爬虫—响应页面乱码问题解决方法
案例:腾牛网图片抓取
源代码如下:
import requests
url = 'https://www.qqtn.com/wm/meinvtp_1.html'
headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'
}
res = requests.get(url, headers=headers
data = res.content.decode()
print(data)
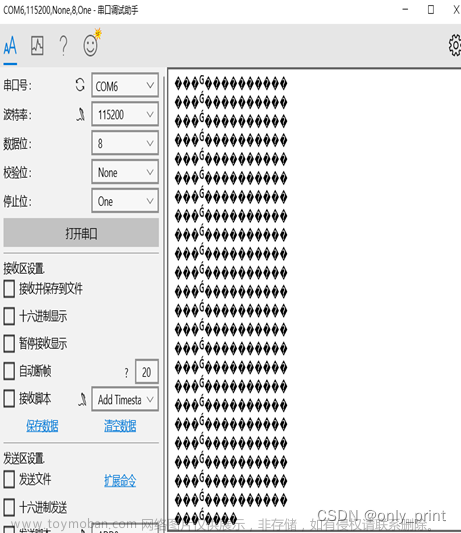
执行之后,报错如下:

解决办法:
- 方法一,设置解码格式为’GBK’
data = res.content.decode('GBK')
print(data)
运行结果如下:文章来源:https://www.toymoban.com/news/detail-813181.html
 文章来源地址https://www.toymoban.com/news/detail-813181.html
文章来源地址https://www.toymoban.com/news/detail-813181.html
- 方法二,自动获取解码格式
# 自动获取解码格式
res.encoding = res.apparent_encoding
data = res.text
print(data)
到了这里,关于爬虫—响应页面乱码问题解决方法的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!