训练AI:从数据收集到模型部署的完整指南
随着人工智能的迅速发展,越来越多的企业、学术机构和开发者开始尝试训练自己的AI模型并将其应用于实际应用。但是,训练AI是一项复杂的工作,需要一定的编程和机器学习知识。在这篇文章中,我们将详细探讨从数据收集到模型部署的完整步骤,并提供一些有用的技巧和工具,以帮助你成功地训练自己的AI模型。
第一步:收集数据

当你决定训练一个AI模型时,你首先需要收集大量与你要训练的AI相关的数据集。数据是训练AI模型的基础,因此它的质量对最终的模型性能起着至关重要的作用。在收集数据时,你需要从可靠的数据源(如数据仓库、数据集市、API接口)获取数据,确保数据的准确性和完整性。
在收集数据时,你需要考虑以下因素:
- 数据类型:你需要选择与你正在训练的AI模型类型相适应的数据类型。例如,如果你正在训练一个图像分类器,则需要收集大量图像数据。
- 数据质量:确保数据准确性和一致性,尤其是在你准备将其用于训练时。数据集应该经过数据清洗,并且只包含与你的AI应用程序相关的数据。
- 数据量:你需要收集足够的数据,以便训练AI模型具有足够的准确度。
- 数据来源:确保数据来源可靠,不包含任何敏感信息或违反版权。
现成的数据集有很多,如Kaggle的数据竞赛、UCI机器学习仓库等等。如果你想在特定领域训练模型,例如医疗保健或金融服务,可以考虑使用专门的数据提供商。
第二步:数据清洗

在收集数据之后,你需要对数据进行清洗,以去除无关数据并确保数据的准确性和一致性。数据清洗过程包括以下步骤:
- 去重:扫描数据集,删除任何重复的记录。
- 缺失值处理:处理数据集中任何缺失值或null值。你可以选择填充它们、删除包含缺失值的行或使用插值来估计缺失值。
- 过滤异常值:过滤掉任何与正常数据偏差较大的异常值。
- 标准化数据:标准化数据集可能需要转换,例如将数值型数据进行规范化或归一化。
- 纠正错误:在清理数据时,你可能会发现一些错误或不一致的值。这些问题需要进行纠正以确保数据的正确性和一致性。
数据清洗可能需要大量的工作,但它是训练AI模型之前不可避免的步骤。你可以使用Python编程和一些开源的数据清洗工具(例如OpenRefine),以减轻这个任务的负担。
第三步:数据划分

在你已经收集并清洗了数据之后,接下来是将其划分为训练、验证和测试集。训练数据集用于训练AI模型,而验证数据集用于优化和验证模型。测试数据集用于测试模型的性能。
常用的划分比例是70%的数据集用于训练模型、15%的数据集用于验证模型,5%的数据集用于超参数调整,最后10%的数据集用于测试模型的性能。注意,不同的AI应用程序和数据类型可能需要不同的数据划分比例,因此需要根据具体情况调整。
将数据集划分为训练、验证和测试集可以使用Python编程实现,代码如下:
```文章来源:https://www.toymoban.com/news/detail-814586.html
import numpy as np
from sklearn.model_selection import train_test_split
# 加载数据集
data = np.load('data.npy')
labels = np.load('labels.npy')
# 将数据集划分为训练、验证和测试集
train_data, test_data, train_labels, test_labels = train_test_split(data, labels, test_size=0.1, random_state=42)
train_data, val_data, train_labels, val_labels = train_test_split(train_data, train_labels, test_size=0.1, random_state=42)
print('训练集大小:', len(train_data))
print('验证集大小:', len(val_data))
print('测试集大小:', len(test_data))
```
第四步:模型选择

