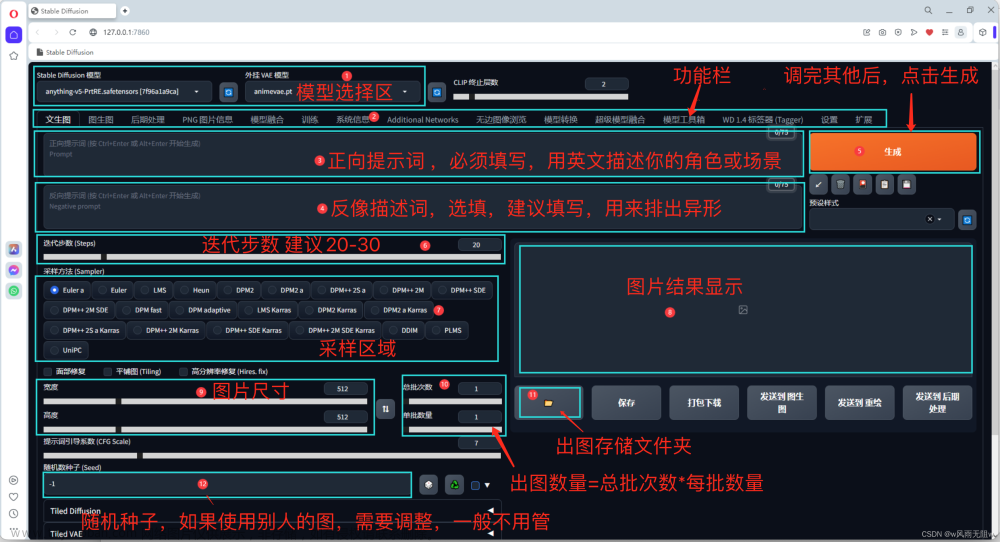
Stable Diffusion是计算机视觉领域的一个生成式大模型,可以用于文生图,图生图,图像inpainting,ControlNet控制生成,图像超分等丰富的任务。
一、Stable Diffusion核心基础原理
(一)Stable Diffusion模型工作流程
-
文生图(txt2img)
文生图任务是指将一段文本输入到SD模型中,经过一定的迭代次数,SD模型输出一张符合输入文本描述的图片。
- 步骤一: 使用CLIP Text Encoder模型将输入的人类文本信息进行编码,输出特征矩阵;
- 步骤二: 输入文本信息,再用random函数生成一个高斯噪声矩阵 作为Latent Feature的“替代” 输入到SD模型的 “图像优化模块” 中;
- 步骤三: 将图像优化模块进行优化迭代后的Latent Feature输入到 图像解码器 (VAE Decoder) 中,将Latent Feature重建成像素级图。

-
图生图(img2img)
图生图任务在输入本文的基础上,再输入一张图片,SD模型将根据文本的提示,将输入图片进行重绘以更加符合文本的描述。
- 步骤一: 在输入文本信息进行编码的同时,将原图片通过图像编码器(VAE Encoder) 生成Latent Feature(隐空间特征)作为输入;
- 步骤二: 将上述信息输入到SD模型的 “图像优化模块” 中;
- 步骤三: 将图像优化模块进行优化迭代后的Latent Feature输入到 图像解码器 (VAE Decoder) 中,将Latent Feature重建成像素级图。
 总结:不管是文生图还是图生图,核心模型都是图像优化模块,图像优化模块的输入都是文字+图片,输出都是一张经过优化后的图片。只不过文生图任务中图像优化模块的输入是一张随机生成的噪声图。模型对文字的编码采用CLIP Text Encoder模型,对于图片的编码采用VAE Encoder。
总结:不管是文生图还是图生图,核心模型都是图像优化模块,图像优化模块的输入都是文字+图片,输出都是一张经过优化后的图片。只不过文生图任务中图像优化模块的输入是一张随机生成的噪声图。模型对文字的编码采用CLIP Text Encoder模型,对于图片的编码采用VAE Encoder。
图像优化模块 是由一个U-Net网络和一个Schedule算法共同组成
- U-Net网络负责预测噪声,不断优化生成过程,在预测噪声的同时不断注入文本语义信息;
- schedule算法对每次U-Net预测的噪声进行优化处理(动态调整预测的噪声,控制U-Net预测噪声的强度),从而统筹生成过程的进度;
- 在SD中,U-Net的迭代优化步数大概是50或者100次,在这个过程中Latent Feature的质量不断的变好(纯噪声减少,图像语义信息增加,文本语义信息增加)

