提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
摘要
本周主要阅读了2023CVPR的文章,用于流式传输自由视点视频的神经残余辐射场,在文章中讲解了一种基于神经残余辐射场实现流式传输自由视点视频的方法,其主要思路就是建模时空特征空间中相邻时间戳之间的残差信息,将动作信息以及残差信息作为数据供给编码以及解码,在体积小的情况下实现质量和速度上均优秀的结果。除此之外,我还学习了解了傅里叶变换与卷积网络之间的相互理解,了解其是如何对卷积网络是如何与傅里叶变换产生联系的。
Abstract
This week, I mainly read the article from CVPR 2023, which is about the neural residual radiation field for streaming free viewpoint videos. The article introduces a method based on the neural residual radiation field to achieve streaming free viewpoint videos. The main idea is to model the residual information between adjacent time stamps in the spatio-temporal feature space, and use the action information and residual information as data for encoding and decoding, achieving excellent results in both quality and speed with a small volume. In addition, I also learned about the mutual understanding between Fourier transform and convolutional network, and how convolutional network is related to Fourier transform.
文献阅读:用于流式传输自由视点视频的神经残余辐射场
Title: Neural Residual Radiance Fields for Streamably Free-Viewpoint Videos
Author:Liao Wang , Qiang Hu ,Qihan He , Ziyu Wang , Jingyi Yu
From:2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
1、研究背景
⽤于静态对象建模和⾃由视图渲染的神经辐射场 (NeRF) 的成功激发了对动态场景的⼤量尝试。动态场景(尤其是⼈类表演)的逼真⾃由视点视频 (FVV) 可以缩⼩表演者和观众之间的差距。但制作和观看 FVV 就像在流媒体平台上点击和观看常规 2D 视频⼀样简单的⽬标仍然是深远的。目前利用神经辐射场技术进行动态场景的自由视角渲染还存在很多挑战,包括:1)受限于离线渲染,2)能够处理的序列比较短,3)序列中的场景变化,人物动作较小。
2、方法提出
在本⽂中,提出了⼀种新技术,即残余辐射场(ReRF),作为⼀种⾼度紧凑的神经表示,可在长时间动态场景上实现实时 FVV 渲染。ReRF显式地建模时空特征空间中相邻时间戳之间的残差信息,并使⽤基于全局坐标的微小MLP作为特征解码器。具体来说,ReRF 采⽤紧凑的运动网格和残差特征网格来利⽤帧间特征相似性。我们证明这种策略可以在不牺牲质量的情况下处理⼤型运动。我们进⼀步提出了⼀种顺序训练⽅案来保持运动/残差⽹格的平滑性和稀疏性。基于ReRF,我们设计⼀种特殊的 FVV 编解码器,可实现三个数量级的压缩率,并提供配套的 ReRF 播放器以⽀持动态场景的⻓时间 FVV 的在线流式传输。⼤量实验证明了 ReRF 在紧凑地表⽰动态辐射场⽅⾯的有效性,从而在速度和质量⽅⾯实现前所未有的⾃由视点观看体验。
3、实现过程
3.1、总体实现
如下图所示,将第一帧训练好一个初始半显示场景 f1,再用f1和 第二帧的图像训练紧凑的运动网格M2 和一个剩余特征网格 r2 ,从而得到当前场景体素表示 f2 , 也就是使用公式 ft( p ) = ft-1( p ) (p + Mt §)。这样生成的Mp 和 rp 有助于视频的编码与解码。
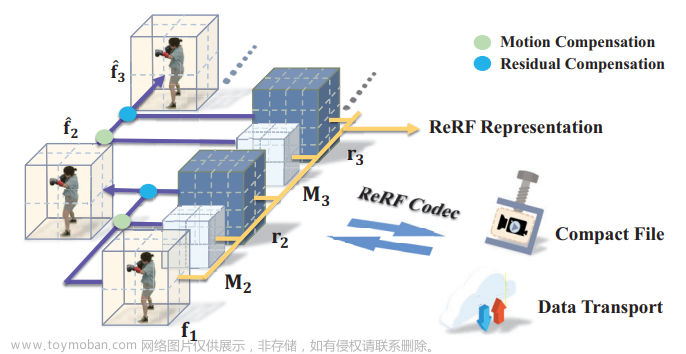
3.2、细节实现
为当前帧 t 引入一个紧凑运动网格Mt 和一个剩余特征网格 rt。低分辨率运动网格 Mt 表示体素偏移,以表示当前帧中的体素在上一帧中对应的体素索引。剩余网格 rt 表示对当前帧中相邻扭曲误差和新观测区域的稀疏补偿,对于第一帧,采用完整的显式特征网格表示 f1和全局 MLP Φ。ReRF用公式表示为 Φ,f1和{Mt , rt} t=1 将Mt应用于 ft-1 来提取帧间冗余,并获得当前帧的基本特征网格 ft,即 ft( p ) = ft-1( (p + M t ( p ) ) ,随后添加残差补偿来恢复整个特征网格 ft = ft ’ + rt。
