本,并选择其中成本最小的一个。最初,成本的最小单位是随机读取一个4K数据页的成本,后来(成本计算公式)变得更加复杂,并且引入了一些“因子”来估算某些操作的代价,如当执行一次MERE条件比较的成本。可以通过查询当前会话的Last_query_cost的值来得知MySQL计算的当前查询的成本。
Mysql能处理的优化类型:
重新定义关联表的顺序,
将外连接转化为内连接,
使用等价变换规则,
优化count,min,max,
预估并转换为常数表达式,
覆盖索引扫描,
子查询优化
提前终止查询
等值传播
列表in()的比较
执行关联查询
当前MySQL关联执行的策略很简单:MySQL对任何关联都执行嵌套循环关联操作,即MySQL先在一个表中循环取出单条数据,然后再嵌套循环到下一个表中寻找匹配的行,依次下去,直到找到所有表中匹配的行为止。然后根据各个表匹配的行,返回查询中需要的各个列。MySQL会尝试在最后一个关联表中找到所有匹配的行,如果最后一个关联表无法找到更多的行以后,MySQL返回到上一层次关联表,看是否能够找到更多的匹配记录,依此类推迭代执行。

关于MylSAM的神话
MyISAM的COUNT()函数总是非常快,不过这是有前提条件的,即只有没有任何WHERE条件的COUNT(*)才非常快,因为此时无须实际地去计算表的行数。MySQL可以利用存储引擎的特性直接获得这个值。如果 MySQL 知道某列col不可能为NULL值,那么MySQL内部会将COUNT(col)表达式优化为COUNT(*)。


优化关联查询

文章来源:https://www.toymoban.com/news/detail-813044.html
使用用户自定义变量

 文章来源地址https://www.toymoban.com/news/detail-813044.html
文章来源地址https://www.toymoban.com/news/detail-813044.html
到了这里,关于MySQL夯实之路-查询性能优化深入浅出的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!