资源分享
1、可在公众号「技术狂潮AI」中回复「GPTs」可获得 「GPTs Top100 深度体验分析报告」PDF 版报告,由椒盐玉兔第一时间输出的一份非常详细的GPTs体验报告。
2、可在公众号「技术狂潮AI」中回复「大模型案例」可获得 「720-2023大模型落地应用案例集」PDF 版报告,主要包含大模型2023年国内落地应用案例集。
3、可在公众号「技术狂潮AI」中回复「AIGC2024」可获得 「硅创社2024001-AIGC2023~2024跨年报告V1.0(by潘工@20240101)」PDF 版报告,主要内容包括AIGC 2023 回顾:100项(大事件)和AIGC 2024 展望: 32项(路线图)。
关键点
-
专家混合 (MoE) 架构:Mixtral 8x7B 创新地采用了 MoE 架构,该架构拥有八位“专家”和七十亿参数,能够将数据高效地分配给各自擅长处理特定任务的神经网络部分。这种设计使得模型训练和运算更为高效,体现了 Mistral AI 对于尖端架构的追求。
-
高效处理与模型大小的优化:Mixtral 8x7B 特别强调处理效率,在进行推理时每个 Token 只需调用两位“专家”,这样既保证了运算速度,又没有牺牲性能。与参数量高达 467 亿的 GPT-4 等大型模型相比,Mixtral 8x7B 更小的模型体积展现了 Mistral AI 对实用性的重视。
-
多功能应用和多语言支持:Mixtral 8x7B 在多种任务中都有出色表现,无论是组合任务、数据分析、问题解决还是编程辅助。它对法语、德语、西班牙语、意大利语和英语的多语言支持,使其能够满足不同用户的需求。
-
非常规开发历程和精细调优:Mistral AI 采用了使用 torrent 分发的非常规发布策略,这与其他 AI 产品的精心策划发布形成了鲜明对比,并在 AI 社区中引发了关于开源模型角色的讨论。AI 社区对该模型进行了快速的逆向工程,并对特定版本进行了细致的调优,这不仅证明了模型的灵活性,也展现了开发过程中的协作精神。
-
未来展望与持续优化:Mistral AI 对持续提升性能的承诺,将 Mixtral 8x7B 定位为持续进化中的语言模型领跑者。期待未来的改进、功能扩充和适应性增强,Mistral AI 的前瞻性布局预示着 AI 技术的不断前进。
法国新兴企业Mistral AI,在2023年成立,市值已达到20亿美元。它最近推出的大语言模型Mixtral引起了广泛关注,这不仅因为它在技术上的先进性,更因为它打破了谷歌、Meta和OpenAI长期以来在这一领域的主导地位。
本文将带您深入了解Mixtral 8x7B的架构、发展历程及其技术细节,揭示其主要特点和应用场景。我们还将探讨这一模型与其他模型的比较优势、其多方面的应用潜力以及未来发展的可能性。
一、Mixtral 8x7B的关键特性
Mistral AI打造的Mixtral 8x7B是目前市场上最具竞争力的开放式大型模型之一,它拥有多项独特功能,明显区别于其他模型。接下来,我们将探索构成Mixtral 8x7B独特之处的架构、处理效率、模型规模、上下文处理能力和授权方式。
1.1、专家混合(MoE)架构
Mixtral 8x7B的核心是它那颇具创新性的专家混合(MoE)架构。这种设计通过一个网关网络,将输入数据分配给被称为“专家”的特定神经网络组件。在Mixtral 8x7B中,共有八个这样的专家,每个都有着高达70亿的模型参数。
这种MoE结构大大提高了模型训练和运算的效率及可扩展性。它通过激活专门处理输入数据不同方面的专家,显著提升了计算效率。
1.2、8个专家共享70亿参数
