目录
1 写在前面
2 模型分析
3 遇到问题
4 探索实验一
4.1 第一部分
4.2 第二部分
Error 1
Error 2
4.3 实验结果
①参数量与计算量
②模型大小
③推理时延
5 探索实验二
5.1 LR Branch
5.2 HR Branch
5.2.1 初步分析
5.2.2 第一部分 enc2x
5.2.3 第二部分 enc4x
5.2.4 第三部分 hr4x
5.2.5 第四部分 hr2x
5.2.6 第五部分
5.3 f_branch
6 总结与思考
1 写在前面
在前面两篇文章《对MODNet 主干网络 MobileNetV2的剪枝探索》《对 MODNet 其他模块的剪枝探索》中,笔者已成功对 MobileNet V2 进行剪枝并嵌入至 MODNet,其余部分也采用键值对赋值的方式成功完成了替换,得到了 MODNet 剪枝版本一代,我们简称为“V1”。V1代在推理测试中发现:模型大小、参数量的确减小了一半,但推理时延从 240ms --> 192ms 尽管降低了20%,但下降力度还不够大,既然来到了模型压缩领域,那我们就应当尽可能“压榨”深度模型!
再一次观察 MODNet 剪枝前、后的变化情况,可以发现:FLOPs在剪枝后仅减小了原来的 1/5!
考虑到相对参数量,计算复杂度 FLOPs 对推理速度的影响更大,因此,接下来对 MODNet 中 FLOPs 占比较高的层进行剪枝。
2 模型分析
从目前情况来看,下面两部分的 FLOPs 占比较高:

3 遇到问题

分析问题:网络需要的输入通道为16,但目前只获得了8个通道;
于是,通过调试,确定了权重矩阵的位置,进行修改:32 --> 16.
但这里一直存在着一个疑问:input 是如何来的?😅
按照往常的想法,上一层的输出作为下一层的输入,但这里由于正好是两个模块的交界点,因此无法满足这样的条件。所以,接下来需要找到 input 来源。(这也正是后续剪枝的基础)
通过 debug 可知,index57 的 input 源自 enc2x,如下:

接下来,寻找 enc2x 的来源。
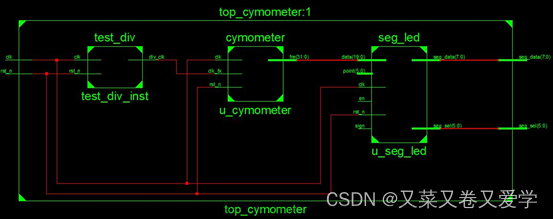
MODNet 定义处,通过 LR Branch 得到:

来到 LR Branch 定义处,发现是源自 backbone 的forward:

debug 得 enc2x shape [1,16,256,256],正是 backbone 中 feature1 的输出:


那么,在对 backbone 剪枝过后,feature1 的 output 变为 [1,8,256,256],故 enc2x 的输入也就变为了该 tensor。
也就是说,对 backbone 的某些 channel 裁剪后,hr branch 中的 channel 也就必须调整!
辩证法的一大特性就是联系!
既然如此,如何调整?
方式包括直接修改权重 channel、裁剪 output channel。但由于这里 input 在 backbone 裁剪后已经确定,因此直接修改权重的 channel,也就有了先前将 enc_channels 中的16---->8。
目前关于 input 的源头已确定,也就明确了对 backbone 的剪枝会决定 hr branch 中的输入!
因此,对 hr branch 中网络层的剪枝也就分为 input 以及weight:
(1)针对 input 部分
方法:直接裁剪 backbone 中对应的部分
存在的问题:需要顾及其内部的倍数关系,以及 channel 为8的倍数(倒置残差块)
(2)针对 weight 部分
方法:直接修改enc_channels
存在的问题:考虑output与下一层输入的匹配情况
4 探索实验一
✨开展思路:修改结构----->匹配结构----->模型剪枝----->参数嵌入------>模型推理
4.1 第一部分
关系:lr_branch input channel <------ Linear <-------- backbone.feature.18 (1280)
方法:按照剪枝的稀疏情况直接修改网络,满足网络层与层之间相互匹配的同时,降低FLOPs。然后,利用 NNI 对子模块中的相关层进行剪枝。
首先,将 backbone last layer 1280 --> 640,但遇到了一个问题:

先前也遇到过,为了满足上下网络层的关系匹配,又恢复到了1280。
由于相关层 FLOPs 较高,因此直接修改关联层 channels 为640。
MODNet 模型剪枝前、后的情况为:
参数量:3.36 M --> 1.87 M;
计算量:15315.94 M --> 14502.68 M
我们发现:params 大幅下降,但 FLOPs 变化不大!
4.2 第二部分
由于对 input 不能直接裁剪,因此对 weight output channel 进行裁剪。
在观察 hr branch 时,联想到了先前 MobileNet V2 部分的 interverted_residual:

在原先结构中是递增状态,因此这里遵循先前的规则,调换位置。
Error 1

由于先前已经明确了hr branch每一层的input,因此定位到相应部修改即可。
wrapper:24 --> 16
结果是计算量仅仅只是有了轻微的减少趋势:
参数量 :1.88 M;
计算量:14480.74 M
观察 hr branch 的 weight output channel,与预定义的 channels 有关:

方法:直接修改channels:32 --> 24
Error 2

修改:

计算量相比先前的轻微减少有了明显的改进,目前达到了 8976.64 M,减小了一半:

至此,我们将该模型作为 MODNet 剪枝版本二代,简称V2。
4.3 实验结果
整体改动情况:
- backbone中的last channel、wrapper、interverted_residual;
- MODNet hr_channels;
- HR Branch中的conv_hr4x;
①参数量与计算量
情况一:原模型
情况二:对 backbone 剪枝后的模型;
情况三:修改 backbone 最后一层 channel 以及 hr branch 中的 weight channel后的模型;
| 情况一 | 情况二 | 情况三 | |
|---|---|---|---|
| 参数量 | 6.45 M | 3.36 M | 1.76 M |
| 计算量 | 18117.07 M | 15315.94 M | 8976.64 M |
②模型大小
| 模型 | 模型大小 |
|---|---|
| 原模型 | 25641 K |
| V1 | 13256 K |
| V2 | 7213 K |
③推理时延
| 序号 | 原模型 | V1 | V2 |
|---|---|---|---|
| 1 | 0.85 | 0.67 | 0.54 |
| 2 | 0.88 | 0.67 | 0.56 |
| 3 | 0.84 | 0.65 | 0.54 |
5 探索实验二
由于 backbone 通道的剪枝会决定 HR branch,因此调整思路,先将 backbone 中的倒置残差块恢复到原先的情况。
5.1 LR Branch
backbone 部分修剪 last channel 1280 --> 640。
se_block、conv_lr16x,其余排除。
config 加入 Linear,将 se_block 以及 lrx 作为整体,与 backbone 剪枝。
变化如下:


读取 pth,并修改结构,验证是否可以成功加载:

加载失败,原因是涉及到了 Conv 中的 BN 层,如下:

解决方案:修改 IBNorm 定义即可。
于是,成功加载,且完成 lr_branch 的模拟推理,如下:

接下来,将 lr_branch 的参数嵌入到 MODNet,但在打印键时发现缺少了 running mean,尽管与inference 无关,但与 retrain 有关。换句话说,虽然可以成功嵌入,但对后续重训练精度的恢复有影响!

再次打印 lr_branch 参数,发现该键是存在的,但由于 model.named_parameters() 并没有获取到,因此这里采用 model.state_dict() 的方式重新嵌入。打印方式如下:
for name, params in model.state_dict().items():
print(name)
总共有751个键值对,注意 backbone 和 lr 中的 backbone,参数一致:

5.2 HR Branch
5.2.1 初步分析
将 HR Branch 划分为 5 个部分:

分析:3、4、5 部分 channel 有着明显的上、下层衔接关系;
而1、2部分从channel上看不出联系;
因此,接下来将对该 model 的5个部分分别处理,进而合并成 new branch。
5.2.2 第一部分 enc2x
利用 sequential 连接,剪枝:

无法绝对匹配,剪枝失败,源代码定义如下:

所以无法合并,考虑分层剪枝,但又存在两个问题:
- 无法对权重的input channel修改(16、35)
- 下一层的input channel(35)无法匹配
解决方案:手动剪枝
明确目标:

✨开展思路:
获取第57层,先使用 0.25 稀疏度剪枝,然后执行剪枝脚本将 input channel16 --> 8,参数保存,注意参数名 MODNet 内一致
获取58层同上,操作同上;
利用 sequential 连接 tohr 与 conv;
按照结构内的参数名,将 tohr 与 conv 参数连接,形成一个 ordereddict 格式;
将参数嵌入结构,形成第一个part;

剪枝后的参数名虽然和结构中相差了 hr,且一一对应,但填入结构仍然出现了参数初始化的情况。如下:


strict=false:

因此,这里采用键值替换进行修改。(结构不变,修改参数中的键名)

