- 基本功能。
(1) 使用开源的stemming程序把“reviewText”、“summary”、“title”、“feature”、“description”等中的tokens转换成terms。
答:
使用Java语言版本的Porter词干算法进行词干提取。成功将tokens转换成terms。
直接使用Porter官网提供的Java版代码。部分代码如下:

把Stemmer类导入信息检索程序同一个包中,并且对官方提供的代码进行修改。去除主函数。在Stemmer类内增加一种方法,以供主程序调用。这个方法的功能是输入一个小写的英文单词,返回这个英文单词的词干。

主函数的调用代码。这段代码的功能是把一个拆分好的String数组中的每一个单词进行词干提取并原位保存。

(2) 数据统计:以构建倒排索引的文档为基础,检验Heaps’ law和Zipf’s law在该数据集上是否正确,要求以曲线图或表格的方式来呈现,包含定量的结果。
答:
在构建倒排索引的同时记录数据。在构建倒排索引时,读入文档集的每一个文档,然后将每个文档都拆成单词,处理每一个单词构建倒排索引。在构建倒排索引过程中,记录词项数目和token数目。

存下每出现10000个词项时总共的词条数目。

记录tokens和terms数据绘制成表格。
| tokens |
10000 |
20000 |
30000 |
40000 |
50000 |
60000 |
70000 |
80000 |
90000 |
100000 |
| terms |
702 |
1172 |
1575 |
1881 |
2091 |
2253 |
2450 |
2636 |
2863 |
3037 |
| tokens |
110000 |
120000 |
130000 |
140000 |
150000 |
160000 |
170000 |
180000 |
190000 |
200000 |
| terms |
3224 |
3371 |
3494 |
3597 |
3647 |
3840 |
3921 |
3982 |
4096 |
4205 |
| tokens |
210000 |
220000 |
230000 |
240000 |
250000 |
260000 |
270000 |
280000 |
290000 |
298316 |
| terms |
4347 |
4450 |
4520 |
4628 |
4677 |
4772 |
4847 |
4881 |
4972 |
5005 |
令词条数为T ,词项数为M ,有Heap’s 定律如下:
进行等价变换有:
因此,对上表内数据取对数,绘制成对数图如下:

可见,30 组数据点基本上可以拟合成一条直线。利用excel 的趋势线工具自动拟合出直线方程y=0.5468x+0.73 ,因此,k=≈5.3703 ,b≈0.5468 。并且,拟合度R2=0.9906 ,非常接近于1 ,这说明拟合度很高。
虽然k 不符合30~100 的典型取值,但是实测数据和公式拟合得相当好。因此可以认为,我们成功地在Gift_Cards_5.json数据集上验证了Heap’s 定律。
接下来验证Zipf’s 定律。
用倒排列表的第一个值存储验证Zipf’s 定律需要的文档集频率。从第二个值开始存储倒排索引中的文档编号。
在建立倒排索引的过程中同步更新文档集频率。

如果这个单词重复出现,就更新文档集频率。

用倒排索引的第一个值存储文档集频率的好处是,不需要开辟大量的额外空间,有利于精简空间使用。
然后对倒排索引按第一个值大小进行降序排序,输出文档集频率。取前30个值记录并绘制成表格如下:
| 文档集频率 |
3022 |
2840 |
2752 |
1651 |
1537 |
1429 |
1330 |
1308 |
1254 |
1008 |
| rank |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
| 乘积 |
3022 |
5680 |
8256 |
6604 |
7685 |
8574 |
9310 |
10464 |
11286 |
10080 |
| 文档集频率 |
997 |
989 |
948 |
947 |
946 |
918 |
887 |
700 |
610 |
597 |
| rank |
11 |
12 |
13 |
14 |
15 |
16 |
17 |
18 |
19 |
20 |
| 乘积 |
10967 |
11868 |
12324 |
13258 |
14190 |
14688 |
15079 |
12600 |
11590 |
11940 |
| 文档集频率 |
572 |
520 |
507 |
489 |
437 |
427 |
421 |
420 |
390 |
372 |
| rank |
21 |
22 |
23 |
24 |
25 |
26 |
27 |
28 |
29 |
30 |
| 乘积 |
12012 |
11440 |
11661 |
11736 |
10925 |
11102 |
11367 |
11760 |
11310 |
11160 |
有Zipf’s 定律表达式为:
等价变换为: 。分别以和作为x 轴和y 轴,绘制折线图。