模型的名称“8x7B”直观地反映了其结构——由八个各自拥有70亿参数的高质量稀疏专家混合体组成。这种专家团队的合作使Mixtral 8x7B在任务执行上表现出色,充分展示了团队协作的强大能力。
1.3、每个Token仅需2个专家即可高效处理
Mixtral 8x7B最引人注目的特点之一是其对处理效率的强调。尽管配备了八个专家,在实际运算时每个Token仅需两个专家参与。具体来说,Mixtral总共拥有467亿参数,但在处理每个Token时只会用到其中的129亿参数(相当于2个专家)。
这种精心设计的资源分配优化了处理速度,同时保持了模型性能。通过实施选择性激活专家机制,确保了计算资源得到合理利用,从而提升了整体效率。
1.4、与GPT-4相比,减少了模型大小和参数
Mixtral 8x7B 通过采用更小的模型尺寸,在策略上与像 GPT-4 这样的大型模型区分开来。尽管其名称可能让人误以为它在参数数量上直接与 GPT-4 相当,但实际上这个名称有些误导人。
8x7B 模型只是在 Transformer 的前馈 (FeedForward) 块数量上增加了八倍,并且共享了注意力机制 (attention) 的参数,使得总参数数维持在 467 亿。这种缩减的模型尺寸并未影响模型的性能,反而凸显了 Mistral AI 在实际应用中优化模型的承诺。
1.5、32K Token 的上下文窗口以确保强大性能
为了确保 Mixtral 8x7B 在各种任务上都能表现出色,它维持了一个庞大的 32K Token 的上下文窗口。这样宽广的上下文容量使得模型能够理解和分析复杂的模式,适合于各种应用场景,从组合任务到数据分析再到软件故障排除。
1.6、开放权重与灵活的 Apache 2.0 许可
Mixtral 8x7B 受欢迎的一个重要原因是它坚持开放性原则。这个模型公开了权重数据,允许用户在比起其他公司封闭式 AI 模型更为宽松的条件下使用它。更进一步,Mistral AI 选择了灵活性更强的 Apache 2.0 许可证来管理 Mixtral 8x7B,彰显了它致力于打造一个合作共赢、便捷易用的 AI 生态系统。
Mixtral 8x7B 的几个关键特点,包括它那革新性的 MoE 架构、高效处理能力、经过优化的模型体积、扩展性强的上下文处理能力以及开源策略,共同铸就了它在大语言模型领域的先锋地位。这些特点不仅促进了它卓越的性能,也体现了 Mistral AI 旨在普及先进 AI 技术,使之更加普及和易于应用的愿景。
二、发展之旅
Mixtral 8x7B 的发展历程是一段充满创新、战略选择和追求开放性的旅程。从一开始就不走寻常路的发布策略,到后期的精细调优,模型的成长历程展示了 Mistral AI 不断突破大语言模型极限的坚定决心。
2.1、通过 Torrents 的独特发布策略
Mistral AI 采取了一条不同寻常的道路,通过使用 torrents(一种点对点文件分享技术)来发布其 Mixtral 8x7B,而不是走传统的发布途径。这种突破常规的做法在 AI 领域引起了不小的震动,它不仅展示了 Mistral 的创新思路,还引发了人们对 AI 技术未来走向的广泛讨论。
2.2、初次发布后几小时内迅速实现逆向工程
在 Mixtral 8x7B 刚一发布的几小时内,AI 社区的爱好者和开发者就迅速展现了他们的敏捷和合作精神,对其进行了逆向工程。这种快速的行动力证明了 AI 社区的反应速度和参与热情,也凸显了这个模型在促进开发者迅速动态反应方面的重要作用。
2.3、专注于指令跟随版本的微调