但这样的键名不利于下面的合并。
于是,笔者重新构建字典,修改键名,代码如下:
tohr_enc2x_ckpt = OrderedDict(
[(k.replace(k, 'hr_branch.tohr_enc2x.' + k), v) for k, v in tohr_enc2x.state_dict().items()])后来想想,这一参数(填入结构并修改参数名)和剪枝过后的是一致的,验证代码与结果如下:
for key in pruned_tohr_enc2x.keys():
if tohr_enc2x_ckpt[key].equal(pruned_tohr_enc2x[key]):
print("Match")
因此,这一操作意义不大。因为初心是为了与参数嵌入时命名一致,但实际上因为这一操作导致的中间过程较为繁琐。此外,剪枝过后的 pruned_tohr_enc2x 已经达到了目标状态,即shape:[24,8,1,1]
所以,第一部分两个 layer 没有连接的必要!
5.2.3 第二部分 enc4x
调整思路:NNI 剪枝 + 自定义通道剪枝 + 键名替换 + 参数嵌入
剪枝前:

剪枝后:

因此,这一部分成功嵌入!
5.2.4 第三部分 hr4x


首先,channel 83 并不合理,与模型定义时产生了冲突,因此先前仅仅是为了满足模型结构做的微调。通过剪枝,除了layer 1 的weight channel,其他都可以实现。
如何将 weight 从(24,16,1,1)的尺寸裁剪为(24,8,1,1)?🥲🥲🥲
✨开展思路:
获取该层的参数,打印shape测试;
计算每一个输入通道的权重和,并排序;
将较小的8个通道去除;
创建去除后的tensor,进行参数替换;
于是,LeNet 它又来了!笔者很喜欢在 LeNet 上做一些测试。🌝
核心思想:编号 --> 排序 --> 去除通道 --> 重新编号 --> 参数替换
注意事项:①bias由 output channel 决定;②网络层类型为 OrderedDict()
测试:将输入 weight 由[6,3,3,3] -----> [4,3,3,3]
局限性:缺少稀疏度分析 + 单一层剪枝
针对 hr_branch 的第一个 layer channel(16---->8)成功剪枝!
针对第三部分 channel 99 ------->83,成功剪枝:

然后修改键名,与 MODNet 匹配,嵌入成功。
5.2.5 第四部分 hr2x
剪枝前:

剪枝后:

因此,这一部分成功嵌入!
5.2.6 第五部分
剪枝前:

剪枝后:

同样,这一部分成功嵌入!
5.3 f_branch
剪枝前:

剪枝后:

同时,也完成了模型嵌入,但遇到了下列问题:
💥问题一:保存的 hr branch 参数 bias 都为0、1,影响到了再训练的精度;

💥问题二:剪枝脚本仅仅针对 Conv 的 weight 以及 bias,尚未对包含于 Conv 块中的 BN 层进行处理,有待改进。

修改:针对input channel,BN层不被影响,因此直接添加如 dict 即可。
💥问题三:剪枝脚本执行后返回的网络层的名字没有和原先的匹配,这里有待处理。
修改:按照MODNet中的layer name修改,利用键值进行替换
OrderedDict([(k.replace(k, 'hr_branch.tohr_enc2x.' + k), v) for k, v in model.state_dict().items()])6 总结与思考
通过再一次分析 MODNet 网络结构,笔者发现 V1 代的剪枝版本在计算量上处理得不够好,于是,本文从计算量的角度分析,对 MODNet 网络结构中计算量占比较大的部分重新进行剪枝处理,并进行参数替换。实验结果表明,剪枝后的模型相比原模型降低了一半的计算量,推理时延也有了明显的改进,然而,模型精度并不好!
因此,关于模型剪枝后retrain精度较低的问题,笔者做了下列思考🤔🤔🤔:
(1)从剪枝本身考虑
相同情况下,大 sparse 导致更多的特征提取层无法提取到必要的特征,破坏了核心结构;
固定整体剪枝比例存在漏洞,导致有些模块去除了重要程度较高的通道;
缺少 BN 层中的 running mean 、var ,影响了再训练时的精度恢复;
解决方案:
①采用 少量剪枝---->微调---->少量剪枝------微调 的策略;
②不再采用固定整体比例剪枝,而是对特定的模块具体问题具体分析;文章来源:https://www.toymoban.com/news/detail-814261.html
(2)从再训练考虑文章来源地址https://www.toymoban.com/news/detail-814261.html
- 由于参数的初始化以及算法的随机性,导致单一的训练无法得到较理想的效果?
- 如何准确设置超参?训练得到原模型的超参组合与剪枝后重训练的超参一样吗?
- 关于 learning rate,剪枝后,模型减小,参数减少,寻找最优解时的步长应当减小。反之,可能错过最优解。
- 是否可以设置动态参数?随着 epoch 的增加而变化?
到了这里,关于MODNet 剪枝再思考: 优化计算量的实验历程分享的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!