1,演示视频
https://www.bilibili.com/video/BV1364y157EA/
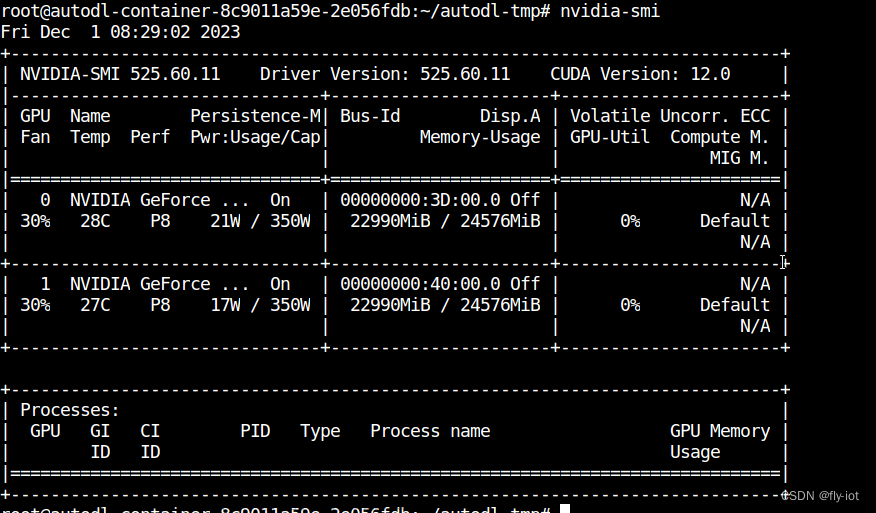
【deepseek】(1):12月1日新大模型deepseek发布!使用3080显卡,运行7b模型,可以正常运行WebUI了,速度9 words/s。
2,关于RTX 3080 Ti * 1卡,2021年的显卡
RTX 3080 Ti 拥有 34 TFLOPS 的着色器性能、67 TFLOPS 的光追性能、以及 273 TFLOPS 的 Tensor(Sparsity)性能。 该卡的外形设计,依然类似于现有的 RTX 3080 FE 公版显卡(双槽双面风冷散热器),但没有 RTX 3090 那样笨重(BFG),侧边仍是 12-pin 的 Microfit 辅助供电接口。
3,关于 deepseek-llm-7b-chat 的模型,12月1日上传
只有关于代码生成的部分:
https://zhuanlan.zhihu.com/p/666077213
https://www.modelscope.cn/models/deepseek-ai/deepseek-llm-7b-chat/summary
关于 DeepSeek
DeepSeek 致力于探索 AGI 的本质,不做中庸的事,带着好奇心,用最长期的眼光去回答最大的问题。
DeepSeek Coder 是深度求索发布的第一代大模型,在不久的将来,我们还将呈现给社区更多更好的研究成果。让我们在这个激动人心的时代,共同推进 AGI 的到来!
https://github.com/lm-sys/FastChat/blob/main/docs/model_support.md

3,使用autodl创建环境,安装最新的 fastchat
需要选择 python3.10 的镜像,否则会执行报错:
Miniconda conda3
Python 3.10(ubuntu22.04)
Cuda 11.8

apt update && apt install -y git-lfs net-tools
# 一定要保证有大磁盘空间:
cd /root/autodl-tmp
git clone https://www.modelscope.cn/deepseek-ai/deepseek-llm-7b-chat.git
# 最后安装
pip3 install "fschat[model_worker,webui]"
安装完成之后就可以使用fastchat启动了。
4,使用 fastchat 启动 deepseek-llm-7b-chat 模型
启动脚本:
# run_all_deepseek.sh
# 清除全部 fastchat 服务
ps -ef | grep fastchat.serve | awk '{print$2}' | xargs kill -9
sleep 3
rm -f *.log
# 首先启动 controller :
nohup python3 -m fastchat.serve.controller --host 0.0.0.0 --port 21001 > controller.log 2>&1 &
# 启动 openapi的 兼容服务 地址 8000
nohup python3 -m fastchat.serve.openai_api_server --controller-address http://127.0.0.1:21001 \
--host 0.0.0.0 --port 8000 > api_server.log 2>&1 &
# 启动 web ui
nohup python -m fastchat.serve.gradio_web_server --model-list-mode reload \
--controller-url http://127.0.0.1:21001 \
--host 0.0.0.0 --port 6006 > web_server.log 2>&1 &
## 启动 worker
nohup python3 -m fastchat.serve.model_worker --load-8bit --model-names deepseek-7b \
--model-path ./deepseek-llm-7b-chat --controller-address http://127.0.0.1:21001 \
--worker-address http://127.0.0.1:8080 --host 0.0.0.0 --port 8080 > model_worker.log 2>&1 &
sleep 2
tail -f model_worker.log
解决: 内存不够,增加参数 --load-8bit 解决:
2023-12-08 23:01:38 | ERROR | stderr | return t.to(device, dtype if t.is_floating_point() or t.is_complex() else None, non_blocking)
2023-12-08 23:01:38 | ERROR | stderr | torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 32.00 MiB (GPU 0; 11.76 GiB total capacity; 11.48 GiB already allocated; 27.19 MiB free; 11.49 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
启动成功:
2023-12-08 23:03:00 | INFO | model_worker | args: Namespace(awq_ckpt=None, awq_groupsize=-1, awq_wbits=16, controller_address='http://127.0.0.1:21001', conv_template=None, cpu_offloading=False, debug=False, device='cuda', dtype=None, embed_in_truncate=False, enable_exllama=False, enable_xft=False, exllama_gpu_split=None, exllama_max_seq_len=4096, gptq_act_order=False, gptq_ckpt=None, gptq_groupsize=-1, gptq_wbits=16, gpus=None, host='0.0.0.0', limit_worker_concurrency=5, load_8bit=True, max_gpu_memory=None, model_names=['deepseek-7b'], model_path='./deepseek-llm-7b-chat', no_register=False, num_gpus=1, port=8080, revision='main', seed=None, ssl=False, stream_interval=2, worker_address='http://127.0.0.1:8080', xft_dtype=None, xft_max_seq_len=4096)
2023-12-08 23:03:00 | INFO | model_worker | Loading the model ['deepseek-7b'] on worker c48d8d3f ...
0%| | 0/2 [00:00<?, ?it/s]
50%|███████████████████████████████████████████████████████████▌ | 1/2 [00:09<00:09, 9.91s/it]
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:36<00:00, 19.43s/it]
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:36<00:00, 18.01s/it]
2023-12-08 23:03:36 | ERROR | stderr |
2023-12-08 23:03:36 | INFO | model_worker | Register to controller
2023-12-08 23:03:36 | ERROR | stderr | INFO: Started server process [1864]
2023-12-08 23:03:36 | ERROR | stderr | INFO: Waiting for application startup.
2023-12-08 23:03:36 | ERROR | stderr | INFO: Application startup complete.
2023-12-08 23:03:36 | ERROR | stderr | INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
测速,反而提速了:
python3 -m fastchat.serve.test_throughput --controller-address http://127.0.0.1:21001 --model-name deepseek-7b --n-thread 1
Models: ['deepseek-7b']
worker_addr: http://127.0.0.1:8080
thread 0 goes to http://127.0.0.1:8080
Time (POST): 32.48344707489014 s
Time (Completion): 32.483508586883545, n threads: 1, throughput: 9.820367745890861 words/s.
测试中文输出正常:
curl http://localhost:8000/v1/chat/completions -H "Content-Type: application/json" -d '{
"model": "deepseek-7b",
"messages": [{"role": "user", "content": "北京景点"}],
"temperature": 0.7
}'
webui 启动正常了:文章来源:https://www.toymoban.com/news/detail-814075.html
5,总结
终于解决了webui的启动问题。模型发展的速度真的快。速度越来越快了。
deepseek的模型使用起来还可以。可以运行7b的模型了。
测试了几个简单的问题,还可以。7B模型经过 int8 量化,可以在 12G的3080TI 上面运行。文章来源地址https://www.toymoban.com/news/detail-814075.html
到了这里,关于【deepseek】(1):12月1日新大模型deepseek发布!使用3080显卡,运行deepseek-7b模型,可以正常运行WebUI了,速度9 words/s。的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!