开发者们深入研究 Mixtral 8x7B 的潜能时,一个重点是对其进行微调,特别是针对那些能够跟随指令操作的版本。这种细致入微的调整体现了模型在专业任务上的灵活适应性,为将模型的性能定制化以适应具体应用开辟了新路径。这些微调工作标志着模型进入了一个更加精细化和个性化的发展阶段,以满足各种用户的需求。
2.4、在 Fireworks.ai 平台的部署
在 Mixtral 8x7B 的发展历程中,一个重要里程碑是它被部署在 Fireworks.ai 平台上。这个新颖的平台提供了简洁且友好的用户体验,让用户可以在模型权重发布后不久就能快速接触到这个模型。与 Fireworks.ai 的合作是一次战略性布局,旨在提升模型的普及度,使其能够触及更广泛的受众群体。
2.5、持续进行性能优化
Mixtral 8x7B 的成长之旅并未止步于首次亮相,Mistral AI 正在积极地持续优化模型性能。这种不断追求完善的精神显示了他们致力于确保模型不仅要达到用户期望,更要超越期望。这种迭代优化的方法与 Mistral AI 提供高品质且不断进步的 AI 解决方案的目标是一致的。
Mixtral 8x7B 的成长之路记录了一系列大胆的选择、合作参与和不断完善。从它独树一帜的发布策略到在用户友好型平台上的部署,每一个步骤都凸显了 Mistral AI 让先进大语言模型更易于被大众接触、鼓励社区参与模型演进,并持续致力于提升模型性能的愿景。
三、比较分析
在当今众多强大的大语言模型 (Large Language Model) 中,Mistral AI 推出的 Mixtral 8x7B 成为了一名值得关注的强力选手。将它与其他模型进行对比分析,我们可以发现 Mixtral 8x7B 独特的优势和显著的性能表现。
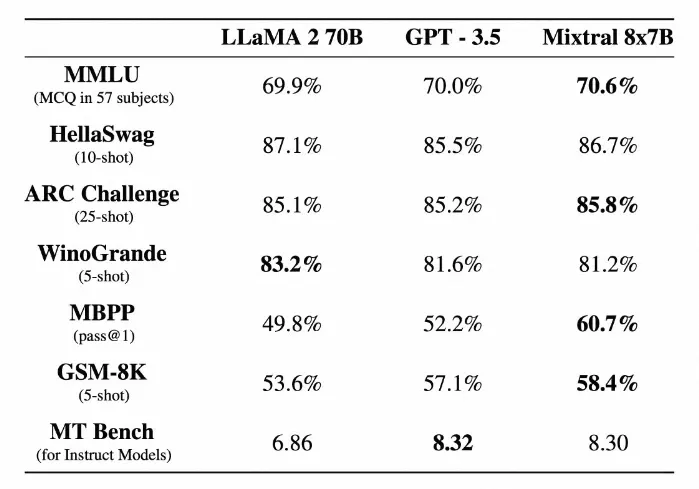
3.1、与 Llama 2 70B 和 GPT-3.5 的性能大比拼
Mistral AI 的 Mixtral 8x7B 不仅加入了这场技术竞赛,还直接挑战了业界的领军模型。性能大比拼显示,Mixtral 8x7B 在众多测试中表现出色,甚至在某些方面超越了像 Llama 2 70B 和 GPT-3.5 这样的重量级对手。在特定的性能测试中,Mixtral 的出色表现和高效性能得到了充分展示。



相较于 Llama 2,在 BBQ 性能测试中,Mixtral 表现出更少的数据偏差。整体上,Mixtral 在 BOLD 测试中展现的积极情绪更为突出,而且在不同维度上的表现差异也与 Llama 2 相似。 - Mistral AI
除了基本的性能测试,深入分析 Mixtral 8x7B 的效率和性能指标可以让我们更全面地了解它的实力。这款模型不仅能够高效处理长达 32K Token 的文本段落,而且在多种语言处理任务上都展现出了卓越的性能,这些都为其整体效率做出了贡献。
3.2、与市面上的私有大语言模型进行比较
这项性能测试凸显了一个开放科学模型在市场上已经确立名声的品牌中的重要性。经过特别调优的 Mixtral 在 MT-Bench 上取得了 8.30 的高分,不仅成为 LMSys 排行榜上最优秀的开源模型,而且通常比像 Google (Gemini Pro) 这样的知名品牌更加出色。
3.3、MoE架构与传统模型之比较
Mixtral 8x7B 的核心技术是它的“专家混合”(Mixture of Experts, MoE) 架构。通过比较 MoE 和传统模型,我们可以看到这种特殊设计方法带来的优势。
这种架构允许系统把数据分发给不同的专门化网络部分,也就是“专家们”,这样做可以使模型的训练和运作更高效、更易于扩展。当我们把拥有相同数量参数的 MoE 模型与传统的单体模型进行对比时,MoE 的高效性就显而易见。