(二)Stable Diffusion模型核心基础原理
- SD模型属于扩散模型
- 扩散模型的整体逻辑的特点是过程分步化与可迭代;
- SD模型具备较强的泛化性能,这些都归功于扩散模型中核心的前向扩散过程和反向生成过程;
Stable Diffusion模型的整个流程遵循参数化的马尔可夫链,前向扩散过程是对图像增加噪声,反向生成过程是去噪过程。

- SD模型是基于Latent的扩散模型
- 常规的扩散模型在实际像素空间进行前向扩散过程和反向生成过程;
- 基于Latent的扩散模型在低维的Latent隐空间进行前向扩散过程和反向生成过程,可以大大降低显存占用和计算复杂性。
(三)Stable Diffusion的训练过程
假设我们已经有了一张图像,生成产生一些噪声加入到图像中,然后就可以将该图像视作一个训练样例。使用相同的操作可以生成大量训练样本来训练图像生成模型中的核心组件。基于上述数据集,我们就可以训练出一个性能极佳的噪声预测器,经过训练的噪声预测器可以对一幅添加噪声的图像进行去噪,也可以预测添加的噪声量。
Stable Diffusion的整个训练过程实际上就是扩散模型的前向扩散过程和反向生成过程。前向过程,即使用使用自编码器中的编码器来训练噪声预测器。一旦训练完成后,就可以通过运行反向过程(自编码器中的解码器)来生成图像。
语义信息对图片生成的控制:注意力机制
在SD模型的训练中,每个训练样本都会对应一个标签,我们将对应标签通过CLIP Text Encoder输出Text Embeddings,并将Text Embeddings以Cross Attention的形式与U-Net结构耦合,使得每次输入的图片信息与文字信息进行融合训练,如下图所示:
(四)其他主流生成式模型
传统深度学习时代火爆的生成式模型有GAN,VAE,Flow-based model等模型。
二、Stable Diffusion核心网络结构
(一)SD模型整体架构
SD模型的工作原理分为以下几个关键步骤:
- 提示词(Prompt)输入,文本信息转换成语义向量传输给文本编码器(Text Encode);
- 潜在空间压缩: 使用变分自编码器(VAE)将高维度的图像数据压缩到一个低维度的潜在空间;
- 正向扩散: 在潜在空间中,模型通过逐步添加噪声来“扩散”图像,最终将图像转化为完全随机的噪声分布。这个过程模拟了物理中的扩散现象,使得图像的特征逐渐消失;
- 噪声预测器: 在训练阶段,模型学习如何预测在潜在空间中添加的噪声。这是一个U-Net结构的神经网络,它通过学习如何从噪声图像中恢复出原始图像来训练;
- 反向扩散: 在生成阶段,模型使用噪声预测器来估计潜在空间中图像的噪声,并逐步去除这些噪声,从而从噪声中恢复出清晰的图像;
- 条件生成: Stable Diffusion通过提示词来引导图像的生成。提示词首先被分词并转换为嵌入向量,然后这些向量被输入到噪声预测器中,以指导生成过程,确保生成的图像与提示词相匹配;
- VAE解码: 最后,潜在空间中的图像通过VAE的解码器转换回原始的像素空间,生成最终的图像。
如下图所示,扩散过程发生在图像信息生成器中,将初始纯噪声潜变量输入到Unet网络中并与语义控制向量结合,该过程重复30-50次以不断从纯噪声潜变量中去除噪声变量并不断地将语义信息注入到潜在向量中,可以获得具有丰富语义信息的潜在空间向量(图右下深粉色方块)。采样器负责协调整个去噪过程,并根据设计模式在去噪的不同阶段动态调整Unet去噪强度。为了更好地理解这一点,图内显示了通过将初始纯噪声向量和最终去噪潜在向量输入到图像解码器中输出图像的差异。从图中可以看出,纯噪声向量的解码图像由于缺乏任何有用信息也是纯噪声,而去噪潜向量经过50次迭代后的解码图像是有效的并且包含语义信息。
Stable Diffusion模型整体上是一个End-to-End模型,主要由VAE(变分自编码器,Variational Auto-Encoder),U-Net以及CLIP Text Encoder三个核心组件构成。 这是原论文采样图,没画训练过程。最左边是像素空间的编码器解码器,最右边是clip把文本变成文本向量,中间上面的就是加噪,下面就是Unet预测噪声,然后不停的采样解码得到输出图像。
这是原论文采样图,没画训练过程。最左边是像素空间的编码器解码器,最右边是clip把文本变成文本向量,中间上面的就是加噪,下面就是Unet预测噪声,然后不停的采样解码得到输出图像。
(二)VAE模型
在Stable Diffusion中,VAE(变分自编码器,Variational Auto-Encoder)是基于Encoder-Decoder架构的生成模型。VAE的Encoder(编码器)结构能将输入图像转换为低维Latent特征,并作为U-Net的输入。VAE的Decoder(解码器)结构能将低维Latent特征重建还原成像素级图像。
-
Stable Diffusion中VAE的核心作用:图像压缩和图像重建

