先大概分析了现阶段加速DETR训练的两条线:
1)改进cross-attention部分,关注更有效的feature
2)稳定二分图匹配
这篇论文用到的方法是从第二条线出发,稳定二分图匹配,但是并不像DN那样去噪训练稳定匹配,而是通过引入更多的监督。
一、motivation:
1)稳定二分图匹配
2)传统目标检测中一对多分配的性能好
二、innovation
通过将一对多分配解耦为多组一对一分分配来引入更多的监督。
三、方法
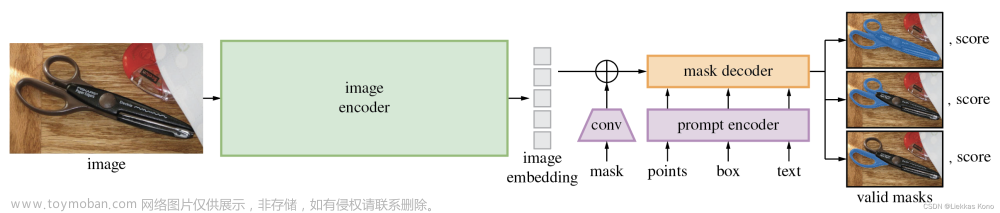
 先说一下上图abc:
先说一下上图abc:
【c】:直接进行原始一对多分配,这里把decoder画一整个就是指decoder里面的self-attention和cross-attention和FNN都是所有query一起的;
【b】:在c的基础上进行分组,每组一对一分配,这里的self-attention也是所有query一起;
【a】:分组,每组进行一对一,但是这里不一样的点在于画了很多个decoder是指每个组内单独进行self-attention,然后cross-attention和FNN就可以一起(因为cross-attention是encoder的输出和query进行交互,query之间并不会进行交互,所以作者此举本质上是让组和组之间的query不要进行交互)
本文提出的group-detr采用的就是方法a啦!
1.architecture

1)每组单独进行self-attention: (SA即self-attention)
(SA即self-attention)
2)然后一起cross-attention & FNN(因为这两个中,query之间是没有交互的,所以是可行的),如下列公式

ps.参数共享!
2.Loss Function
 (σk(·)是第k个解码器的N个query对应GT的最优排列)
(σk(·)是第k个解码器的N个query对应GT的最优排列)
下面是论文中的一些详细分析:主要集中于group detr中的稳定一对一分配、query增强、加强了encoder和decoder、内存的占用情况。
3.analysis
1)参数共享:
(作者在论文里提到,group detr可以看成同时训练K个detr模型,所以encoder、decoder、FNN都是共享权重的,但是其实不这样理解也行我觉得),主要是指在group detr中权值共享,所以会有更多反向传播的梯度-->train fast & better &stable
同时也给了下图来指出该方法的附加作用:一对一匹配更稳定(这个IS越低表示匹配更稳定,IS这个指标是在DNdetr中提出,具体可以去看DN detr),但是其实这个有点相辅相成的感觉,因为匹配更稳定也就意味着收敛更快,就train fast了。

2)query增强:
直接用图说话,一个GT里面好多点,就是group detr的一对多,可以看到匹配到同一个GT的都是相似的,每组得到的AP差不多,然后global Loss=loss[原始detr]+loss[group detr],即lossfunction有更多分量,所以group里面的query可以当成是原始detr中query的数据增强,这里叫做query增强。


3)加强了encoder和decoder(其实这里也可以用前面提到的更多反向传播的梯度来解释)
ok继续看图说话:用的conditional detr去训练完整个model;(a)encoder不重新训练,decoder重新训练一下;(b)encoder不重新训练,decoder加上group去训练;(c)encoder和decoder都加上group去重新训练; --> 由图得a<b即加强了decoder,b<c加强了encoder。

4)算力&内存
采用机制就是用并行的self-attention,即单独的self-attention取代原始的全部一起self-attention,然后cross-attention和FNN用的单个解码器和FNN就可以不用并行(以防大家云里雾里,再把图放上来一遍吧,知道的就当我爱啰嗦吧)

当然采用self-attention的并行处理带来计算量增加和训练时间加长是必不可免,但是其实采用这种策略gpu并没有升很多。(另外论文里也非常严谨地证明了group性能提高和训练时长的增加无关,实验指明再和baseline相似的时长性能更高,具体可以看论文)

5)这里提到了DN-DETR【简单带过,通过在GT加上noise来作为正查询去train,从而可以提高box回归和分类】,因为dn-detr的去噪训练其实跟作者的分组有点像。但是DN-detr对于重复预测是没有作用的因为都是正样本,groupdetr是自学习,就可以进一步去除重复预测,直接看图,这里主要指出DN-dtr和group之间是互补的

四、实验
1.
(1)实验部分就不多细说了,group加到detr的一些变体上性能都提升,可见其泛化性
一个12epoch,一个36/50epoch


(2)放在3D目标检测和实例分割


2.消融实验
1.一对多分配 & 单独的self-attention
b没有NMS有大量重复预测精度很低;(b)VS(c)说明o2m有效;(c)VS(d)说明单独的自注意力有效
(o2m:一对多;a是原始detr;b的native指原始的一对多;Sep.SA:单独的自注意力)
2.group数量
不断增加到11趋于稳定 --> K=11文章来源:https://www.toymoban.com/news/detail-813179.html
 文章来源地址https://www.toymoban.com/news/detail-813179.html
文章来源地址https://www.toymoban.com/news/detail-813179.html
到了这里,关于Group DETR论文阅读笔记的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!




![[论文阅读笔记18] DiffusionDet论文笔记与代码解读](https://imgs.yssmx.com/Uploads/2024/01/401181-1.png)