同样,折线图可以以R2=0.9498 的高拟合度拟合成一条直线。认为Zipf’s 定律得到验证。
(3) 开发的信息检索系统:要求支持基本的用户交互,包括输入框和返回结果的呈现(包含超链接跳转),界面简洁美观。
答:
利用Java的GUI功能设计用户界面。
原先想用C++来完成信息检索系统。因为本学期之前的代码都是基于C++编写的。然而C++在开发用户界面方面相对困难,因此改为了Java语言编写。这需要将本学期的C++代码翻译为Java语言,并且新设计一个用户界面。
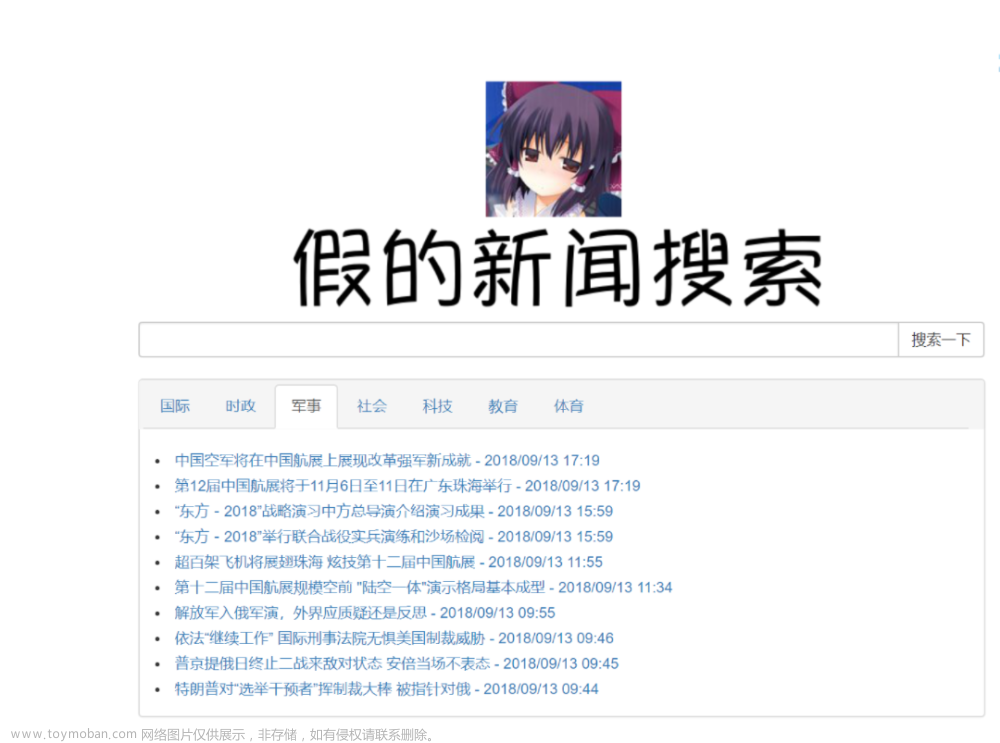
本项目的用户界面如下:

这个用户界面十分简洁,窗体内的标签提示、输入栏和搜索按钮非常明显易用。
键入query后,系统会返回搜索结果:

此时,返回结果栏和跳转超链接按钮将显示。同时显示搜索用时(单位秒,保留两位小数)。

返回结果栏用JScrollPane组件显示,带有滚动条,可以让长搜索结果完整显示。
返回的结果为符合搜索框内容的商品评论数据。同时,我还提供了五个超链接按钮,分别对应1~5的返回数据。点击按钮,可以直接跳转到对应的商品数据。
按下按钮1,跳转到一号搜索结果对应的商品数据。

显示一个商品数据后,原搜索结果不会消失。可以直接按其他按钮跳转到对应其他搜索结果的商品数据。
按下按钮1后按下按钮2,跳转到二号搜索结果对应的商品数据。

GUI组件的代码实现部分截图如下。
组件声明:

一些组件设置:

搜索返回结果将显示在JtextArea的对象ta1内。为了容纳行数很多的搜索结果,我们将ta1添加到JscrollPane的对象内,这样给返回窗口添加了滚动条。

(4) 开发的信息检索系统:要求使用倒排索引(inverted index),不能使用SQL Server、MySQL等数据库中的关系表来存储数据。
答:
使用Java建立倒排索引的过程如下:首先打开文件,然后逐行读取document。将每行字符串进行格式化,统一为小写,清除其他符号,清除多余空格和关键字。然后用split方法将整行处理过后的document切分成单词,每个单词存储为String数组的一个元素。
将单词拆分好之后对拆出来的一个个单词进行统计。如果词典中有这个单词,就在倒排文件的对应倒排列表末尾加上一个文档ID的记录。我采用vector容器来实现链表效果。如果词典中没有这个单词,则扩充词典。
具体分步算法思路由截图注释给出。
读取文件的准备工作。打开文件,倒排列表初始化。

文章来源地址https://www.toymoban.com/news/detail-814077.html
读入一行(即为一个document),并进行预处理。利用String类自带的toLowerCase()方法、replace()方法和正则表达式将每行文件处理成仅包含数字、英文单词和空格的字符串。

构建倒排索引的关键代码如下:

以上代码包含了构建倒排索引的基本操作。同时去除了英文单词附带的标点。也统计了文档频率和文档集频率,用于计算相似度和验证Zipf’s 定律。
(5) 开发的信息检索系统:要求使用TF-IDF作为权重的计算方式,在报告中包含相关的数学公式。要求使用公式编辑工具,不能截图,并对公式中的符号做出解释,对相关的代码实现给出详细的注释,并分析该部分的时间复杂度。
答:
首先说明一些必要概念:
N :所有文档数目。
:词项频率,即t在文档中的出现次数。
:文档频率,表示出现词项t的所有文档的数目。
所有文档数目为n,词项t的idf (逆文档频率)为:。其中log 的底不会对文档idf 值相对排序有影响,因此可以直接设底为10。因此,罕见词的idf 可能较高,而高频词的idf 可能较低。
对于每篇文档中的每个词项,可以将其 tf 和 idf 组合在一起形成最终的权重。tf-idf 权重机制对文档d中的词项t赋予的权重如下:
计算权重的Java代码如下:

为后续计算考虑,以上代码直接计算了文档向量。其中,计算tf-idf权重的代码已经用注释标注。
分析计算tf-idf 值的时间复杂度。
计算tf-idf 值需要读取该单词倒排文件长度和文档频率。因此需要进行两重循环,循环次数分别为词典长度和文档集的文档数量。设词项数量为n ,文档集的文档数量为t ,则计算tf-idf 值的时间复杂度为O(tn) 。
令m 为token 总数,对表达式进行化简,则时间复杂度为O(m) 。
(6) 开发的信息检索系统:要求使用余弦相似度作为<query,document>的相关性分值的计算方式,在报告中包含相关的数学公式。要求使用公式编辑工具,不能截图,并对公式中的符号做出解释,对相关的代码实现给出详细的注释(如在实现中做了某种简化或修改需要明确说明)。
答:
为了弥补文档长度给上述相似度计算所带来的负面效果,计算两篇文档 d1和 d2相似度的常规方法是求两文档对应向量的余弦相似度(cosine similarity):
详细计算方法中常数取值的不同会导致相似度具体得分的不同,但不会改变相似度的相对大小关系。
其中,分子是向量 和 的内积(inner product )或称点积(dot product ),分母是两个向量的欧几里得长度(Euclidean length ,简称欧氏长度)的乘积。两个向量的内积 定义为,文档d 对应的向量表示为 ,它是一个M 维的向量…… ,d 的欧几里得长度定义为 。
计算余弦相似度的Java代码为:

Vec容器内存储的就是文档集的文档向量。而tempVec是针对输入的query构造的临时文档向量。它只存储query中向量非零的部分。
实验4要求我们计算每个文档和其他所有文档的相似度。但是搜索系统只需要计算query和其他所有文档的相似度。因此三重循环可以直接削减为二重循环。存储余弦相似度的空间也可以减少一大半,只使用一维数组就可以了。
但是,query的文档向量并不存在。因此我们需要即时计算query的文档向量,遍历一次倒排索引。
计算临时文档向量的详细代码在下面给出。对于query的每个词条,在倒排文件中查找。如果某词条在倒排文件中没有,则直接跳过,因为文档集的全部文档关于这个词项的文档频率肯定是0,不需要计算。如果某词条在倒排文件中存在,则计算tf-idf 值,保存入query的临时文档向量。
本次实验我放弃使用简单粗暴的数组,改用Java的Map结构来存储稀疏矩阵,节省了大量内存空间。

(7) 开发的信息检索系统:要求根据相关性分值的大小对匹配到的documents进行排序,返回top 5的结果(要求同时显示每个返回的document的相关性的分值信息)。需要特别注意效率问题,要求在查询结果的上方显示查询的耗时(单位秒,保留小数点后两位)。
答:
在前一步已经计算好了query和文档集中所有文档的余弦相似度。接下来要对所有余弦相似度进行排序。
维护一个容量为5的小顶堆。它实际上并没有用堆结构存储。不过第一个元素存放的是五个元素中的最小值。
依次读入query与全部文档的余弦相似度。然后每读入一个值,就把原先五个值中的最小值放到容器第一个位置。将新读入的余弦相似度值和第一个位置保存的余弦相似度值进行比较,如果新的值更大,则替换第一个值。全部余弦相似度读完后,数组内保存的就是相似度最高的五篇文档的相似度和下标。再对数组内余弦相似度进行排序,就得到了余弦相似度前五高的文档。

输出TOP5的文档作为返回值。在原始文档集中寻找指定行的文档。读入文档并处理,按照格式输出。
读取指定行文档的代码:

处理文档代码:

本系统不在内存中保存原始文档。每次需要读取文档就重新从原始文件中读取并处理。这么做的好处是不需要花费空间存储规模很大的原始文档。坏处是每次重新读取和处理要花费一定时间。
按格式输出到JTextArea的代码如下:

读取文件meta_Gift_Card.json,记录每个商品的asin值。

搜索结果输出完毕后,记录五个搜索结果对应的asin值在全体商品信息的asin值数组中的下标,用于查找评论对应的商品信息。PosP[i]内保存着第i个搜索返回结果对应的商品信息在原始meta_Gift_Cards文件中的行数。