-
Stable Diffusion中VAE的高阶作用:细节微调
VAE模型除了能进行图像压缩和图像重建的工作外,如果我们在SD系列模型中切换不同微调训练版本的VAE模型,能够发现生成图片的细节与整体颜色也会随之改变(更改生成图像的颜色表现,类似于色彩滤镜)。 -
Stable Diffusion中VAE模型的完整结构

-
Stable Diffusion中VAE的训练过程与损失函数
- L1回归损失:衡量预测值与真实值之间的差异;
- 感知损失:比较原始图像和生成图像在传统深度学习模型(VGG、ResNet、ViT等)不同层中的特征图之间的相似度,而不直接进行像素级别的对比;
- PatchGAN的判别器损失:使用PatchGAN的判别器来对VAE模型进行对抗训练,通过优化判别器损失,来提升生成图像的局部真实性(纹理和细节)与清晰度;
- KL正则化进行优化训练:通过引入正则化损失项,来调整Latent特征使其零中心化并保持小的方差,进而防止Latent空间的任意缩放。
(三)U-Net模型
Stable Diffusion U-Net的完整结构图:(图中包含Stable Diffusion U-Net的十四个基本模块) 文章来源:https://www.toymoban.com/news/detail-814607.html
文章来源:https://www.toymoban.com/news/detail-814607.html
(四)CLIP Text Encoder模型
- CLIP模型是一个基于对比学习的多模态模型,主要包含Text Encoder和Image Encoder两个模型。
- CLIP模型的任务主要是通过Text Encoder和Image Encoder分别将标签文本和图片提取embedding向量,然后用余弦相似度(cosine similarity)来比较两个embedding向量的相似性,以判断随机抽取的标签文本和图片是否匹配,并进行梯度反向传播,不断进行优化训练。


参考:
深入浅出完整解析Stable Diffusion(SD)核心基础知识文章来源地址https://www.toymoban.com/news/detail-814607.html
到了这里,关于Stable Diffusion(SD)核心基础知识——(文生图、图生图)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!