3.4、缩小模型尺寸的策略和参数共享
Mixtral 8x7B 利用了缩减模型尺寸的策略,让它相比于假想中体积更大的模型,比如 GPT-4,拥有了更加易于管理的结构。特别是通过在“专家”之间共享参数,我们可以看到 Mistral AI 在设计上做出了周到的考量。模型在不牺牲性能的前提下实现了尺寸的减小,这一点在大语言模型领域中让它显得与众不同。
四、Mixtral 8x7B的应用领域
Mixtral 8x7B因其出色的适应能力在多个领域和任务中大放异彩,成为了一个多面手的强大工具。该模型特别擅长:
4.1、综合性任务
在处理需要综合能力的任务时,Mixtral 模型表现出其卓越的理解和创作能力。它先进的语言处理功能让它能够轻松应对复杂指令,并给出既连贯又切题的回答。
4.2、数据分析
Mixtral 8x7B凭借其庞大的参数规模和混合专家模式架构,在数据分析方面起到了关键作用。它能够洞察复杂数据之间的关联,提供有价值的见解,并助力于决策过程。
4.3、问题解决
无论是诊断技术难题、给出解决方案还是提供操作指南,Mixtral 8x7B都能在各种场合下展现其解决问题的实力。
4.4、编程支持
对于开发者和程序员而言,Mixtral 8x7B在理解和撰写代码片段方面提供了有力支持。它在编程任务中提供辅助,给出建议,大幅提升了开发流程的效率。
4.5、多语言支持
Mixtral 8x7B模型的一大亮点是其对多种语言的出色支持能力。无论是法语、德语、西班牙语、意大利语还是英语,这款模型都能轻松掌握,理解和创造内容。
这项能力让Mixtral 8x7B成为了一个跨文化交流的有力工具,帮助不同语言的用户之间实现流畅的沟通。
Mixtral 8x7B的应用范围非常广泛,它的多语言能力和显著的优势使其在人工智能领域中占据了领先地位。
五、Mixtral 8x7B技术规格
5.1、模型结构详情
Mixtral 8x7B拥有一个精心设计的架构,旨在提升性能和效率。模型结构的关键细节包括:
维度 (dim):它设定了4096的嵌入空间维度,这使得模型能够更高效地表达语言和上下文。
层数 (n_layers):该模型由32层组成,加深了它的学习深度和层次感。
头数 (n_heads):它包含了32个注意力头的多头注意力机制,这有助于并行处理信息,并捕捉输入信息的不同方面。
头维度 (head_dim):每个注意力头都有128的维度,使得模型能够关注输入数据中的特定模式和关系。
隐藏维度 (hidden_dim):14336的隐藏维度使得Mixtral 8x7B能够处理复杂的特征表达,增强了其表达能力。
键值头数 (n_kv_heads):8个键值头使得混合专家 (MoE) 架构运行更高效。
归一化Epsilon (norm_eps):设置为1e-05,以确保训练稳定性和性能一致性。
词汇量 (vocab_size):拥有32000大小的词汇量,覆盖了丰富的语言元素。
混合专家配置 (MoE):Mixtral 8x7B采用了一个包含8位专家的MoE架构,每位专家管理着70亿个参数。值得一提的是,在进行Token推断时,只需要2位专家参与,这大大提高了处理的效率。
5.2、GPU使用效率
在设计上,Mixtral 8x7B优化了GPU使用效率以提高性能。重点包括:
8位浮点数制度 (fp8):支持8位浮点数制度,这减少了内存需求并加快了计算速度,同时保证了准确性。
GPU兼容性:Mixtral 8x7B高效地利用GPU资源,兼容各种GPU配置。它可以有效地扩展到至少拥有86GB VRAM的GPU上。
5.3、Fireworks.ai上不同部署配置的适应性
