合规是数据入表的前提。当前爬虫数据是非常敏感的,因为爬虫极容易造成两大不合规的问题:一是没有经过个人同意获取数据,二是爬取的数据里可能含有个人敏感信息也是一个问题。现在法律对于这部分非常严苛,如果企业里有50条未获得授权的个人信息就已经处于高危边缘,一旦违规出售或传播,立马就构成刑事犯罪了。
所以如果企业想将爬取的数据入表的话,必须先确定这些数据是否满足以下几大合规性要求:
1、是否侵犯个人权利
《网络安全法》中严格要求企业依法依规处理个人数据。如果企业通过绕行或强行突破反爬虫措施抓取个人数据,可能构成“窃取或以其他非法方式获取个人信息的违法行为”,情节严重的,可能构成侵犯公民个人信息罪。
建议企业企业通过构建协议许可及完整的授权链路确保数据权属关系和数据来源的合规。
协议许可:遵守被爬取方的Robots 协议,如若面对不合理的Robots协议,可以尝试走“协商-通知”路径,向被爬方提出书面修改Robots协议、准许其爬虫抓取的请求。
三重授权:如爬取数据涉及用户的个人信息,建议遵守“用户授权平台+平台授权爬取方+用户授权爬取方”的三重授权原则进行抓取。
抓取数据涉及个人信息的,需要遵循《个人信息保护法》规定,按照个人信息的不同类型,依法进行处理:
针对非公开个人信息:应当履行“告知-同意”流程,取得个人明示同意;
针对公开个人信息:对于个人明确提出拒绝的,应当及时撤回或删除相关个人信息;若处理已公开的个人信息,对个人权益有重大影响的,还应当取得个人同意。
2、是否存在不正当竞争的法律风险
爬虫获取的公共数据的使用需遵循“合法、必要、正当”原则,注重信息时效、保障信息质量和敏感信息校验等,否则将可能因不当利用而构成不正当竞争。爬虫技术可以使企业更加便捷地从政府部门等公开信息披露的平台与网站采集可为己所用的公共数据,这些信息与资讯经企业汇聚、整合与加工处理,形成企业的重要财富。但企业在使用公共数据进行商业化利用的过程中,如未尽必要注意义务导致原始数据主体合法权益受损的,将承担相应的法律责任。
3、数据管理是否合规
爬虫数据进入到企业数据库,做好数据分级分类,确保数据的合规管理是企业进行数据管理的必要措施,
《中华人民共和国网络安全法》等相关法律法规均对企业的数据管理提出了明确要求。例如,对数据实行分类分级管理;处理重要数据应当明确数据安全负责人和管理机构;对重要数据处理活动定期开展风险评估等。
4、数据相关业务运营是否合规
爬虫数据进行加工使用,对外形成商业互产品,对企业的业务体系,商业模式的合规性要求很高,需要确保爬虫数据的授权链路完整性,数据资产权属关系清晰,确保爬虫数据在数据资产目录中可追溯,可查询,权属清晰。
企业在开展和数据相关的业务时还应当依照相关法律法规取得相应的资质证照。例如,对于通过互联网平台的方式获取数据的企业,应当获得互联网相关业务所需的增值电信业务等相关证照,倘若企业提供的服务具有舆论属性或者社会动员能力,企业在向公众提供前还应当进行安全评估,并按照《互联网信息服务算法推荐管理规定》履行算法备案手续。
对于爬虫获取数据,如果已经满足上述合规性要求,企业如果想进行入表的话,可以参考以下路径:
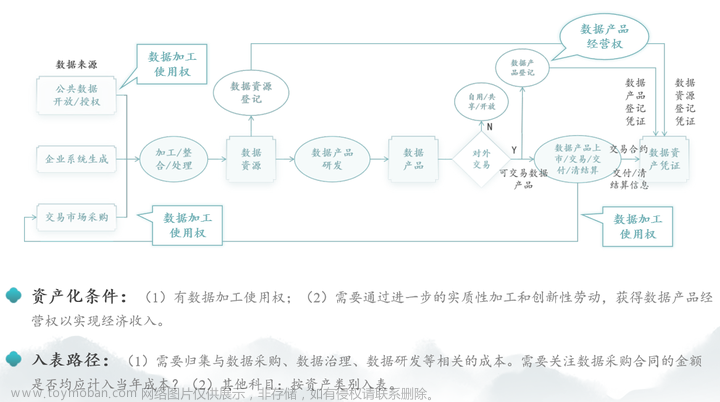
点击输入图片描述(最多30字)
爬取来的数据需满足数据资产化条件:(1)有数据加工使用权;(2)需要通过进一步的实质性加工和创新性劳动,获得数据产品经营权以实现经济收入。
入表路径:(1)需要归集与数据采购、数据治理、数据研发等相关的成本。需要关注数据采购合同的金额是否均应计入当年成本。(2)其他科目:按资产类别入表。文章来源:https://www.toymoban.com/news/detail-813443.html
在数据入表的过程中,无论是资产评估、质量评估还是价值评估,都需要涉及到专业化的服务机构的参与,以提供各类专业咨询。亿信华辰拉通各生态伙伴成立“数据资产入表服务链合体”,为客户提供数据资产入表及数据资产交易等一站式解决方案,包括:咨询规划、数据资产管理、会计审计、法律咨询、安全监管等能力,为企业提供专业化服务,全程指导企业有效地进行数据入表工作。如有数据入表需求,欢迎私信联系。文章来源地址https://www.toymoban.com/news/detail-813443.html
到了这里,关于爬取的数据可以入表吗?怎样入表?的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!