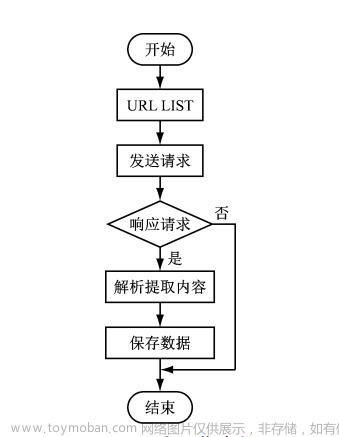
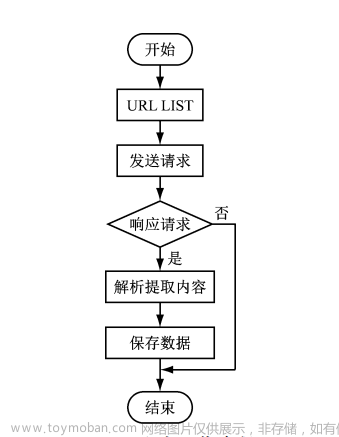
流程图:

1.读数据表
首先,读取数据集。
| CRIM | ZN | INDUS | CHAS | NOX | RM | AGE | DIS | RAD | TAX | PTRATIO | B | LSTAT | target |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.00632 | 18 | 2.31 | 0 | 0.538 | 6.575 | 65.2 | 4.09 | 1 | 296 | 15.3 | 396.9 | 4.98 | 24 |
| 0.02731 | 0 | 7.07 | 0 | 0.469 | 6.421 | 78.9 | 4.9671 | 2 | 242 | 17.8 | 396.9 | 9.14 | 21.6 |
| 0.02729 | 0 | 7.07 | 0 | 0.469 | 7.185 | 61.1 | 4.9671 | 2 | 242 | 17.8 | 392.83 | 4.03 | 34.7 |
| 0.03237 | 0 | 2.18 | 0 | 0.458 | 6.998 | 45.8 | 6.0622 | 3 | 222 | 18.7 | 394.63 | 2.94 | 33.4 |
| 0.06905 | 0 | 2.18 | 0 | 0.458 | 7.147 | 54.2 | 6.0622 | 3 | 222 | 18.7 | 396.9 | 5.33 | 36.2 |
读取数据集之后,通过了解各个字段的具体含义,详细含义可见此处。可以初步将房价以外的13个字段大致分为四类用于探索其与房价之间的关系,四类分别为:房屋房间数(包含字段RM)、居民质量(包含字段LSTAT,B,CRIM以及PTRATIO)、周边交通情况(包含字段DIS,RAD)、以及环境问题(包含字段CHAS)。接下来的可视化分析将基于以上四大类开展,逐一分析其分布情况与该类字段与波士顿地区房价的关系。
2.字段基本统计信息
查看数据集中各个字段的样本数、均值、标准差、最小值、四分位数等基本信息。
| CRIM | ZN | INDUS | CHAS | NOX | RM | AGE | DIS | RAD | TAX | PTRATIO | B | LSTAT | target | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 样本数 | 506 | 506 | 506 | 506 | 506 | 506 | 506 | 506 | 506 | 506 | 506 | 506 | 506 | 506 |
| 均值 | 3.6135235573 | 11.3636363636 | 11.1367786561 | 0.0691699605 | 0.5546950593 | 6.2846343874 | 68.5749011858 | 3.7950426877 | 9.5494071146 | 408.2371541502 | 18.4555335968 | 356.6740316206 | 12.6530632411 | 22.5328063241 |
| 标准差 | 8.6015451053 | 23.3224529945 | 6.8603529409 | 0.2539940413 | 0.1158776757 | 0.7026171434 | 28.1488614069 | 2.1057101266 | 8.7072593842 | 168.537116055 | 2.1649455237 | 91.2948643842 | 7.1410615113 | 9.1971040874 |
| 最小值 | 0.00632 | 0 | 0.46 | 0 | 0.385 | 3.561 | 2.9 | 1.1296 | 1 | 187 | 12.6 | 0.32 | 1.73 | 5 |
| 下四分位数 | 0.082045 | 0 | 5.19 | 0 | 0.449 | 5.8855 | 45.025 | 2.100175 | 4 | 279 | 17.4 | 375.3775 | 6.95 | 17.025 |
| 中位数 | 0.25651 | 0 | 9.69 | 0 | 0.538 | 6.2085 | 77.5 | 3.20745 | 5 | 330 | 19.05 | 391.44 | 11.36 | 21.2 |
| 上四分位数 | 3.6770825 | 12.5 | 18.1 | 0 | 0.624 | 6.6235 | 94.075 | 5.188425 | 24 | 666 | 20.2 | 396.225 | 16.955 | 25 |
| 最大值 | 88.9762 | 100 | 27.74 | 1 | 0.871 | 8.78 | 100 | 12.1265 | 24 | 711 | 22 | 396.9 | 37.97 | 50 |
根据数据字段的基本统计信息,可以得出此数据集中所有的字段包含506个样本数,因此数据集不存在缺失值的情况。通过结合均值、标准差、最小值和下四分位数可以发现字段AGE最小值在2.9,但是均值达到68.6左右,因此可以后续用箱线图探究此字段中数值的合理性。同样,通过查看数据基本信息可以初步判断出其他字段的数据较为合理。
判断完字段的合理性之后对数据大致的波动性以及离散程度进行预估,其中字段CRIM,ZN,RAD,DIS的标准差高于或接近均值,可以看出以上字段的波动性较大,初步判断波士顿地区存在房源质量差距较大的现象,预测会有一些较为优质房源以及一些质量非常低的房源。因此,在后续进行可视化分析的时候着重定位优质房源。
3.平均房价直方图
读取数据集、查看各个字段的基本信息以及验证各个字段的数据合理性之后将具体分析该案例。由于此案例针对波士顿的房价,因此可以将重心定位在探究波士顿房价的影响因素,重点分析字段target。
首先,通过绘制平均房价的直方图探究波士顿地区的房价的基本情况。

从该直方图中可以得知在波士顿地区18500美元的房价最多,集中分布在14000美元到23000美元,存在少量高房价房源。接下来可以通过绘制箱线图具体查看较高房价房源的情况。
4.平均房价箱线图
通过直方图分析完波士顿地区平均房价之后,接着通过箱线图查看字段target的最大值、最小值、四分位数以及异常点,目的是初步了解波士顿地区房价的具体分布情况并查看异常点的值。

5.自用房屋比例的箱线图
由于数据字段基本信息统计中字段AGE的数值相对较为异常,因此可以通过箱线图进一步验证该字段数据的合理性。

8 平均房间数与房价的散点图
想要探究影响这些波士顿房价异常高的原因,先进行假设房价异常高的直接影响因素是房间数较多,占地面积较大。为了证明这一假设 的准确性,将绘制数据集中字段
的准确性,将绘制数据集中字段RM与target的散点图探究平均房间数与房价之间的相关性。
已知在波士顿地区,距离市中心的远近程度在很大程度上并不影响房屋的均价之后,将探究距离辐射公路是否影响房屋的均价。因此,通过绘制距离辐射公路与房价的散点图进行查看。文章来源:https://www.toymoban.com/news/detail-813512.html
 文章来源地址https://www.toymoban.com/news/detail-813512.html
文章来源地址https://www.toymoban.com/news/detail-813512.html
到了这里,关于数据分析实战:城市房价分析的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!