在 Fireworks.ai 平台上,Mixtral 8x7B 展现了其适应不同部署配置的强大能力。这款模型能够无缝地融入 Fireworks.ai 环境,使用户能够针对各种应用场景发挥其强大功能。
Mixtral 8x7B 的技术规格展示了其精心打造的模型结构、高效的 GPU 使用策略,以及对各种部署环境的灵活适应。这些技术上的细微差别极大提升了模型的整体表现,让它在众多类似功能的新模型中脱颖而出。
5.4、适应性与数据整合
利用 Mixtral 的这些进步,快速适应性和训练框架的多用途性迅速崛起,催生了如 Dolphin 2.6 Mixtral-8x7B 和 OpenHermers Mixtral-8x7B 这样的高性能模型。这两款模型主要基于 OpenHermes 数据集,适用于多种任务。这些新优化的模型因提升了性能能力而受到赞誉,同时也因其“无节制”的本质和未经筛选的响应引发了道德上的担忧。
六、未来展望
Mistral AI 对持续提升性能的坚持使 Mixtral 8x7B 成为不断演进的语言模型领域的先锋。致力于改善和提升模型能力的承诺,体现了积极应对新兴挑战和用户需求的态度。Mistral AI 明白 AI 领域的动态变化,并积极参与持续的优化工作以提升 Mixtral 8x7B。
Mixtral 8x7B 的前景涵盖几个关键领域:
-
性能提升:Mistral AI 计划进一步提高模型性能,专注于监督式微调和潜在优化领域。这种承诺确保 Mixtral 8x7B 在各种应用中继续保持领先地位。
-
功能拓展:我们期待着潜在的发展和功能拓展,这些都有可能加大Mixtral 8x7B的应用范围。Mistral AI始终保持前瞻思维,不断探索新功能,以迎合用户需求和行业发展的新趋势。
-
自适应能力:随着AI应用不断演进,Mistral AI坚持不懈地提升Mixtral 8x7B的自适应能力。这意味着要实时跟进技术革新和用户反馈,不断更新模型,以增强其在多元化场景下的适应性。
七、总结
Mixtral 8X7B是Mistral AI公司在大语言模型领域的一次重大突破。它采用了一种名为"专家混合"(MoE)的架构,这种架构由8个专家组成,每个专家组有7个亿参数。这种高效的架构使得Mixtral能够在多个领域表现出色,具有出色的处理能力。
Mistra l对持续优化的坚定承诺,将确保Mixture 8X7在AI领域保持领导地位。随着 Mistral 不断优化和调整Mixture ,我们有理由相信,它将带来更多的突破,从而在人工智能和广泛行业中产生意义深远的影响。Mixture 不仅是人工智能技术领域的一次杰出成就,更是推动自然语言处理不断创新与进步的重要里程碑。
八、References
[1]. Mixtral of Experts: https://arxiv.org/pdf/2401.04088.pdf文章来源:https://www.toymoban.com/news/detail-813866.html
[2]. A high quality Sparse Mixture-of-Experts: https://mistral.ai/news/mixtral-of-experts/?utm_source=substack&utm_medium=email文章来源地址https://www.toymoban.com/news/detail-813866.html
到了这里,关于深入解析 Mistral AI 的 Mixtral 8x7B 开源MoE大模型的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!