选择适合你的AI应用程序的机器学习算法。你需要根据你的数据类型、数据量和你希望AI模型获得的预测准确性,选取不同的算法。常用的机器学习算法包括:
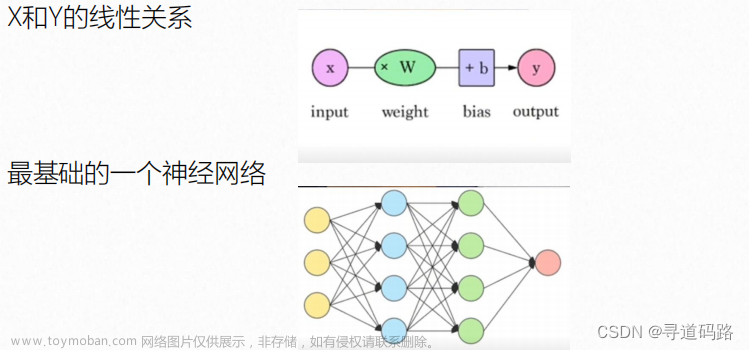
- 神经网络:一种类似于脑神经元工作方式的模型,适用于图像、语言处理、自然语言处理等领域。
- 支持向量机(SVM):一种监督学习算法,适用于分类和回归问题。
- 决策树:一种基于树形结构的分类模型,适用于分类和回归问题。
- 随机森林:一种集成学习算法,通过同时训练多个决策树来提高模型准确性。
在选择机器学习算法时,要考虑到许多因素,例如数据预处理、特征选择、模型优化等等。这需要不断尝试和调整,以获得最佳结果。
第五步:模型训练

在选择模型之后,你需要使用训练集对模型进行训练,并使用验证集对模型进行优化。你可以使用各种深度学习框架(例如TensorFlow、Keras、PyTorch和Caffe)来训练模型。以下是训练模型的一些指导原则:
- 使用GPU加速来加快训练速度。
- 监控训练损失和验证损失,以确定模型的收敛状态。
- 使用交叉验证和网格搜索等技术来调整模型参数,以提高模型的性能。
- 使用正则化方法来防止过拟合,例如dropout、L1和L2正则化等。
以下是使用Python和TensorFlow训练神经网络模型的示例代码:
```
import tensorflow as tf
from tensorflow.keras import layers
# 定义模型
model = tf.keras.Sequential([
layers.Dense(256, activation='relu', input_shape=[len(train_data[0])]),
layers.Dropout(0.5),
layers.Dense(128, activation='relu'),
layers.Dropout(0.5),
layers.Dense(10)
])
# 编译模型
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
# 训练模型
history = model.fit(train_data, train_labels, epochs=50, validation_data=(val_data, val_labels))
# 评估模型
test_loss, test_acc = model.evaluate(test_data, test_labels)
print('Test accuracy:', test_acc)
```
第六步:模型评估

使用测试集对模型进行评估,并测量其准确性和性能。你可以使用各种评估指标来评估模型,例如准确度、精确度、召回率、F1分数等等。
以下是使用Python和Keras评估神经网络模型的示例代码:
```
# 使用测试集评估模型
test_loss, test_acc = model.evaluate(test_data, test_labels)
print('Test accuracy:', test_acc)
```
除了在测试集上评估模型的性能外,还可以使用混淆矩阵和ROC曲线等技术进一步评估模型的性能。
第七步:模型部署
在完成模型训练和评估后,你可以将模型部署到你的应用程序、设备或云服务器上。该过程的方法取决于你的应用程序类型,可能需要一些技术(例如将Python代码转换为API、使用Docker容器等等)。以下是使用Flask将训练好的神经网络模型封装为REST API的示例代码:
```
from flask import Flask, request
import tensorflow as tf
# 加载模型
model = tf.keras.models.load_model('model.h5')
# 定义Flask应用程序
app = Flask(__name__)
# 定义API端点
@app.route('/predict', methods=['POST'])
def predict():
data = request.json['data']
prediction = model.predict(data)
return {'prediction': prediction.tolist()}
# 运行应用程序
403 Forbidden(host='0.0.0.0', port=8080)
```
训练AI模型是一个复杂且耗时的过程,需要一定的编程和机器学习知识。希望通过这篇文章,你可以了解到从数据收集到模型部署的完整训练AI过程。如果你刚开始接触AI,建议先学习一些基础的编程和机器学习知识,还可以使用现成的AI平台和工具来帮助你训练AI模型。无论哪种方法,都需要具备一定基础的编程和机器学习知识。文章来源地址https://www.toymoban.com/news/detail-814586.html
到了这里,关于训练AI:从数据收集到模型部署的完整指南的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!