MySQL的InnoDB存储引擎以其卓越的事务处理和数据完整性保护能力而受到广泛赞誉。在这些特性中,Doublewrite Buffer作为一个关键组件,确保了数据的完整性和可靠性。在这篇文章中,我们将深入探讨Doublewrite Buffer的原理、作用及其在MySQL中的重要地位。
1️⃣什么是Double write Buffer
Doublewrite Buffer是MySQL数据库中InnoDB存储引擎的一种机制,用于解决部分写失效的问题,提高数据完整性和可靠性。Doublewrite Buffer是内存+磁盘的结构,包括内存结构和磁盘结构两个部分。
-
在内存结构中,Doublewrite Buffer由128个页(Page)构成,大小是2MB。这些页在内存中以Doublewrite Buffer的形式存在。
-
在磁盘结构中,Doublewrite Buffer在系统表空间上是128个页(2个区,extend1和extend2),大小也是2MB。这些页在磁盘上以Doublewrite File的形式存在。
Doublewrite Buffer的原理是在将数据页写到数据文件之前,先将它们写入Doublewrite Buffer的共享表空间内。在完成写入Doublewrite Buffer后,再将数据页写入到数据文件的适当位置。这种方式可以确保数据的一致性和完整性,因为在写入过程中发生意外崩溃时,可以从Doublewrite Buffer中找到完好的数据页副本用于恢复。
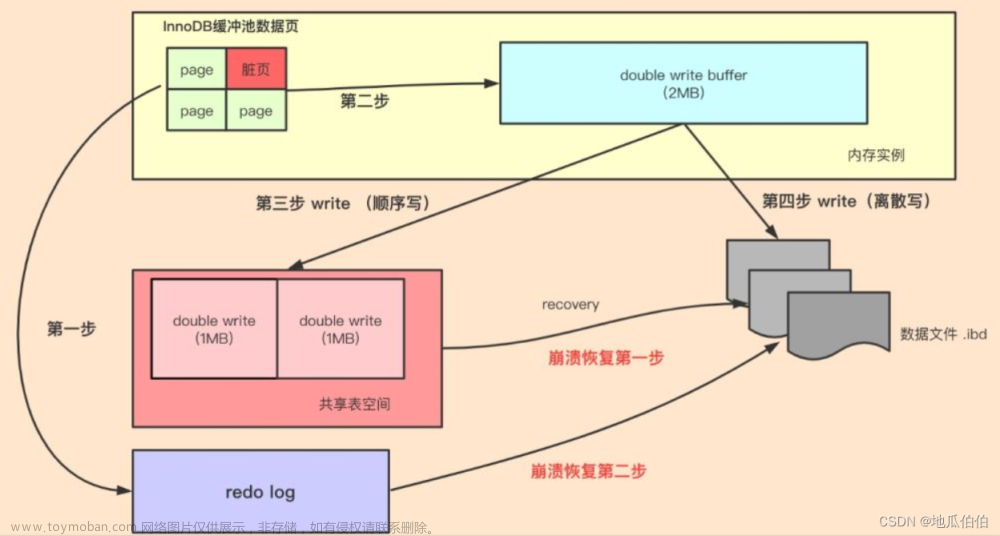
当有数据页要被写入数据文件时,首先将页数据通过memcpy函数拷贝至内存中的Doublewrite Buffer中。然后,Doublewrite Buffer的内存中的数据页会刷写到Doublewrite Buffer的磁盘上,分两次写入磁盘共享表空间中(连续存储,顺序写,性能很高),每次写1MB。完成Doublewrite页的写入之后,再将内存中的Doublewrite Buffer中的页写入到自己的表空间文件中。
通过这种方式,至少在两次写操作中,数据文件和Doublewrite Buffer文件中至少有一份数据是正确无误的。如果写磁盘过程发生了崩溃,那么MySQL重启时可以通过校验和来确认是否有错误数据,如果Doublewrite Buffer文件错误了,就从数据文件中拉取原始数据根据redo log得出正确的目标数据,而如果数据文件错误了,则将Doublewrite Buffer中的数据重新写入数据文件。
2️⃣Doublewrite Buffer工作流程
- 写操作触发: 当执行INSERT、UPDATE或DELETE等写操作时,MySQL首先将数据写入双写缓冲区。
- 同步到Doublewrite File: 随后,双写缓冲区中的数据被同步(flush)到Doublewrite File中。这个过程是由后台线程完成的,以确保数据的持久性。
- 实际数据写入: 一旦Doublewrite File中的数据被确认已经写入磁盘,MySQL就可以将这些数据写入实际的数据文件中。
- 恢复机制: 如果在写操作过程中发生故障,MySQL可以从Doublewrite File中恢复数据。由于Doublewrite File中的数据是完整的,因此可以用来修复损坏的数据文件,确保数据的完整性和一致性。
3️⃣为什么需要Doublewrite Buffer
从MySQL页(Page)和Linux页大小不同的角度来看,需要Doublewrite Buffer的原因主要是为了解决数据写入过程中的一致性和完整性问题。
首先,我们需要了解MySQL的页和Linux的页大小不同。MySQL的页通常大小为16KB,而Linux的页大小可能因系统配置而有所不同,但常见的默认大小是4KB。这意味着,当MySQL写入一个页的数据时,实际上是写入了一个更大的块,这个块可能跨越了多个Linux页。
现在,考虑以下场景:
假设MySQL正在写入一个页的数据,并且这个操作只完成了部分,比如只写入了50%的数据。在这种情况下,如果直接将这个不完整的数据页写入数据文件,那么数据文件就会处于一个不一致的状态。某些查询可能会读取到这个不完整的数据页,导致数据损坏或不一致。
为了解决这个问题,Doublewrite Buffer被引入。当MySQL写入一个数据页时,首先会将整个页写入Doublewrite Buffer。这样,即使写操作只完成了部分,Doublewrite Buffer中的数据仍然是完整的。然后,Doublewrite Buffer中的数据再被同步(flush)到实际的数据文件中。这样,即使发生故障,也可以从Doublewrite Buffer中恢复数据,确保数据的完整性和一致性。
综上所述,Doublewrite Buffer的存在是为了解决由于MySQL页和Linux页大小不同导致的数据写入过程中的一致性和完整性问题。通过将数据先写入Doublewrite Buffer,然后再同步到实际的数据文件,可以确保数据的完整性和一致性,避免因故障导致的数据损坏或不一致问题。文章来源:https://www.toymoban.com/news/detail-814977.html
4️⃣Doublewrite Buffer的参数
MySQL的双写缓冲区可以通过以下参数进行配置:文章来源地址https://www.toymoban.com/news/detail-814977.html
- innodb_doublewrite: 控制是否启用双写缓冲区的参数。可以设置为ON或OFF。默认为ON。
- innodb_doublewrite_file: 指定Doublewrite File的路径和文件名。默认值为ib_logfile0和ib_logfile1。
- innodb_doublewrite_buffer_size: 控制双写缓冲区大小的参数。默认值为256KB。可以根据需要进行调整,但不应设置得过大或过小,以免影响系统性能或导致不必要的内存占用。
到了这里,关于深入解析MySQL双写缓冲区(Doublewrite Buffer):原理及作用的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!