3.3、信号实现
提出的基于 ReRF 的编解码器和播放器概述(编码器和解码器的建模元素分别以浅绿⾊和粉⾊阴影表示)。编码器使⽤ PCA、3D-DCT、量化和熵编码来压缩输⼊信号以⽣成⽐特流。解码器接收压缩⽐特流,解码每个语法元素,并反转编码过程。此外,给定解码的运动场Mt。
4、相关方法
4.1、Motion-aware Residual Fields
从长时间RGB视频输入中获得包括Φ,f1和{Mt , rt} t=1的ReRF表示,这加强了剩余网格和运动网格的紧凑性和DeVRF一样,获得第一帧的完整显式特征网格f1,并使用全局MLP Φ 作为特征解码器,给定前一帧的特征网格ft-1和当前帧的输入图像,生成运动网格Mt 和残差网格 rt,遵循DEVRF到一个密集运动场Dt,引入了一个运动池化策略,体素Pt中的运动向量可以指向前一帧中的不同体素Pt-1,这类似于标准的平均池化操作。首先将 Dt分割为立方体,其中每个立方体包含连续的8 × 8 × 8体素,对于每个立方体,在8 × 8 × 8的核上对 Dt应用平均池化,以确保每个立方体共享相同的运动向量,对其进行采样以生成低分辨率的运动网格Mt,大小比原始的密集网格小512倍,可以通过运动场跟踪前一帧的一些特征立方体,从而进一步降低剩余体素的熵,生成一个低分辨率Mt,紧凑地表示跨帧的平滑运动。
4.2、Residual Grid Optimization
将之前的特征网格ft-1 扭曲为当前的基网格 ft 粗略地补偿了帧间运动引起的特征差异,优化残差网格的过程中,固定 ft 和 Φ,并将梯度反向传播到残差网格 rt,以仅更新 rt ,使用L1损失来正则化 rt ,以增强其稀疏性以提高紧凑性,强制 rt 仅补偿帧间残差或新观测区域的稀疏信息。其中 λ= 0.01 ,这样得到Mt 和 rt 的设计和生成机制使他们更好地压缩。

5、测试实验
使用捕获的动态数据集包含⼤约 74 个分辨率为 1920 x 1080 以及帧率为 ×25 fps 的视频对几个模型进行对比测试,结果如下图所示,相比于其他方法模型,本方法在大小很小,其他性能指标都达到一个良好水平,说明我们的方法相比其他方法能将容量压缩到很小的情况下,维持了很高的渲染质量。

傅里叶变换与卷积神经网络
1、卷积神经网络大致工作流程
卷积神经网络大致主要分为三个层次,输入层、隐藏层以及输出层。其中输入层使用来接收外部数据的,各个数据类型表示的维度可能是不相同的,可以理解为初步提取的特征。紧接着将数据输送到隐藏层种,对这些不同的数据进行重新的线性组合,提取更多神经网络能够信息,这些信息可能是更为抽象的信息,这些信息可以理解为输入层数据间的相互关系。最后通过输出层将这些信息进行分类输出最后的结果。
2、特征的数值表示
在通过输出的全连接层之前,整个数据图像会被处理成带有特征值的“数据图”,这个过程是如何实现的呢?由1可以知道,经过隐藏层处理的数据可以理解成为不同数据之间的线性组合处理,也就是彼此之间的相互关系,为了将这些相互关系的数据保存在一个小点中,便使用特征权值法进行处理。如下图所示,经过卷积核处理后得到的几种不同模式特征。然后对其进行相应的“打分”,将最终的数值进行权值乘积处理,保存到相应点中。整个过程就如同RGB模式的工作过程。
3、傅里叶变换的理解
经过2的理解可以知道,其特征值的计算就是经过模式以及权重的乘积和计算得出的,于是联想到傅里叶变换中的情况,假如将不同频率想象成一个个不同的模式,然后在频域中的取值可以理解为在该模式下的权重分值,然后将对所有频率进行相应的积分处理,这个过程便和特征的计算过程类似,这样就将傅里叶变换与卷积过程联系起来。但是事实上,傅里叶变换是对整体进行处理的,而不是像图像中的点进行局部处理,这样就有了差异之处,就比如对时域的图像加多相同的部分,频域的曲线就会产生相应的变换,这就是傅里叶变换的全局考虑带来的结果。
4、限定范围的变换
为了让傅里叶变换过程不考虑整个全局,从而适应卷积过程,对傅里叶变换函数作出下列变换,最终得到的带有
α
\alpha
α、s的限制范围的傅里叶变换式子,其中s代表着图像中心点的位置,
α
\alpha
α代表着卷积核的大小。 文章来源:https://www.toymoban.com/news/detail-814335.html
文章来源:https://www.toymoban.com/news/detail-814335.html
总结
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。文章来源地址https://www.toymoban.com/news/detail-814335.html
到了这里,关于用于流式传输自由视点视频的神经残余辐射场的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!