当超链接按钮被按下,就显示对应的商品信息。将搜索结果的asin值和预处理时保存的所有商品的asin列表进行比较,读取对应行商品信息文件。

按格式输出商品信息。注意商品信息的关键词和评论的关键字不同。

统计程序运行时间,并保留两位小数输出。计算时间使用System.currentTimeMillis() 方法。

- 特色功能。
(1) 数据规模大。例如,使用了Gift_Cards.json,而非Gift_Cards_5.json。
答:
本次实验使用的是Gift_Cards_5.json中的数据。但是本次大作业和平时的实验1~6相比,在数据结构上进行了改进。用Java的Map图结构存储文档频率、余弦相似度等中间变量,占用空间比二维数组存储大大减小。这么做保留了换用大数据集的潜力。
(2) 支持按域检索功能。应至少包含3个不同的“域”,如“title”、“reviewText”、“feature”等。
答:
本次作业设计的是一个全文搜索系统。暂时不支持域搜索。要实现域搜索可以先用正则表达式和Porter算法拆分读取到的信息,然后对不同域的数据分别建立倒排索引。
(3) 支持较为友好的用户交互,例如通过字体标红等方式帮助用户快速理解返回的结果。
答:
本次作业使用Java的GUI功能设计用户交互模块。显示清晰,操作简单,按钮功能明了,便于用户操作。
(4) 在对返回的结果进行排序时,考虑除余弦相似度之外的其他合理因素,如document的“vote”等。需要明确说明所采取的具体方式。
答:
本次作业情况特殊,实在没有办法挤出更多时间,未作此考虑。
(5) 支持query建议(方法不限于教材中的方法)。能够给出1-3个合理的候选query。
答:
在系统无法返回五个合理的搜索结果时,系统会转到query建议模块。启动query建议的情况有两种:1.系统无法针对query给出足够好的结果 2.文档集中没有出现搜索的内容
对于第一种情况系统会给出一个近似的查询query作为建议。第二种情况也一样,主要纠正拼写错误。纠正不知所云或者拼写错误的query,某种意义上也是query建议。
具体操作会在特色功能(6)中描述。
(6) 支持query纠错(方法不限于教材中的方法)。能够发现query中错误的term,并给出1-3个正确的候选query。
答:
在系统无法返回五个合理的搜索结果时,系统会转到query建议模块。启动query纠错的情况概括而言有两种:1.系统无法针对query给出足够好的结果 2.文档集中没有出现搜索的内容
用户键入一个query,调用搜索模块对评论数据进行查找。查找完毕后,如果返回的结果不足五个,则不在滚动窗口中输出搜索结果,而是用一个标签贴出query纠错。
相似度最高的返回结果以下条件满足其一,即认为搜索失败,调用query建议/query纠错功能:
- 返回文档和查询相似度过低
- 没有在文档集中查找到查询
- 非法的查询格式(比如仅有空格或标点)
启动query建议的判断代码如下图:

具体实现代码:
Query纠错的预处理代码。将query进行预处理,清除非法符号和多余空格,并且把query拆成一个个词条。这点和处理文档集时操作一致。

搜索整个词典,一个个计算词典中的全部token和query中的词条的编辑距离。Token长度过短的不作为建议给出。对于前三个词项,直接计算编辑距离并填入返回建议数组中。

对于三个以后的绝大部分token,则一边计算编辑距离,一边动态维护建议数组。每次读入一个词典中的词项,计算该词项与query中词条的编辑距离。然后把保存的三个目前为止编辑距离最近的词项中,编辑距离最大的一个词项放在数组最前面。如果新读入的词项有更优的编辑距离,就把原保存的三个具有最好编辑距离的词项中最差的那个剔除,换成新读入的词项。
实际上就是维护了一个容量为3的优先队列。鉴于容量很小,没必要额外开容器。因此用暴力方法维护就可以了。
全部词项计算完毕,advice数组内保留的就是三个编辑距离最小的词项。可以作为建议返回。

然后按照编辑距离从小到大的顺序返回query建议。将结果整理成一个字符串,然后将字符串结果导入标签,显示在窗体中。

计算编辑距离的代码如下。具体实现方式参照信息检索教材。

Query建议的运行效果:
模拟情景:用户想要搜索“well”,但是手抖多打了一个“l”,输入“welll”。此时可见,纠错系统返回了三个建议的query:well、sell和will。很容易发现,这三个建议query和输入的query差距都很小。并且,第一个建议will就是我们想要搜索的词。

如果用户输入的query和文档集中的词项相距甚远,无法找到很好的建议。那么此时纠错系统仍然会尽量返回一个或两个可能的query建议。

如果用户输入的query包含有多个错误词条,纠错系统会一个个词搜索词典,并且分别返回query建议,给出三个最可能的query建议。

(7) 其他自认为比较有特色的地方(可自行说明,每个特色功能1分,最多4分)。
答:
插入了背景音乐是本系统中有特色的地方。
利用网络下载的jar包,本程序通过实例化Player类的方式搭载了音乐播放器的功能。目前将钢琴曲《菊次郎的夏天》设为了背景音乐。轻柔舒缓的曲调适合大众用户,不会像某些风格独特的乐曲可能会导致部分用户不悦。
以下为导入的jar包:

利用了多线程的思想,窗体打开即开始播放音乐,同时实例化窗体进行数据处理和等待搜索。这样子程序可以同时执行两个功能:音乐播放器和搜索引擎。
音乐播放器类的具体实现:

主函数线程操作模块:

包内的全部文件:
 文章来源:https://www.toymoban.com/news/detail-814077.html
文章来源:https://www.toymoban.com/news/detail-814077.html
到了这里,关于基于Java实现本地数据搜索引擎(附带简易交互界面)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!